
The code for this tutorial is on GitHub: parsing-sql
SQL is a language to handle data in a relational database. If you worked with data you have probably worked with SQL. In this article we will talk about parsing SQL.
It is in the same league of HTML: maybe you never learned it formally but you kind of know how to use it. That is great because if you know SQL, you know how to handle data. However, it has limitations and when you hit them your only course of action might be to work with a traditional programming language. This does not necessarily mean migrating away from SQL. You might need to move from one SQL dialect to another one or to analyze the SQL code you use. And to do that, you need to parse SQL, and that is what this article is about.
What are the limits of SQL? After a while you learn of a couple of issues:
- there is not one SQL, but many variations of it. The SQLs implemented in SQLite, MySQL, PostgreSQL, etc. are all a bit different
- you cannot do everything related to data in SQL. In some cases, you need a traditional programming language to work with the data
These issues became real problems when you need to make big changes. For instance, if you need to change the database used by a large application. It can also be a problem when you need to make transformations that SQL and your database cannot handle. In that case, you have some transformations done in SQL (and run on the database) and some others in your source code. So you spend a lot of time working on glue code and around the limitations of SQL.
SQL can also be a constraint, simply for what it lacks: unit testing integrated with your source code and all the other tools that you can use with Java, C#, etc. SQL is an old language and not designed for large scale programming. Some can argue about that and in fact some people on Hacker News do that. However we can all agree that it is not a language that developers will love. Even worse, they will not be very productive with it. And what happens if your application requires you to verify that something gets executed in a certain way, or to offer some guarantees? It can be a business need or a regulatory requirement. Then you need to parse SQL or to find a way to move from SQL world to your programming language world.
That is what this article is about: parsing SQL. We are going to see ready-to-use libraries and tools to parse SQL, and an example project in which we will build our own SQL parser.
What is SQL
SQL (Structured Query Language) is a domain-specific language designed to handle data in relational database. It is a declarative language, so you describe what you want to achieve (e.g., get me a row of data with id=5) and not how to achieve it (e.g. loop through the rows until id=5). It has a formal mathematical foundation in relational algebra and calculus. The language is an ISO/IEC standard that is periodically updated, the latest version is SQL2016. This means that there is a very formal and clear description of the language if you need it.
SQL is designed to handle many aspects of the life cycle of working with data: yes, you can query data, but you can also create the format of data (i.e., the schema of a table) and regulate access control to the data.
SQL Procedural Extensions
Actual SQL implementations come with procedural extensions that implement some form of procedural programming. These extensions are even more varied from database engine to database engine. They were added to perform complex elaborations on the data directly on the database, so they can be as powerful as traditional programming languages. And this can also be an additional headache if you try to parse SQL. See, for instance, this is a PL/SQL (the procedural SQL from Oracle databases) example from Wikipedia.
DECLARE
var NUMBER;
BEGIN
/*N.B. for loop variables in pl/sql are new declarations, with scope only inside the loop */
FOR var IN 0 .. 10 LOOP
DBMS_OUTPUT.PUT_LINE(var);
END LOOP;
IF (var IS NULL) THEN
DBMS_OUTPUT.PUT_LINE('var is null');
ELSE
DBMS_OUTPUT.PUT_LINE('var is not null');
END IF;
END;
Resources
As we have seen, handling SQL can be a daunting task, so let’s see a few resources to help you. They range from grammars to kick start your parsing efforts, to ready-to-use tools.
Knowledge
Official Sources
The latest official SQL standard is formally known as ISO/IEC 9075 SQL:2016. You can find every information you need about it in the official sources either the ISO or IEC websites. However, keep in mind that there are several documents describing the standard and you have to pay for each of them. This means, depending on the exchange rate, the total cost could be more than 2,000 USD. This cost it is an obstacle for individual developers, but you certainly do not need to read the formal specification for casual use.
Official References from Database Documentation
Other than the official SQL standard, you can look up the official documentation of the database producers, which contains a reference for their SQL implementation. Here is a list of the few major ones:
- Oracle PL/SQL Documentation
- MySQL 8 SQL Reference
- Microsoft Transact-SQL Reference
- PostgreSQL 12 SQL Language
- IBM DB2 SQL
- SQL as understood by SQLite
Grammars
There are a few (usually partial) grammars available in different formats. They can be a good starting point for getting where you need.
