
Code is arguably the most valuable asset for many organizations.
However the value trapped in the code is not easy to use.
Why?
In this article we are going to see how we can extract and process knowledge in code by specifying patterns. We will see:
- A clear example of what we mean by extracting knowledge from code
- An explanation on how to implement this approach in practice (with code available on GitHub)
- We will discuss why do we want to extract knowledge from code.
What do you mean? Show it to me
Let’s see what we mean in practice, with the simplest example we can come up with. And let’s see it working for real, on real code.
Of course recognizing properties is a very simple example, something we are all familiar with, but the same idea can be applied to more complex patterns.
There are many patterns that can be used:
- patterns typical of a language: think about the for loops to iterate over collections
- design patterns: singleton, observer, delegate to name just a few
- patterns related to frameworks: think about all the applications based on MVC or the DAO defined to access database tables
- project specific patterns: for example in JavaParser we use the same structure for the tens of AST classes we defined
Patterns can be regarding small pieces of a single method or the organization of entire applications.
Patterns can also be applied incrementally: we can start recognizing smaller patterns, making the application simpler and then recognize more complex patterns over the simplified application.
How knowledge end up being trapped in code
Developers use a lot of idiomatic small patterns when writing programs. Experienced developers apply them automatically while implementing their solutions. Slowly they build these large applications that contain a lot of knowledge, enshrined in the code.
The problem is that the initial idea is not stated explicitely in the code. The developer translates it into code by using some of the idiomatic patterns typical of the language, or linked to the framework is using, or specific to its organization.
Somewhere a developer is thinking: “this kind of entity has this property” and he is translating it to a field declaration, to a getter and a setter, to a new parameter in a constructor, to some additional lines in the equals and the hashCode methods. The idea of the property is not present explicitly in the code: you can see it if you are familiar with the programming language but it requires some work.
There is so much noise, so many technical details that shadow the intention
But this is not true just for Java or for the properties: when a developer determines that an object is unique he could decide to implement a singleton, and again this means following certain steps. Or maybe he is deciding to implement a view or a Data Access Object (DAO) or any other typical component required by the framework he is using. In any case all the knowledge he had in mind is scattered in the code, difficult to retrieve.
Why is this bad?
For two reasons:
- it is difficult to see the knowledge.
- it is difficult to reuse that knowledge.
What it means that is difficult to see the knowledge in the code?
A lot of work go into understanding a problem and build a representation of the solution in the code. There are a lot of micro-decision, a lot of learning involved in the process. Then all of this effort lead to knowledge.
Where does this knowledge go?
This knowledge is typically not written down directly, it is instead represented in code. The fact is that in many occasions this knowledge is translated in a mechanical way into code. Therefore this translation can be reversed. The problem is that to see the knowledge that is present in the code you need to look directly at the code, read it carefully and mentally deduct the knowledge that is present there.
To understand things:
- we need to understand programming and the typical patterns we use
- requires work to check the details
- this process is done mentally, the result is just in our head and cannot be processed automatically
If the knowledge was represented directly, to an higher level of abstraction it could be easier to check it and it could be accessible to more persons.
What it means that is difficult to reuse the knowledge in the code?
We have seen that basically the only way we have to extract knowledge from code is reading it and understanding it. The results stay just in our head, so they are not usable by a machine. If we had instead a representation of the abstract knowledge, the original intentions, we could elaborate them for different goals.
We could for example use that knowledge to generate diagrams or reports.
Do you want to know how many views have been written? How many tables do we have in the database? Easy! Project managers could get their answer without having to ask. And they would get always the updated, honest answers on the state of the code.
We could also use that information for re-engineering even partially applications. Some aspects of your application could be migrated to a different version of a library, to a different framework or even a different language. It would not mean that complex migration could be performed completely automatically but it could be a start.
Implementation using the Whole Platform
Ok, we have talked about the problem, let’s now talk about a solution we can build today.
We are previously discussed how to build grammars using the whole platform and we have seen it also when looking into Domain Specific Languages.
The code is available on GitHub, courtesy of Riccardo Solmi, the author of the Whole Platform.
