
I played for the first time with the Whole Platform a few years ago. It was one of the first Language Workbenches on which I put my eyes and I found it very fascinating. Then I was dragged into other things: whoever went through a PhD knows what I mean. Academic life has always a way to distract you.
Now I decided to find the time to take another look. I want to learn about it and compare it to other tools I used, most notable Jetbrains MPS. So, let’s get started.
Getting started with the Whole Platform
The Whole Platform can be downloaded from here: https://sourceforge.net/projects/whole/
It is based on Eclipse but it is not distributed as a plugin but instead as a separate IDE. You have just to unzip it and start it.
Update: I chose to download it as a separate IDE but you can also install it as a set of plugins for your Eclipse installation. Just use this update site: http://whole.sourceforge.net/updates
Once you have started it you have to create a Whole Project. Inside the Whole Project we are going to create a Whole Model. This is the wizard you will meet:
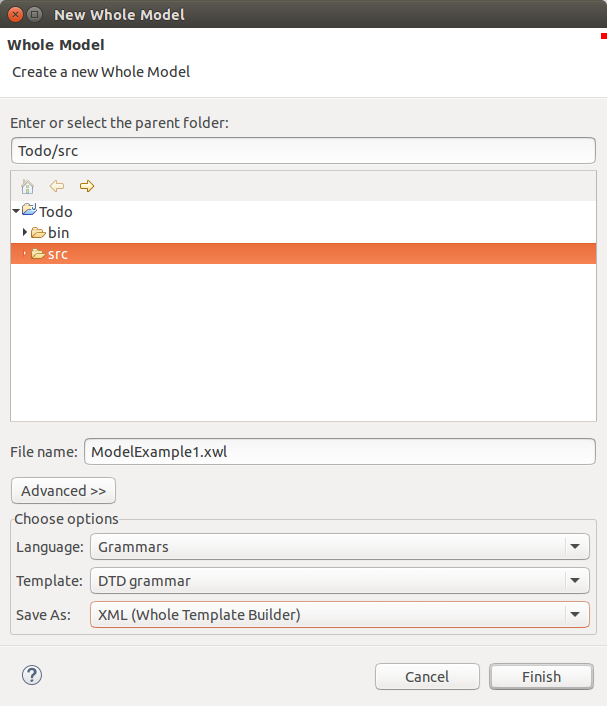
What surprised me at this stage is the flexibility we have: we can choose:
- the language we are going to use for this model
- the template
- the persistence format.
“Language” in this case means the metamodel: the kind of information we are going to produce. We could then save the same information using different persistence formats: for example the generic Whole XML format or some custom textual formats created for a specific language. We can also use different templates for each Language. I think this can significantly speed-up the daily activities. This also provide to newbies like me access to some examples for each language: I created a few grammars using different templates and by looking at those I understood how the Grammars language worked. Training is an aspect frequently underestimated when talking about DSLs and this little feature could help.
Whole Platform and grammars
From what I read and by talking with Riccardo Solmi, the author of the Whole Platform, I understand that one of the strength points of this Language Workbench is its ability to support several persistence formats. It means you can load and save models using different formats.
This is particularly important when you want to open files written in a format already defined. Suppose for example that we are dealing with some very simple todo lists. Something like:
* learn about the Whole Platform * write a post
We want to be able to import this file as it is in the Whole Platform and edit it through its reflective editor. Like this:
In practice we are using two projections of the same data and it works like a charme.
Define the grammar
How could you import our todo list in the Whole Platform to later process it?
By defining the corresponding grammar:
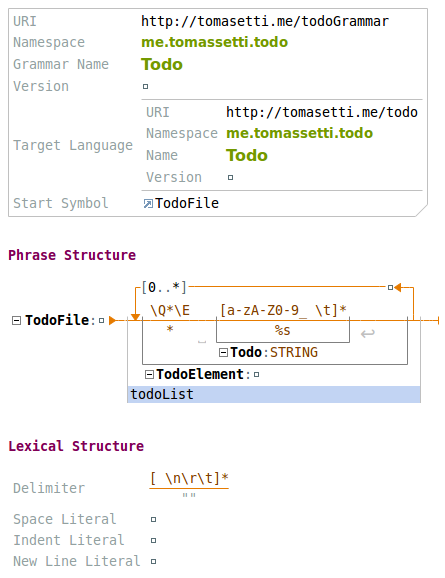
A common Back-Naur Form (BNF) grammar has one goal: recognize the information in a text file and build a structure out of it (the Abstract Syntax Tree). In the Whole Platform grammars have instead two roles:
- parse the text files to get the AST (same as the BNF grammars)
- serialize the AST back into the text format
So each element of the grammar has to provide these two functions. Let’s look into this.