- BNF Grammars for SQL-92, SQL-99 and SQL-2003
- Partial Teradata SQL grammar for ANTLR4
- The ANTLR v4 Grammars repository contains grammars for MySQL, PL/SQL, T-SQL and SQLite. In our ANTLR Course we analyze the SQLite grammar to explain its structure and how you can parse a declarative language like SQL.
Libraries
There are many libraries to parse SQL in different languages. Some support different databases and different programming languages. Here it is a list of the most used ones. Unless otherwise noted, the libraries are released under an opensource license.
Official parsers
Some companies that develop a database also offer an official parser. In some cases they expose the parser internally used by the database engine itself. This is a great thing, because you are going to get excellent support and the same behavior as the official database in which the SQL will be run. So, if you are interested just in one specific SQL dialect, this is the first place to start looking for. They might not be ideal if you need to parse more than one SQL, exactly because they are so optimized for one platform. So they may use structure and classes that are very specific and cannot readily be used together.
Two examples are:
- libpg_query is not actually an official library by PostgreSQL, however it repackages the official source code of the server, so it is close enough. It is a C library, but it is used as a foundation for several parsers in other languages such as Python, Go, etc.
- Microsoft offers a TSQL Parser for its database as part of its Visual Studio tools. It does not seem to be well documented, but taking some time to understand how it works is certainly better than building your T-SQL parser from scratch
Multi-lingual and/or multi-databases
- General SQL Parser is a commercial library that supports many databases (DB2, Greenplum, Hana, Hive, Impala, Informix, MySQL, Netezza, Oracle, PostgreSQL, Redshift SQL Server, Sybase, and Teradata) and languages (C#, VB.NET, Java, C/C++, Delphi, VB). It can validate SQL syntax, format SQL and work with the parse tree
- JSqlParser parses an SQL statement and translates it into a hierarchy of Java classes. It is opensource, with a double LGPL and Apache license, and supports many databases: Oracle, SqlServer, MySQL, PostgreSQL, etc.
MySQL parsers
- Pingcap parser is a MySQL parser in Go.
- xwb1989/sqlparser is a MySQL parser for Go. This parser has been extracted from Vitess, a database clustering system for horizontal scaling of MySQL.
- PHP SQL Parser is a (mainly) MySQL (non-validating) parser written in PHP. It can parse other SQL dialects with some modifications. It fully supports parsing the most used SQL statements, but it just returns some information on other statements.
- The SQL Parser of phpmyadmin is a validating SQL lexer and parser with a focus on MySQL dialect. Given its use in PHPMyAdmin, it is certainly well tested.
- js-sql-parser is SQL (only select) parser for JavaScript that parses the MySQL 5.7 version of SQL into an AST.
SQLite Parsers
- sqlite-parser is a parser for SQLite v3 written in JavaScript that generates ASTs.
SQL Parsers
- sql-parser is a parser for SQL written in pure JavaScript. It is not maintained anymore and it only supports some SELECT queries, but it is probably better than starting from scratch if you need to use JavaScript.
- hyrise/sql-parser is a SQL parser for C++. It parses the given SQL query into C++ objects. It is developed together with Hyrise, an in-memory database, but it can be used on its own.
- andialbrecht/sqlparse is a non-validating SQL parser for Python. It provides support for parsing, splitting and formatting SQL statements.
- K2InformaticsGmbH/sqlparse is a production-ready SQL parser written in pure Erlang. It targets the Oracle PL/SQL dialect.
- sqlparser-rs is SQL parser written in Rust. It supports the SQL-92, plus some addition for MS-SQL, PostgreSQL, and SQL:2011. The developers say: if you are assessing whether this project will be suitable for your needs, you’ll likely need to experimentally verify whether it supports the subset of SQL that you need.
- moz-sql-parser is a peculiar SQL parser in Python written by Mozilla. The primary objective of this library is to convert some subset of SQL-92 queries to JSON-izable parse trees.
- queryparser is a parser written in Haskell for parsing and analysis of Vertica, Hive, and Presto SQL.
Tools
From SQL to a Programming Language or another SQL
- IO64 offers a tool to convert PL/SQL to Java. We have also seen this tool in our previous article Convert PL/SQL code to Java
- Ispirer is a company that provides a tool to perform database migration from different SQL dialects to another SQL dialect or a programming language: Ispirer MnMTK. We have seen it in our previous article Convert PL/SQL code to Java
- SQLines SQL Converter is an open-source tool to convert a SQL dialect to a different SQL dialect. It is written in C++ and implements its own SQL parser.
How Hard Could it be to Parse a Declarative Language?
