")
Introduction
In this article, we’ll present a new take on editors for domain-specific languages (DSLs), that combines features of traditional text editors and a more projectional approach: bridging the gap between textual and projectional editors.
We’ve already talked about this topic, once at the LangDev conference in 2022, and once during the Strumenta Community Virtual Meetup – the video of the latter talk is publicly available. The present article expands on those talks.
We’ll go over a recap of textual and projectional editors, and their differences, to lay out a map of the existing territory. Then, we’ll present our ideas to bridge the gap between the two and draw some conclusions.
While we usually include links to the accompanying code with a permissive license, this time we cannot do so because the results that we’ll present are early research work at Strumenta and are currently proprietary. Instead, we’ll focus on the high-level concepts rather than their implementation as code.
Text Editors
Let’s start with defining what a text editor is. Let’s keep in mind that we’re in the context of editing models, not any kind of document. In that context, by “text editor” we mean any library or application that presents and stores models as text. Examples include VSCode/Monaco, Emacs, Vim, and the editor in your favorite Integrated Development Environment (IDE).

In a text editor, the model could be code in a programming language, but also, for example, a piece of configuration, a SQL query, a Markdown document, a model in a domain-specific language – anything with a purely textual, formal representation.
Specifically, when we say text, we mean a linear sequence of characters. Actually, text editors present the model as a sequence of lines, possibly decorated e.g. with line numbers, markers and messages of various kinds, as illustrated in the image above. So, there is some difference between the presentation of the model and its internal, stored format.
Still, text editors store models as a flat sequence of characters, and most of the operations that they provide (such as moving the cursor, cutting and pasting, and so on) are based on characters.
These editors may provide more advanced operations, such as refactoring options (e.g. renaming a variable in every place where it’s used). To enable these features, the developers of the editor must program some “language intelligence” into it – an understanding of the language in which the model is written. And, to obtain such intelligence, the editor must use a parser; this is a component that analyzes the text and builds a rich model out of it, a tree, or a graph, known as an Abstract Syntax Tree (AST).
Strengths and Limitations of Text Editors
Text editors are a technology that we’re very familiar with; both as users and as developers of these kinds of editors. We have mature libraries for building them and established applications that we can extend. We have well-known algorithms and ample literature on how to write text editors, and code editors in particular. We also have good parser generators such as ANTLR and libraries to build models that are easy to navigate and transform.
Surely a good part of the success of text editors is due to the fact that text is very versatile. Even without specific support, it is possible, even if probably not comfortable, to read and edit any model encoded as text. It’s also possible to apply generic text-based tools, such as grep (regular expression search) and sed (advanced search and replace). These tools don’t understand the syntax of the model, and thus cannot be as accurate and easy to use as an IDE’s “find references” and refactoring commands. Nevertheless, they can offer good results when more sophisticated alternatives are not available.
On the other hand, relying on text also has quite some limitations. Developers have devised syntaxes to express many different concepts as text. However, the need to encode information as text limits expressiveness. For example, it’s awkward to represent a table as text, and it’s especially hard to edit it. For some uses, though, tabular notation is ideal; for example, certain procedures are best explained with a decision table. Or, imagine encoding a graph as text. At best, it stops being practical once the graph grows bigger than a handful of nodes.
There are other drawbacks besides limited expressiveness. While we can use a parser to build a model that is easier to traverse and manipulate than text, parsing has a cost. Advanced IDEs offer powerful analysis and refactoring tools, but they consume quite a lot of resources to build and maintain their internal models from the source text.
Not just that; even the best parser will sometimes break on malformed code. Surely we’ve experienced a situation where our IDE has gotten confused, maybe after we pasted a good chunk of text. Inevitably, when writing in a text editor, our code is frequently malformed. That’s because we can only insert bits of text – single characters, or pasted snippets – that most often aren’t well-formed code. Even if when we stop typing the code will be perfectly valid, in the interim, it’s often not. Also, not every syntax is equally well-suited for analysis while typing. This is an issue especially with legacy languages, that weren’t designed with advanced IDEs in mind.