1) Defining the higher level concepts
First of all we need to define the higher level concepts, that we have in mind but are not expressed explicitely in the code. For example, the concept of property of a Java bean.
In the model-driven parlance we define the metamodel: i.e., the structure of those concepts.
2) Define how to recognize such concepts in Java code
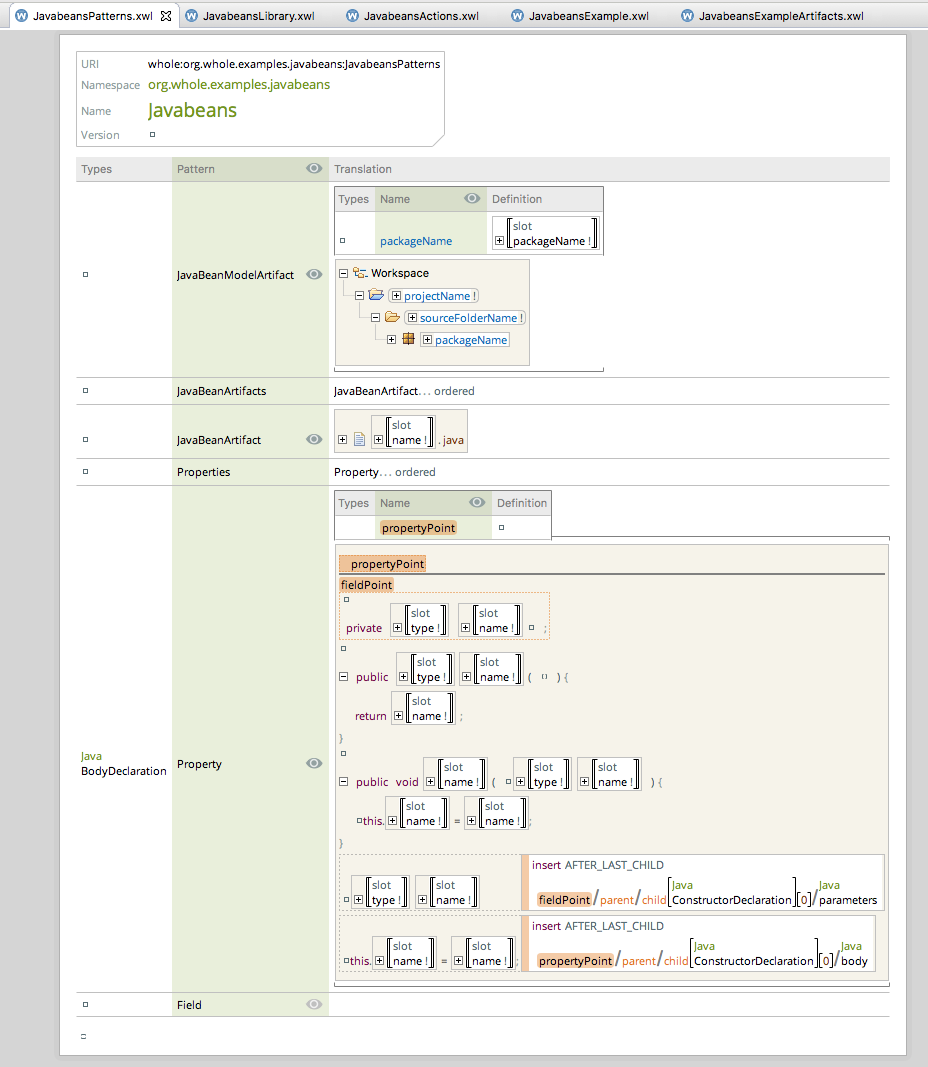
Once we have those concepts defined we need to specify how to identify those in the code. The whole platform use a Domain Specific Language to specify patterns. It looks like this:
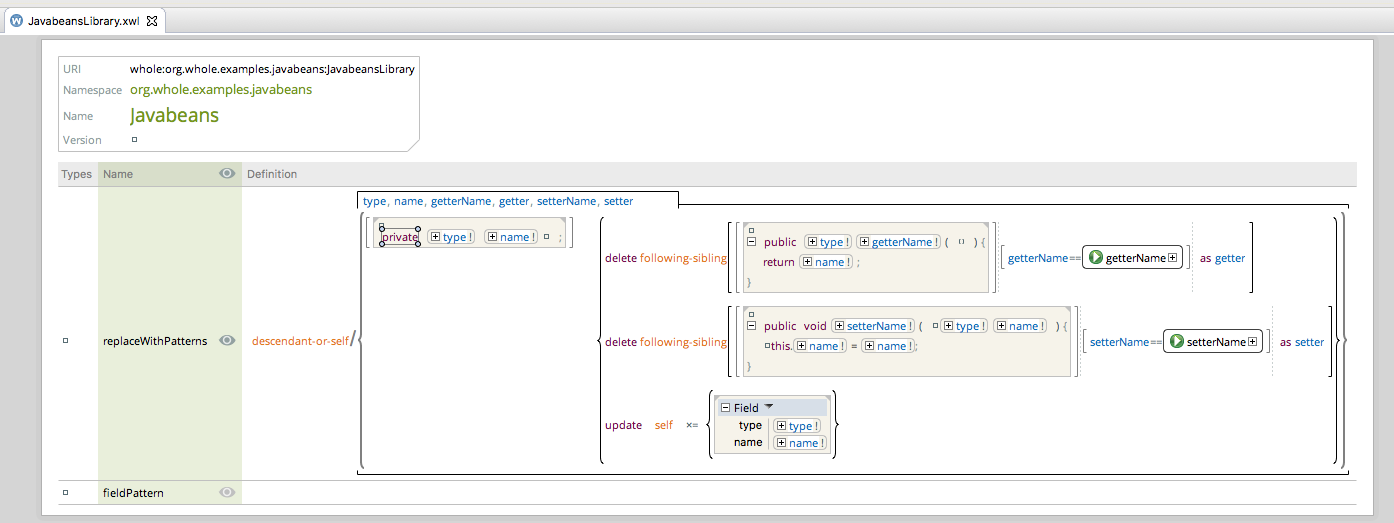
What are we saying here?
We are saying that a certain pattern should be looked into the selected node and all the descendants. The pattern should match the given snippet: a Field Declaration with the private modifier, associating the label type to the type of the field and the label name to the name of the field.
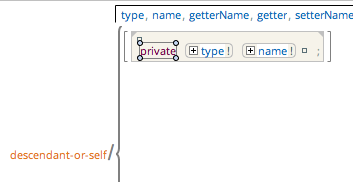
What should happen when we recognize this pattern?
We should:
- Remove the corresponding getter. We will match a method with the expected name (calculated by the getterName function), the expected type, taking no parameters and returning a field with the expected name
- Remove the corresponding setter. It should be a method returning void, with the expected name, the expected parameter and assigning the parameter to the field with the expected name
- It should replace the Java field with this higher level concept representing the whole property (here it is named Field but Property would have been a better name)
Now, what we need to do is just to add this action into the contextual menu, under the group name Refactor. We can do that in Whole by defining actions.
Voila! We have now the magic power of recognizing patterns in any piece of Java code. As easy as that.
3) Doing the opposite: expand the concepts
So far we have discussed how to recognize patterns in code and map them to higher level concepts.