Declarative languages tend to have simpler structures than your average programming language. For instance, you do not see many nested lambdas used inside declarative languages. A program in a declarative language is usually a long list of simple statements. The issue is that any single statement can be fairly complicated in some cases. And that is what happens in SQL.
Furthermore, there are actually several versions of SQL. This is true both in the sense that each database can implement it differently, and that there are many versions of the SQL standard because the language is evolving.
As an example, you are certainly familiar with a SELECT statement. In its basic format, like SELECT name FROM customers WHERE id = 1 it is quite easy to parse. However, the complete statement can be fairly complex. This image represents the SELECT statement as implemented in SQLite.
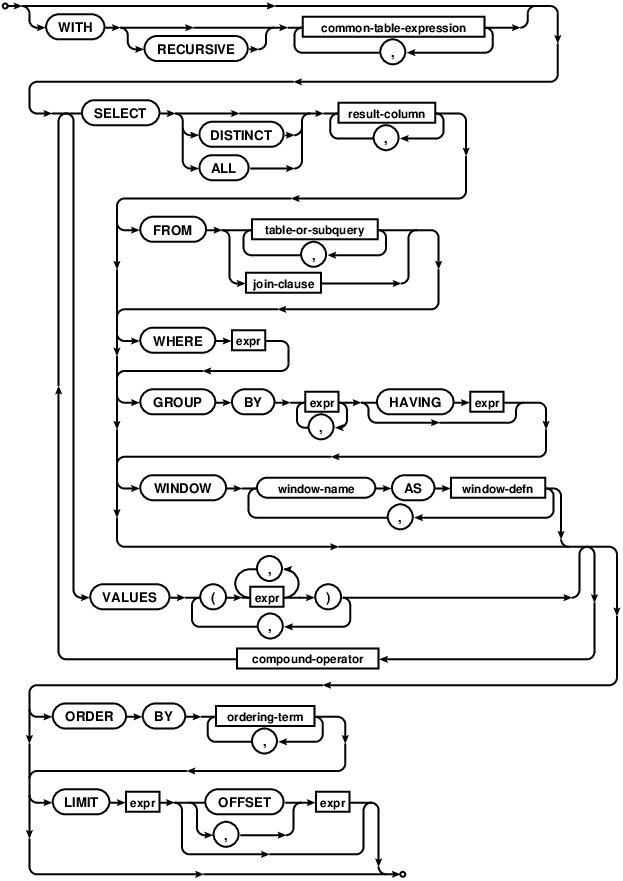
So, to implement support for parsing the general case will certainly take some time.
Try to Parse for Your Application
The reality is that to implement support for parsing the whole SQL requires a lot of effort, probably as much as parsing any average programming language. Even more so, if you need to parse many different SQL dialects. Then, if you need to parse SQL and cannot rely on a ready-to-use library, you should start with an analysis of your needs. You should try to understand first exactly what you need to parse and then try to parse in light of your application. This means both to parse just what you need and to structure the grammar in a way that makes your life easier.
For instance, if you just need to translate a series of SQL files just once, it may be acceptable to just ignore 40 complex statements. Maybe translating them manually would take less time than creating a large grammar to do it automatically. This does not work if you either have a lot of code or you need to do the translation repeatedly, not just once.
In this tutorial we are going to use this pragmatic approach: we are going to create a SQL grammar from scratch to parse just what we need and to ignore the rest.
This is just an example to show you this approach. There is not a standard common reason to parse SQL: you might want to parse SQL to migrate databases, for compliance reasons, to implement optimizations designed by your DBA in a bunch of old queries, etc. We think this pragmatic approach might serve you well for many specific parsing needs and this example is clear enough to be understandable by all.
Writing a (Very Partial) Grammar
In our example, we will parse a simple SQL file (an exported database) to generate classes that could represent that database. We are going to ignore everything else, even any exported data present in the file. That’s it. The advantage of dealing with SQL files is that we do not need to interact with a database. In fact, the database might not even exist anymore.
Designing a Partial Grammar
To do that we are going to start with a grammar. We are going to write a very simple one, but there are a couple of things to keep in mind:
- SQL is not case-sensitive, while ANTLR grammars by default are
- Our input (the SQL files) will contain some data that we do not care about. We still need to parse the file successfully while ignoring the extraneous input
These are notable issues that are specific to SQL and to our approach; probably they would not appear with other languages or if we wanted to create a complete grammar.
Before starting, just to give you an idea of what we have to deal with, this is a sample SQL file.