Finally, a textual editor can be a bit hard for novices to approach because it’s so free-form that it gives little guidance. You get a blank page, where you have to type something, and nothing tells you where to start. Of course, that’s mitigated by tutorials, online documentation, IDE wizards, and code generators that can automatically set up the skeleton of a code project from some initial description. But still, in a text editor we have limited room for guiding novices – and in general for interactivity.
Projectional Editors
On the other side, we have projectional editors, also sometimes called structural editors. The most famous example is Jetbrains MPS, but we also have Freon (was ProjectIt) and others.
These editors store the model as structured data (e.g. as XML, JSON, or proprietary formats). Then, they present a projection of the model to users. So, when using a projectional editor, we don’t see the raw structure of the model (e.g. XML nodes with attributes and children); rather, we may edit a diagram, or a table, but often just a textual document resembling code or prose. Some editors actually go to great lengths to ensure that the experience is as close to editing text as possible when the projection is mostly textual.
However, no matter how text-like a projectional editor is made to be, the underlying paradigm is very different from a text editor. In fact, projectional editors don’t use parsers and cannot edit “generic” code they can’t understand. Every element on the screen – a word, a phrase, an icon, a table cell, … – matches an element in the model, or is a synthesis of several elements. There’s no parsing phase that reconstructs the model from the source code every time the user modifies it. The model is the source, and the editor is a tool to view and edit it.
As a consequence, projectional editors are able to provide operations that don’t work on sequences of characters, but rather modify the structure of the model directly. For example, replacing a node with another, where a node could be anything from a single expression to a whole function body or query clause. Visually, that node may correspond to a block of text, or to a row in a table, or a box in a diagram.
Strengths and Limitations of Projectional Editors
So, projectional editors allow greater expressiveness because they’re not constrained by the limitations of text and parsers, and greater opportunities for interactivity because the available operations are not limited to text manipulation. Often they also allow combining different syntaxes together, so for example we could embed diagrams or tables, or other kinds of domain-specific representations, into a more straightforward textual syntax.
Also, the problem of having to work on a potentially broken model while the user is editing is vastly mitigated in projectional editors. It’s not completely eliminated; in part because to construct a valid model we may have to pass through an incomplete model, in part because parsing is a bit like email – something that likes to creep into any kind of software application. There will be maybe micro expressions or small pieces of text that are still easier to parse than to model as a projection. For example, we may prefer to treat a date, or a very simple arithmetic expression, as text, even if it would perhaps be more conceptually correct to represent it as a composite object. However, most of the time, no parsing is involved in editing a projection.
Furthermore, a more interactive experience means that we can also offer more guidance to novices. Common approaches include having a new editor start from some pre-populated nodes, rather than a blank page; and offering a simplified view of the model, that hides some of the complexity. Users may then toggle it to “expert mode” when they’re confident enough. It’s also easier to display contextual help, not limited to the inline documentation hovering over some code elements in popular IDEs. So, we can say that projectional editors in some aspects could be easier to learn.
With all of that in mind, of course, there are also drawbacks to projectional editors. For example, they’re unfamiliar. These kinds of editors have been in existence for quite a long time, and there’s literature on them. However, outside academia and specialized niches, projectional editors are still pretty much unknown, and for many users, the learning curve could be quite steep, especially if we didn’t spend many resources on improving the learning experience as we’ve mentioned before. Text is simple, in part because of its characteristics, and in part, because we’re so well accustomed to working with text. It’s considered an essential aspect of using computers, that we learn early on.
Not just that, projectional editors are unfamiliar to us developers, too, should we want to build one. Not “us” at Strumenta of course, because we’re specialized in that, but the average developer will probably find it easier to build a VSCode extension than an MPS language. For example, the libraries and tools that we have at our disposal are still somewhat less mature than what we have for text. Often for these editors, MPS included, the text editing experience out of the box is not great; we’ve got to do some development work to bring it more or less on par with the standard experience of a text editor. Without any development effort, an editor made with MPS won’t allow you to insert anything just by typing; instead, it will require that the user chooses what to insert from a menu. Only after having inserted a node, MPS will allow us to “fill in the blanks” by typing, for example, to give a name to our new class, function, or database table.