- We are saying that our start or top symbol is the TodoFile
- Each TodoFile is composed by a list of TodoElement. This list will be assigned to the property todoList of the TodoFile
- Each TodoElement is a sequence of an asterisk followed by a Todo, which is basically a string
We can make the grammar simple to examine by normalizing it. We have a feature to perform this refactoring automatically for us. We get this:
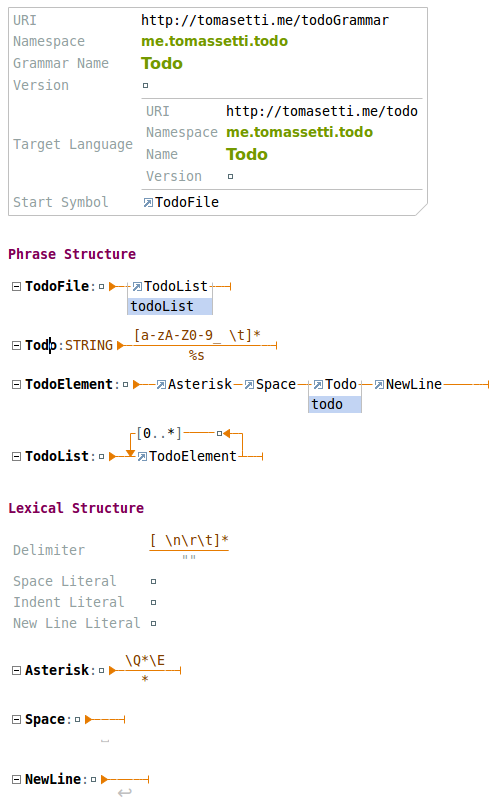
To be precise: we almost get this automatically: I had just to rename the three elements derived (Asterisk, Space, and NewLine). They were created with default names (Token, Token1, and Token2).
Look at terminals
Terminals are represented by that sort of division. Above the line we have a regular expression while tells us how to parse that element, while the expression below tells us how that node can be serialized.
It is interesting to notice that Space and NewLine are not actually recognized associated to any character of the input while parsing: they correspond to characters which are ignored (see the Delimiter rule). However these definitions are useful when we want to dump our model to text.
Let’s look at the other terminals we have.:
![]()
The regular expression above the line means parse an asterisk. You can use all regular expressions which are recognized by Java: see the documentation for details . The fact is the asterisk has a special meaning in a regular expression so we escape it by making it preceded by Q and followed by E. The line below the line is instead a simple string which will be used in the generated text file to represent this node: it is just an asterisk.
This is instead the content of one Todo element:
![]()
We specify that the description of our todo element can contain any number of letter, digit, space, tab or underscores. When we will dump it we will just copy its whole content (%s).
The nice thing is that in Whole you can define a grammar and immediately use it to process existing files, without the need to generate parsers or anything else. If you are familiar with the environment it permits to have a very fast turnaround.
Conclusions
The Whole platform feels different from the other Language Workbench I am most familiar with: Jetbrains MPS. It feels more flexible and I think that the possibility to work with existing formats seamlessly is a great feature.
There are things I miss: the auto-completion in MPS makes me faster when defining my models. To be fair I have some years of experience using Jetbrains MPS while I am new to Whole. Perhaps using its drag and drop functionality could make the editing much faster. Also, several refactorings are available from the contextual menu, the same mechanism used to created nodes. In MPS you create nodes through auto-completion and then you have intentions for refactoring (triggered by pressing ALT + Enter).
Renaming works differently: in MPS a reference to an existing element is automatically updated when renaming the original element. This is not the default behavior in MPS: a refactoring action can be easily implemented to achieve the same result. In this case as in other I had the impression that Whole is about flexibility while MPS is about sensible default behaviors.
One problem is the documentation: the tool has been extensively used in a large company in Italy but it lacks documentation available publicly. To this day the best source of documentation is the submission to the Language Workbench Challenge for 2011: it contains a huge tutorial describing screen by screen how the solution to not trivial tasks was implemented. You can download it from here: https://sourceforge.net/projects/whole/. I hope to help a little bit by writing this and hopefully more tutorials.
Finally let me thank you Riccardo Solmi for helping me out while I was experimenting with the Whole platform. He is the author of this incredible platform, and while he had some valuable help from Enrico Persiani along the years I think it is an incredible achievement to have designed and built a tool which can compete with a product from Jetbrains.