--
-- Table structure for table actor
--
--DROP TABLE actor;
CREATE TABLE actor (
actor_id numeric NOT NULL ,
first_name VARCHAR(45) NOT NULL,
last_name VARCHAR(45) NOT NULL,
last_update TIMESTAMP NOT NULL,
PRIMARY KEY (actor_id)
)
;
CREATE INDEX idx_actor_last_name ON actor(last_name)
;
CREATE TRIGGER actor_trigger_ai AFTER INSERT ON actor
BEGIN
UPDATE actor SET last_update = DATETIME('NOW') WHERE rowid = new.rowid;
END
;
As you can see at a first glance, we need to parse CREATE TABLE statements and ignore the other ones. We also need to ignore some parts of the CREATE TABLE statements, because they do not contain any information we care about for our task.
How to Ignore Stuff
The key to design a partial grammar is understanding how to ignore everything except for what we care about. This is not trivial because we have two conflicting needs: to ignore or drop most information and to keep all the necessary context to parse what we need. The more we ignore, the harder is to parse what we need. This is tricky particularly for lexing since the lexer has less information available to make a decision.
For instance, we cannot just say ignore anything until we find a CREATE token. That is because the lexer would still find the same tokens for the elements in row definition, like the ones for naming the columns (e.g. last_name) in INSERT statements or CREATE INDEX. One possible way to deal with this would be lexical modes. These are a way to include multiple sets of lexer rules and to switch between them. See our ANTLR Mega Tutorial, if you need to know more.
Essentially we would treat SQL as if it were a markup language: bits of structured information in a sea of free text that we could ignore. This could work in our case because SQL has a regular structure and we are just interested in CREATE TABLE statements. For regular structure, we mean that a SQL file is just a list of statements, each of them ends with a semicolon. So, we could just make a CREATE TABLE token to start the special lexical mode and use the semicolon to end the special lexical mode. However, it is not flexible, so it would be risky, in case we need to use our grammar for something else.
The Cognizant Way of Ignoring Stuff
Our preferred approach is more flexible, and can also be used for regular programming languages.
On the lexer side, we put as the last lexer rule this ANY rule.
ANY : . -> skip;
We skip every character, that was not already recognized by some previous token. Of course, while we do not show them here in the previous parts of the lexer we did define rules for the tokens we are interested in. You can see the whole lexer in the repository.
On the parser side, these would be our main rules.
statements : (statement | ignore)+ EOF
;
statement : createStmt
;
ignore : .*? SEMICOLON
| COMMENT
;
The main rule is statements, which captures both the stuff we care about and the stuff to ignore. This approach allows us to start using our grammar while we build it. For this example, we only need to parse CREATE TABLE statements, but you could slowly add support for parsing more statements with this structure.
We need the ignore rule to maintain an understanding of the structure of the SQL file. Without this rule, we would not be able to recognize and parse the statements we are interested in. The negative side-effect is that it will clutter our parse tree with ignore nodes. For instance, this is a graphical representation of a sample parse tree made with grun, the ANTLR testing utility.

Parsing Create Statements
We use a similar approach to parsing the CREATE TABLE statements.
createStmt : CREATE TABLE (IF NOT EXISTS)? tableName=name
LPAREN element (COMMA element)* RPAREN?
SEMICOLON
;
element : definition
| ignorable
;
ignorable : (PRIMARY? KEY | CONSTRAINT | SPECIAL_FEATURES | FULLTEXT) .*? (COMMA|RPAREN)
;
definition : name type defaultValue? nullability? attributes*;
The statement includes both definitions of columns, that we need, and settings for the table, that we could ignore. So, our element rule can accept both the definition for a row and the information about primary keys, constraints, etc. Later, in our code, we will simply ignore both the nodes ignore and ignorable.
The rules themselves are fairly easy to understand and should be obvious for everybody that has seen SQL. There is only a dirty trick that needs to be explained. You can see that the closing parenthesis (RPAREN) that should be at the end of the list of column definitions is optional. Technically this is not correct, it should always be there. However, we use this to fix an issue regarding the ignorable rule.
Getting Around the Need to Actually Parse Settings
The issue is that the ignorable rule is only a partial implementation of the parsing of these settings that you will find in a SQL file. In fact, this is the bare minimum necessary to parse correctly a bunch of sample SQL files we encountered. It is not a good design, but this is a very realistic implementation. Look at this example and see if you can spot our problem.