Finally, although work is being done in that area, the most well-established projectional editors are only available as heavyweight desktop applications. While this is hardly an issue when users are developers, it hinders adoption among other professionals. Users who aren’t developers but that would otherwise benefit from domain-specific languages and tools that allow them to represent their knowledge, and allow software to understand and act upon that knowledge. These users may find a desktop IDE or language workbench too intimidating, while a lightweight web-based editor would be more accessible.
Bridging the Gap
Can we somehow find a middle ground between textual and projectional editors? Is there a solution that has all the pros and none of the cons? Well, that’s impossible, probably. Still, maybe we can bring some features from projectional editors together with some from text editors and obtain a new kind of tool that is better than the alternatives in some aspects.
We want an editor that:
- is more expressive than plain text, i.e., it allows us to insert notations that are not easy to represent with text;
- provides a nice editing experience out of the box, so that novice users can just start typing without learning too much;
- is based on mature libraries and tools;
- is ready for deployment on the web.
Well, maybe we can have such an editor. Read on.
Word Processors
At some point, we came up with the idea to take a word processor and improve it in some way, to get closer to that sweet spot. That may sound strange. We know word processors as tools that we may use to write many different kinds of documents, but certainly not code or structured data. Actually, it’s one of the facts that we learn early on as computer users, that you write some stuff in Word and other stuff in Notepad, and they’re not the same thing.
However, crucially, word processors are already a sort of projectional editors. When you use Word or Google Docs, even though it appears that you’re writing plain text most of the time, you’re actually editing a rich document model, that is both stored as structured data and also somewhat presented as structured data. Think about the DOM of a web page.
This model consists of paragraphs, tables, images, and other elements. And the operations that we can do on such a model are not limited to text manipulation; for example, we can indent a whole paragraph or change the bullet style of a list, or even cut and paste a slice of a table. Also, as anyone who tried opening Word documents in OpenOffice Writer or Pages will know, word processors don’t store documents as text, either. These days, they read and write compressed XML, mostly; in the past, it was proprietary binary formats.
Now, of course, the limitation of a word processor is that the metamodel, or the “schema” of the document, is fixed. It’s only meant to represent “rich text” documents, not other structures. Potentially, it may have a few extension points. For example, in Word, you can enter mathematical formulas, or insert other kinds of external objects. But usually, from the point of view of the editor, these are black boxes. They’re like images; you double-click on a formula, and another window opens, so you can edit it with a dedicated interface. When you close it, the editor updates with a new image. It’s not really an integrated experience. However, we can improve on that.
ProseMirror
After some research, we identified a promising project that could work for our use cases. It’s called ProseMirror and it’s a toolkit for building web-based word processors. So it’s not a prebuilt editor component, it’s a set of modules that work well together. Of course, it comes with built-in features that we can reuse as-is or adapt, such as copy-paste, keyboard shortcuts, undo/redo, etc. Even if it’s not a finished editor, and requires some setup, the text editing experience out of the box is ok.
Some other key features of ProseMirror include:
- it’s open-source and has a vibrant, helpful community
- it’s built to be extensible
- it has a transactional design, which for example makes it relatively easy to integrate collaborative editing
- while it focuses just on the editor, and by itself it doesn’t come with a full UI with, for example, a menu bar, it’s been integrated into all sorts of component libraries and frameworks, commercial and open-source.
Also, crucially for our goals, ProseMirror has a free schema. That is, it doesn’t come with a fixed metamodel of the structure of the documents. We can define our own blocks and nesting rules, either starting from scratch or extending a predefined schema.
Thus, we can combine standard rich-text blocks with other kinds of structured blocks. Those will be well integrated into the same editor, unlike what happens in Word or Google Docs. That is, we can define how our new blocks are presented and we can define how they interact with the rest of the editor. That’s the “projectional” aspect of our editor in a nutshell. Also, as we’ll see, we can incorporate parsing in some of these blocks, so as to have potentially a mix of rich-text, projectional, and traditionally parsed code – all in the same document, with the same editor.
Our Experiment in Action
Let’s look at some of our work, in pictures, since we cannot share the code.

Here we can see an instance of the editor. It may look underwhelming if you expect a full word processor like Google Docs, because we can only see very few controls here. But this is on purpose. The ProseMirror toolkit only deals with the contents of the editor. Then, it’s up to the developer to build the UI around it – menus, a toolbar, and everything else. So, to keep things simple for demos, we only built a very limited editor experience, just to show some rich text that we can style as bold and italic. We also chose to color the free-form text using CSS, to distinguish it from more structured code sections that we’ll insert later.