However we can also do the opposite: we can expand higher level concepts into the corresponding code. In the whole platform we can do this with this code:
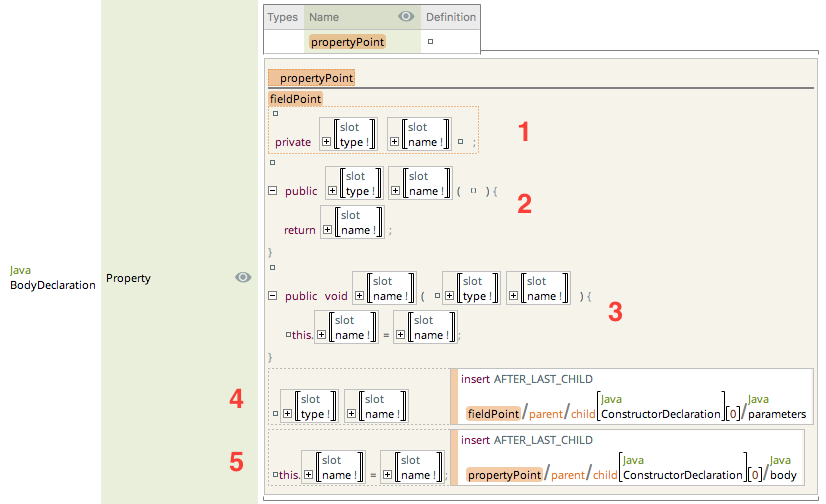
Let’s focus exclusively on the property definition. Each instance is expanded by:
- Adding a field declaration
- Adding a getter
- Adding a setter
- Adding a parameter to the first constructor
- Adding an assignment in the first constructor. The assignment take the value of the parameter added and assign it to the corresponding field
Now, the way we recognize the pattern and the way we reverse it is not 100% matching in this example, bear with us over this little discrepancy. We just wanted to show you two different ways to look at properties in Java.
What this approach could be used for
We see this approach being useful for three goals:
- Running queries to answer specific questions on code
- Understanding applications
- Transforming or re-engineering applications
Queries
We could define patterns for all sort of things. For example, patterns could be defined to recognize views defined in our code. We could imagine to run queries to identify patterns. Those queries could be used by project managers or other stakeholders involved in the project to examine the progress of the project itself.
They could also be used by developers to navigate into the code and familiarize with complex codebases. Do we need to identify all observers or all singletons in this legacy codebase? Just run a query!
Understanding applications
The fact is that programming languages tend to be very low level and very detailed. The amount of boiler plate code varies between languages, sure, but it is always there.
Now, one of the problem is that the amount of code could hide things and make them difficult to notice. Imagine reading ten Java beans in a row. Among them there is one that implements the equals method slightly differently from what you expect, like for some reason it ignores one field or compare one field using identity instead of equality. This is a detail that has a meaning but that you would very probably miss as you look at code.
Why is that?
This happens because after looking at a large amount of code and expecting to see certain patterns you become blind to those patterns. You stop reading them without even noticing it.
By recognizing patterns automatically (and precisely) we can represent higher level concepts and easily spot things that do not fit in common patterns, like slight differences in equals methods.
We have seen how to recognize bean properties, but we can go further and recognize whole beans. Consider this example.

This shows the relevant information ony. All the redundant information is gone. This makes things obvious.
We can recognize incresingly complex patterns by proceeding incrementally. In this way exceptions pop up and do not remain unnoticed.
Transforming applications
When we write code we translate some higher level ideas into code, following an approach that depends on the technology we have chosen. Over time the best technology could change even if the idea stay the same. We still want the same views but maybe the way to define them is changed in the new version of our web framework. Maybe we still want to use singletons but we decided is better to use public static methods with lazy initialization to provide the instance, instead of using a public static field.
By identifying higher level concepts we could decide to translate them differently, generating different code. This process is called re-engineering and we can perform it automatically to some extent. It seems a good idea to me and it is another advantage of using patterns to identifying higher level concepts.
Summary
Code has an incredible value for organizations because it captures a lot of knowledge in a form that is executable. As we evolve our applications and we cover more corner cases we improve our knowledge and our code. After years of developing a code base it becomes often invaluable for the organization owning it. However that value is like frozen: there is not much we can do with it. It is even difficult to understand exactly how much information there is in the code.
We think that one approach to extract knowledge from the code is proceeding bottom up: recognizing the small abstractions and composing over them, step by step, until we recognize larger structures and patterns and can represent easily the big picture hidden in our application.
Using the Whole Platform is invaluable for these experiments.
This article has been written following a visit of Riccardo Solmi, the author of the Whole Platform. I would like to thank him for building this great product, for sharing ideas and writing the code used in this article. The code used in this article is available on GitHub.