CREATE TABLE city ( city_id int NOT NULL, city VARCHAR(50) NOT NULL, country_id SMALLINT NOT NULL, last_update TIMESTAMP NOT NULL, PRIMARY KEY (city_id), CONSTRAINT fk_city_country FOREIGN KEY (country_id) REFERENCES country (country_id) ON DELETE NO ACTION ON UPDATE CASCADE );
This partial implementation has the issue that it does not parse well enough to understand when it found the end of a setting. So, it uses as a clue the comma (i.e., the start of a new setting) or the final closing parenthesis (i.e., the end of the list of elements) for the final setting.
Now, how safe is it to use this dirty trick? In this case, it is safe because SQL files are not written by humans, they are exported with tools. This means that there will not be missing parenthesis that will mess up the recognition of subsequent statements. So, we actually can be sure that every CREATE TABLE will end with a closing parenthesis and a semicolon. This may vary with different languages, different sources of SQL statements or different databases.
When you need to only partially implement a grammar these sorts of tricks can be quite helpful to speed up development and get your task done quicker. You have to be careful and aware of the risks, but they can be useful.
The Rest of the Grammar
The rest of the grammar is also fairly simple to understand. We just mention a couple of things.
name : QUOTE? NAME QUOTE? ;
The rule name is a parser rule instead of a lexer rule. That is because some tools wrap the name of the column with quotation marks (these are also used as apostrophes in some languages) like ` or '. With this definition, later in our code, we can easily extract the real name of the column without any check for quotation marks.
type : (INTEGER | INT) UNSIGNED? #integerType
| (TINYINT | SMALLINT) UNSIGNED? #smallIntegerType
| TEXT #textType
| BLOB (SUBTYPE type)? #blobType
| (VARCHAR|CHARVAR) LPAREN NUMBER RPAREN #varcharType
| CHAR LPAREN NUMBER RPAREN #charType
| YEAR #yearType
| DATETIME #datetimeType
| TIMESTAMP TIMEZONE? #timestampType
| (NUMERIC | DECIMAL) (LPAREN precision=NUMBER (COMMA scale=NUMBER)? RPAREN)? #decimalType
;
The rule to parse the type of the column includes rule labels. We designed this way to simplify our job later in the code, where we use the parser. This is also the reason because the VARCHAR rule is separated from the CHAR rule. Structurally the rules are obviously identical, but they mean something different. Remember: you should parse for your application, to make the parse effective for your needs.
fragment A : [aA]; fragment B : [bB]; fragment C : [cC]; fragment D : [dD]; fragment E : [eE]; // etc.
Since SQL is case-insensitive we use fragments for letters everywhere we need, to ensure that we parse everything correctly.
You can see the rest of the grammar on the companion repository.
Creating the C# project
We can finally see some code. We are going to create a C# project from the command line since we are using VS Code as our editor. These are the instructions to create the project and to add the ANTLR library.
// create a new directory somewhere // to create a new C# project dotnet new console -lang C# // to install the standard ANTLR 4 Runtime dotnet add package Antlr4.Runtime.Standard
These are the instructions to generate the parser and to run the program.
// to generate the parser antlr4 SQL.g4 -Dlanguage=CSharp -o generated -encoding UTF-8 // to run the program dotnet run
Even our main source code file is fairly standard.
static void Main(string[] args)
{
// standard ANTLR code
// we get the input
ICharStream chars = CharStreams.fromPath(args[0]);
// we set up the lexer
SQLLexer lexer = new SQLLexer(chars);
// we use the lexer
CommonTokenStream stream = new CommonTokenStream(lexer);
// we set up the parser
SQLParser parser = new SQLParser(stream);
// we find the root node of our parse tree
var tree = parser.statements();
// we create our visitor
CreateVisitor createVisitor = new CreateVisitor();
List<ClassDescriptor> classes = createVisitor.VisitStatements(tree);
// we choose our code generator...
ICodeGenerator generator;
// ...depending on the command line argument
if(args.Count() > 1 && args[1] == "kotlin")
generator = new KotlinCodeGenerator();
else
generator = new CSharpCodeGenerator();
Console.WriteLine(generator.ToSourceCode("SQLDataTypes", classes));
}
The comments are self-explanatory. After our standard code to setup ANTLR and parse the input, we employ our CreateVisitor. We use the visitor to create table statements and to generate an internal representation of them. Then we use this representation to generate a source code file in our chosen language. In our example we choose to generate either in Kotlin or C#, to show how easy it can be to work with our SQL data once you parse it.