Under the editor we show the underlying document model as JSON:

So we can already see that even though it looks like we’re editing simple text, actually we’re acting upon a structured model. The structure of this model is defined by the metamodel, which we can also see as JSON. We’ll delve deeper into the topic in the following sections.
Introducing Code Blocks
Now, let’s look at some of the “magic” that we’ve added. After the rich-text block, we have placed a special block. That’s a “parsed text” block that we defined on top of the basic ProseMirror schema. Any text we write there is passed through an ANTLR-based parser. In particular, we chose to integrate a Kotlin parser that we generated from the official open-source Kotlin grammar.
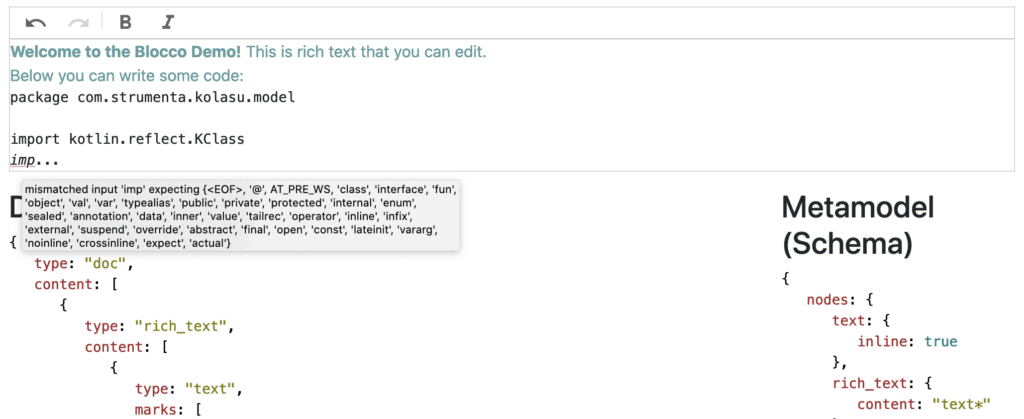
As we can see, we report parse errors directly in the editor, to showcase the integration. Now, of course, this is not a full code editor; it’s a very simplified proof of concept. The idea here is to show that we can mix rich text with something that is already a little more structured.
Of course, a parser’s output isn’t just a list of errors. Indeed, the main result of parsing is a parse tree – a tree representation of the grammatical structure of the code. We can see that, in our editor, we seamlessly integrated the parse tree into the document model:

Thanks to ProseMirror, we get features like undo and redo, that work with our custom block from the start. We even get primitive copy-and-paste out of the box – however, everything becomes plain text when pasted. To have a more integrated copy-paste implementation, so that, for example, pasting “code” in the middle of a text block will split the text and insert a code block, we’ll need more work. We won’t be doing that for the time being, but the possibility is there.
Going Projectional
So far, we’ve shown how to mix rich text editing with light “code” editing – where code is plain text and we use a parser to reason about its structure. We can see both these aspects as “projections” of the underlying document model, but that’s not exactly what we mean by a projectional editor. In fact, even though we store the model as structured data, we can only edit the document as text. In other words, the only editing we can do is by means of string manipulation operations, like adding a character (typing), inserting a substring (pasting), etc.
Such an approach, if properly developed, can address interesting use cases, for example, editing code and documentation together. However, we want to go a step further and introduce a new block to our editor that is more clearly projectional. That is, we want to have editable fields in the middle of other content that is not editable as text.