This is the simple overall structure; we can now move on the individual parts.
Visiting the Statements
Let’s start by looking at the general organization of our visitor.
public class CreateVisitor
{
public List<ClassDescriptor> VisitStatements(StatementsContext context)
{
List<ClassDescriptor> tables = new List<ClassDescriptor>();
foreach(var statement in context.statement())
{
tables.Add(VisitStmt(statement));
}
return tables;
}
public ClassDescriptor VisitStmt(StatementContext context)
{
return VisitCreateStmt(context.createStmt());
}
public ClassDescriptor VisitCreateStmt(CreateStmtContext context)
{
ClassDescriptor table = new ClassDescriptor();
table.Name = context.tableName.NAME().GetText();
table.Fields = new List<FieldDescriptor>();
foreach (var el in context.element())
{
if(el.definition() != null)
{
table.Fields.Add(VisitDefinition(el.definition()));
}
}
return table;
}
[..]
The first thing we notice is that we do not need to use the standard base visitor that can be created for us by ANTLR. Our visitor uses just our code. We do not need to use the base visitor, because of the structure of a SQL file and because we know exactly what we need to visit. We can completely ignore everything that is not a create statement because every statement in our SQL files is a top-level element. It is not like statements in your average programming language, that can be nested inside a code block, function definitions, etc. Also, the structure of create statements is simple, so we can visit everything ourselves.
In short, all we need to do is:
- to visit the
statementsnode - then to visit each
statementnode (we ignore theignorenodes) and to select thecreateStmtnode - visiting the
createStmtnodes, we pick only thedefinitionnodes (we ignore theignorablenodes) to get all the columns definition
Translating Types from SQL to Your Language
Inside the VisitDefinition method we deal with the only real complication of this visitor: handling types.
public FieldDescriptor VisitDefinition(DefinitionContext context)
{
string name = context.name().NAME().GetText();
TypeDescriptor type;
switch(context.type().GetType().Name)
{
case "IntegerTypeContext":
type = VisitIntegerType(context.type() as IntegerTypeContext);
break;
case "SmallIntegerTypeContext":
type = VisitSmallIntegerType(context.type() as SmallIntegerTypeContext);
break;
case "VarcharTypeContext":
type = VisitVarcharType(context.type() as VarcharTypeContext);
break;
case "TimestampTypeContext":
type = VisitTimestampType(context.type() as TimestampTypeContext);
break;
case "TextTypeContext":
type = VisitTextType(context.type() as TextTypeContext);
break;
case "DecimalTypeContext":
type = VisitDecimalType(context.type() as DecimalTypeContext);
break;
case "CharTypeContext":
type = VisitCharType(context.type() as CharTypeContext);
break;
case "BlobTypeContext":
type = VisitBlobType(context.type() as BlobTypeContext);
break;
default:
type = null;
break;
}
if(context.nullability() != null && context.nullability().NOT() != null)
type.Nullability = false;
return new FieldDescriptor(name, type);
}
The issue is that we need to identify each type and then translate it in a way that is compatible with a programming language. In fact, SQL data types and programming language data types can be different. For example, SQL has types for variable and fixed size char array, this is less relevant in programming languages. As a sidenote, extreme precision in types is important for managing the size of data and similar concerns in databases. This is generally less important in programming languages. However, this might not be true for your use case. So this is something to keep in mind for your specific case.
We already have done the work to easily identify each type by creating a label for each option of the type grammar rule. Now, we just need to use a different method to visit each node correctly.
Before seeing the examples of VisitIntegerType and VisitSmallIntegerType, let’s notice a couple of things. First, we deal with nullability of types only once, on lines 37-38. Second, we are only dealing with some types, the ones used in our example SQL files.
private TypeDescriptor VisitSmallIntegerType(SmallIntegerTypeContext context)
{
if(context.UNSIGNED() != null)
return new IntegerTypeDescriptor(2, true);
else
return new IntegerTypeDescriptor(2);
}
private TypeDescriptor VisitIntegerType(IntegerTypeContext context)
{
if(context.UNSIGNED() != null)
return new IntegerTypeDescriptor(4, true);
else
return new IntegerTypeDescriptor(4);
}
These two methods are representative of the little effort we have to do. Each method returns a TypeDescriptor specific for each type.
The methods are simple, but different because each type is different. In the case of integer types we need to check whether the type is unsigned or not. We use only one IntegerTypeDescriptor for all integer types. This is simply because they can be described in the same way: from our point of view, the only difference between integer types is the number of bytes they need.