Let’s see this in action so it will hopefully be clearer. Let’s say that we want a block to represent a Kotlin class. So, instead of writing the text “class” followed by a space, the class name, braces, and all the syntax that Kotlin requires, we’ll just press Ctrl+Space:
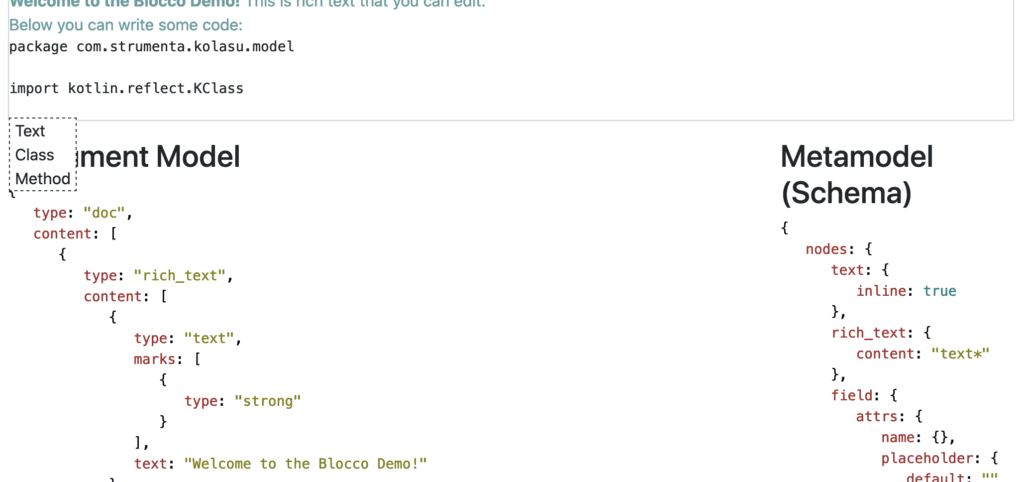
Let’s select “class” from the context menu; that will insert a “Kotlin class” block:
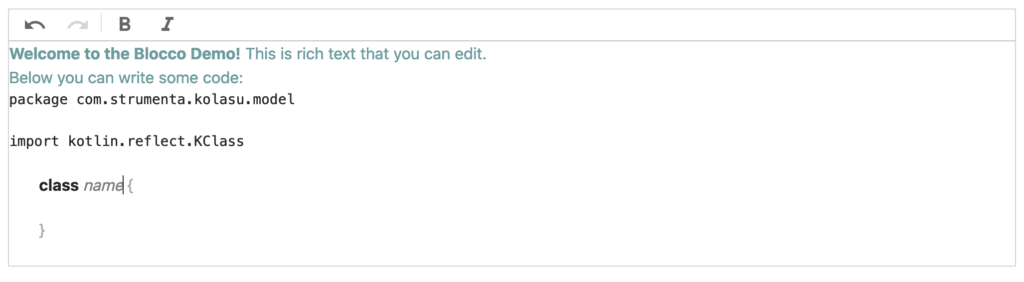
This is an excerpt of the underlying model:
{
type: "block",
attrs: {
kind: "class"
},
content: [
{
type: "line",
content: [
{
type: "keyword",
attrs: {
keyword: "class "
}
},
{
type: "field",
attrs: {
name: "name",
placeholder: "name"
…
So, this is a kind of block that has some fixed portions – such as keywords and punctuation – that we cannot edit as text, and some fields that we can write into, such as the name of the class in the example. From ProseMirror we also inherit operations on whole blocks, such as selection:
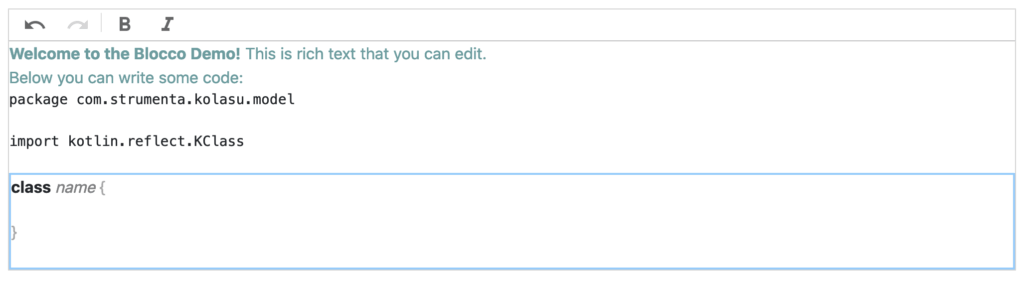
In the picture, the entire class block has been selected. You can do that in ProseMirror for any block by clicking on it while holding down the Ctrl key (or Cmd key on OSX). In addition, we set up projectional blocks so that, when the user clicks on a non-editable element (such as the keyword “class” in the example), the entire block is selected. Once a block is selected, we can for example delete it by pressing the backspace key, or move it around by clicking and dragging with the mouse.