The TypeDescriptor classes themselves are also fairly trivial. They just are a series of classes that contain specific information for each type.
public enum BaseType
{
Integer,
Floating,
Decimal,
Text,
Binary,
ArrayCharacters,
Year,
DateTime
}
public class TypeDescriptor
{
public BaseType Type { get; protected set; }
public bool Nullability { get; set; } = true;
}
public class IntegerTypeDescriptor : TypeDescriptor
{
public int Bytes { get; private set; }
public bool Unsigned { get; private set; }
public IntegerTypeDescriptor(int bytes, bool unsigned = false)
{
Type = BaseType.Integer;
Bytes = bytes;
Unsigned = unsigned;
}
}
You can see the rest on the companion repository.
Generating Code
We have a custom representation of our original SQL code: a description of all the tables suited for our needs. Now we can generate the corresponding source code. We are going to generate the code in multiple languages: C# and Kotlin. We do this to show how easy it is to do anything once we get the information out of SQL and because there are different limitations in the two languages.
Generating Code in C#
Let’s start with seeing C#. We have only one public method: ToSourceCode, which accepts a namespace and a series of classes/tables definition.
public class CSharpCodeGenerator : ICodeGenerator
{
public string ToSourceCode(string idNamespace, List<ClassDescriptor> classes)
{
StringBuilder sourceCode = new StringBuilder();
// opening namespace
sourceCode.AppendLine($"namespace {idNamespace}");
sourceCode.AppendLine("{");
foreach(var c in classes)
{
sourceCode.AppendLine($"tpublic class {c.Name}");
sourceCode.AppendLine("\t{");
foreach(var f in c.Fields)
{
switch(f.Type.Type)
{
case BaseType.Integer:
sourceCode.AppendLine($"\t\tpublic {GenerateInt(f.Type as IntegerTypeDescriptor)} {f.Name} {{ get; set; }}");
break;
case BaseType.Text:
sourceCode.AppendLine($"\t\tpublic string {f.Name} {{ get; set; }}");
break;
case BaseType.ArrayCharacters:
sourceCode.AppendLine($"\t\tpublic {GenerateCharArray(f.Name, f.Type as CharArrayTypeDescriptor)}");
break;
case BaseType.DateTime:
sourceCode.AppendLine($"\t\tpublic DateTime {f.Name} {{ get; set; }}");
break;
case BaseType.Decimal:
sourceCode.AppendLine($"\t\tpublic decimal {f.Name} {{ get; set; }}");
break;
case BaseType.Binary:
sourceCode.AppendLine($"\t\tpublic bytes[] {f.Name} {{ get; set; }}");
break;
}
}
sourceCode.AppendLine("\t}");
sourceCode.AppendLine();
}
// closing namespace
sourceCode.AppendLine("}");
return sourceCode.ToString();
}
[..]
This method takes care of generating the whole new source code file. It handles the enclosing namespace (necessary for C# files) and the whole class.
We transform columns into properties. These are the obvious choice because it is easy to anticipate that we would need to transform any data coming from SQL in a different format to handle it in our programming language. For example, dates would be different. We would also need to enforce fixed-size arrays in some way. That is because programming languages usually do not have a well-defined way to handle an input too large or too small. Instead databases can automatically do things like padding an input that is too short with spaces.
There are generally three cases:
- the type has a perfect correspondence (e.g. lines 23-24
TEXTbecomes aString). So we just write the property directly. - the type has only a partial, but unambiguous, correspondence (e.g. lines 32-33 DECIMAL becomes
Decimal, but the SQL and C# type behave differently). For example, a SQL decimal allows us to specify a precision, to set just how many digits it can hold. In C# you cannot do that. Normally we would need to take care of this difference, in our example, we just ignore the issue - the type has multiple correspondences (e.g., lines 20-21
INT,SMALLINTbecomeint,short), so we handle them with a method
For the third case, we are going to see the integer example.
private string GenerateInt(IntegerTypeDescriptor descriptor)
{
StringBuilder intType = new StringBuilder();
// we ignore nullability, because it is not well supported for all C# types
if(descriptor.Unsigned == true)
intType.Append("u");
switch(descriptor.Bytes)
{
case 2:
intType.Append("short");
break;
case 4:
intType.Append("int");
break;
case 8:
intType.Append("long");
break;
}
return intType.ToString();
}
We can find a perfect correspondence between each integer type in SQL and C#. Since integer types are all represented internally the same way, it all depends on the number of bytes used for each of them. Depending on how many bytes are stored in our instance of IntegerTypeDescriptor, we generate the proper C# type.
The only issue is with C# itself: it does not have perfect support for nullability. Until C# 8.0, reference types could be nullable by default, so it would be fairly inconsistent to work with nullable types both in our code and any third-party code.
On the other hand, we can easily deal with unsigned integers, we just need to prepend a u, to use unsigned types.
Generating Code in Kotlin
Generating the code for Kotlin is very similar.
public class KotlinCodeGenerator : ICodeGenerator
{
public string ToSourceCode(string idNamespace, List<ClassDescriptor> classes)
{
StringBuilder sourceCode = new StringBuilder();
// declaring package
if(!String.IsNullOrEmpty(idNamespace))
sourceCode.AppendLine($"package {idNamespace}");
// adding imports
sourceCode.AppendLine();
sourceCode.AppendLine("import java.time.LocalDateTime");
sourceCode.AppendLine("import java.math.BigDecimal");
sourceCode.AppendLine();
foreach(var c in classes)
{
sourceCode.Append($"data class {c.Name}(");
foreach(var f in c.Fields)
{
switch(f.Type.Type)
{
case BaseType.Integer:
sourceCode.Append($"var {f.Name}: {GenerateInt(f.Type as IntegerTypeDescriptor)}");
break;
case BaseType.Text:
sourceCode.Append($"var {f.Name}: String");
break;
case BaseType.ArrayCharacters:
sourceCode.Append($"var {f.Name}: {GenerateCharArray(f.Type as CharArrayTypeDescriptor)}");
break;
case BaseType.DateTime:
sourceCode.Append($"var {f.Name}: LocalDateTime");
break;
case BaseType.Decimal:
sourceCode.Append($"var {f.Name}: BigDecimal");
break;
case BaseType.Binary:
sourceCode.Append($"var {f.Name}: ByteArray");
break;
}
if(f != c.Fields.Last())
sourceCode.Append(", ");
}
sourceCode.AppendLine(")");
sourceCode.AppendLine("");
}
return sourceCode.ToString();
}
There are no structural differences. The only variations depend on the differences between the languages themselves. For instance, the equivalent of a namespace, i.e., packages are not required in Kotlin. We can also use the special data classes in Kotlin to quickly define a class with its properties directly in the default constructor.
On the other hand, we need to import some Java packages, because Kotlin does not directly have classes for DateTime types. Since Kotlin can run in different environments (i.e. JVM with Java support, JavaScript, native with C++ support), we should probably find a way to support all of these environments. In a normal situation, we would probably create a runtime in pure Kotlin with these custom types (i.e., KotlinDateTime) and then add support for each platform in separate files. This way we could just generate one Kotlin file for all environments. This would be overkill for this example, so we just consider Kotlin when run on the JVM.
private string GenerateInt(IntegerTypeDescriptor descriptor)
{
StringBuilder intType = new StringBuilder();
switch(descriptor.Bytes)
{
case 2:
intType.Append("Short");
break;
case 4:
intType.Append("Int");
break;
case 8:
intType.Append("Long");
break;
}
// we ignore unsigned, because it is not well supported in C#
if(descriptor.Nullability == true)
intType.Append("?");
return intType.ToString();
}
We can also see that the methods to generate integral types are very similar in both C# and Kotlin. The difference is that with Kotlin nullability has always been supported, while support for unsigned integer is still experimental for the current version.
Conclusions
In this article, we have seen how to parse SQL. In general, our advice is to:
- Consider if you can use existing tools or libraries to process SQL code. Some of them even support multiple SQL-dialects or multiple programming languages. If you can use any of them for your needs they should be your first option
- If you want to build a solution in-house, you may consider starting from the few ANTLR grammars available for the major SQL databases. They can really help you get started in parsing SQL
- If you are stuck with a less common SQL database you might be in trouble. Parsing SQL from scratch it is going to be hard work: the language has a fairly simple structure, but it is large, it has many variations and in some cases even procedural extensions. In this article, we have seen a few tricks to start parsing even with a partial grammar. This can be a good way if you need to parse only small parts of the language
If none of these options work for you, and you need some commercial option supporting you in building a solution for your needs, we at Strumenta may be able to help. For example, through our commercial PL/SQL parser.
We would like to thank people that commented this Hacker News post for their feedback
Read more:
If you want to understand how to use ANTLR you can read our article The ANTLR Mega Tutorial.