As with parsed text blocks, a lot of work is needed to make these projectional blocks usable in a real-world editor. However, the basic idea is hopefully evident enough.
Mixing and Matching
So far we’ve seen a class block and how we can change the class name by typing in a field. However, the most interesting part of a class are its contents, such as properties and methods. Let’s see what we can offer to edit the body of a class.
One alternative is to insert another parsed block:
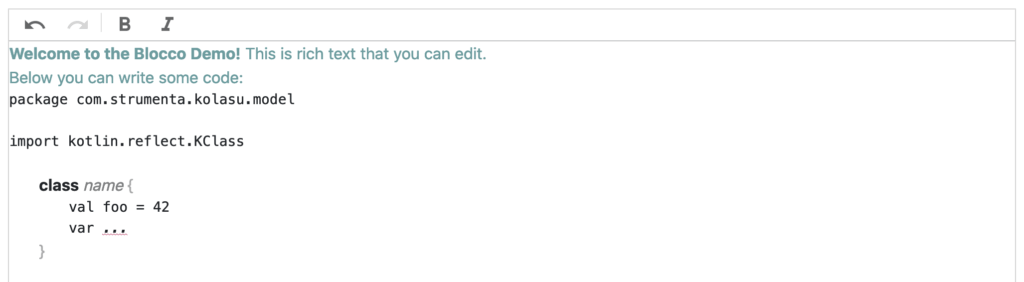
Then, we’ll edit the body of the class as text, but the model will contain a tree structure for it, as we’ve seen before.
The interesting thing about this approach is that the parsed block is now constrained to recognize only the elements that can actually be in the body of a class. So this is a viable path if we have a textual language with a parser, and we want to gradually build a projectional editor for it.
Another alternative is to create projectional blocks for the elements in the class body. Here we can see a projectional block representing a method declaration, that in Kotlin is introduced with the fun keyword:
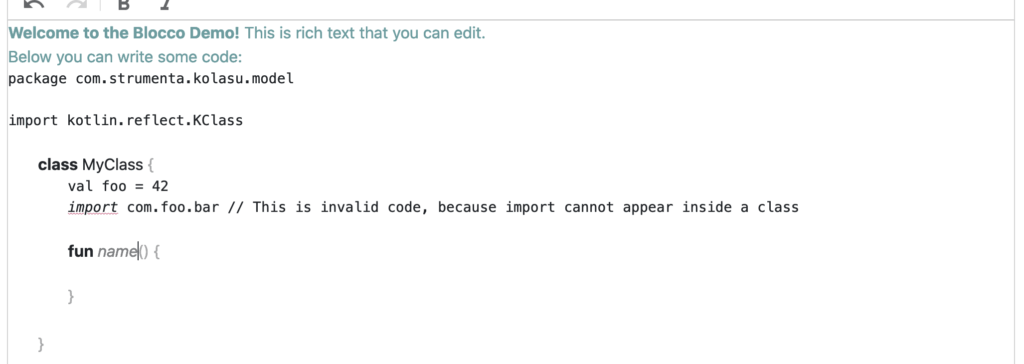
In the end, we can decide where it’s convenient to use projectional editing, and where it’s more convenient to use a parser-based approach. For example, editing mathematical expressions in many projectional editors is awkward; even in an advanced tool like MPS, a lot of customization is required to allow users to just type in the expression (and edit it afterwards). In those cases, it may be preferable to stick to a text editor with a parser. That provides a nicer editing experience out of the box, and since the language of arithmetic expressions is much more constrained than a full programming language, the drawbacks of a parser-based approach are usually greatly mitigated.
Conclusions
We’ve shown a very early research prototype that combines aspects of traditional text editors and projectional (or structural) editors, based on the ProseMirror editor toolkit. Hopefully, this article will spark a conversation on the approach we’ve taken. Also, if you’re interested in developing the concept further and applying it to your use case, please contact us. We’re also experts in traditional code editors such as Monaco and Visual Studio Code, as well as DSLs with MPS and other technologies.

")