")
In this article, we will present our RPG parser. It is based on our Chisel methodology and our open-source library, Kolasu. The parser is commercially licensed, but we hope this article will be useful for anybody wanting to learn what a parser is for and how to use one.
If you are looking to know what is a parser, we are going to explain it.
If you are looking to know what you can use a parser for, we are going to show you three examples of the things you can build with one:
- a custom software to understand which external programs your code calls
- a tool to detect duplicate code
- documentation in the form of diagrams
If you are looking to design your own parser, we are going to show you why you might want to follow our Chisel method to build one.
What Is a Parser (And What Is Not)
We work with parsers every day, so for us it is very clear what a parser is and what it can do. However, this might not always be the case for our clients. So, let’s spend a few words on this point.
In general terms, a parser is a software that can understand the syntax, but not the semantics of some code.
Fundamentally, a parser is software that creates a model of the input, so we can extract data from it.
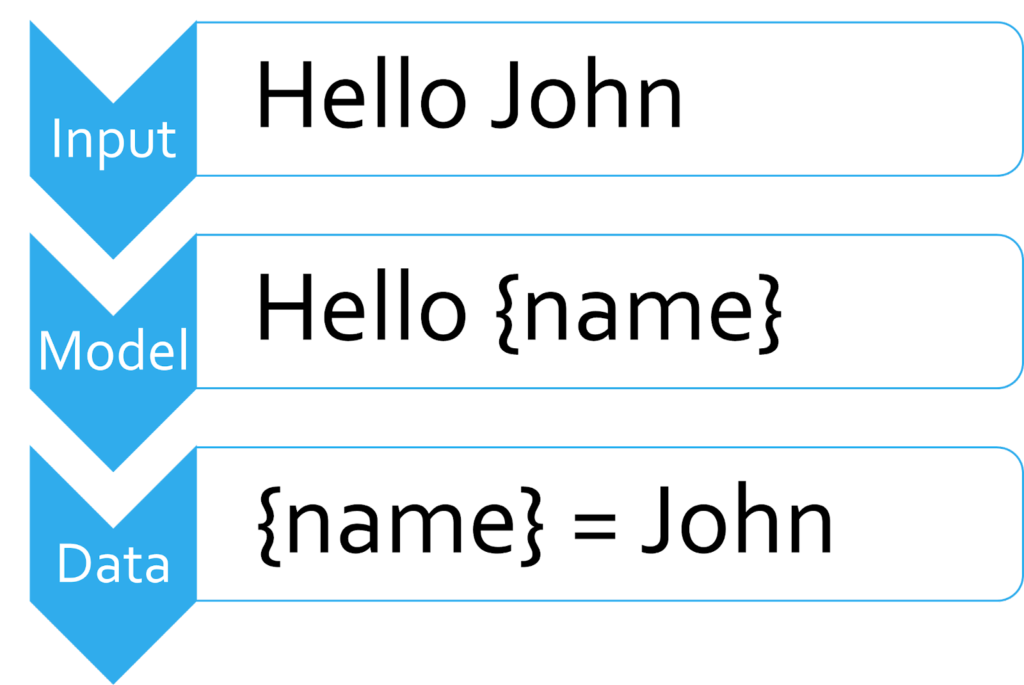
This model should be clear, useful, and easy to work with. The model that matches all these criteria is the Abstract Syntax Tree (AST). The practice of using an AST to represent code is an industry standard. Of course, how to design the AST for a particular language is open to debate.
A parser can read the code, but it cannot execute it. For example, a parser can both recognize a variable declaration and an expression.
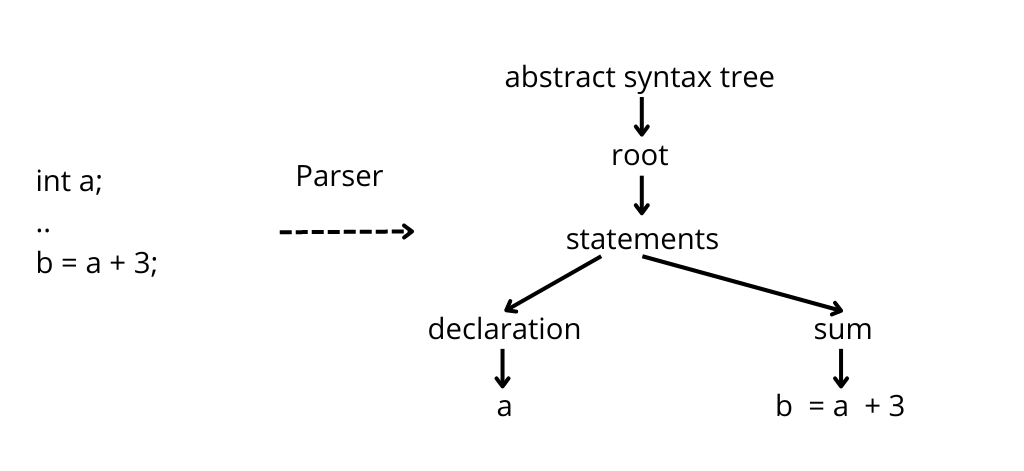
What it cannot do is linking the two and understand where a variable used in an expression was declared. This feature is called symbol resolution and it is a functionality built on top of the parser.
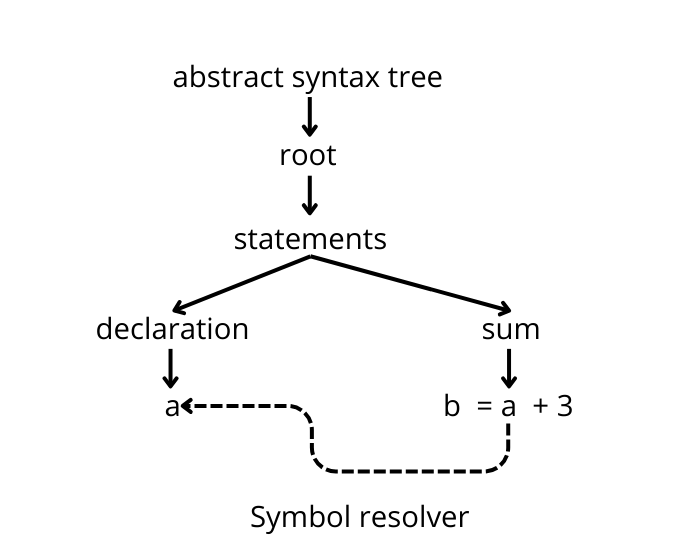
Given the needs of our clients, we implemented some symbol resolution functionality. This is technically outside the scope of a parser, but it was needed, so we added it. For example, our RPG parser can resolve references to DDS definitions. We are going to see some examples of what our specific parser can do, later. However, it is an important point to keep in mind in case you are comparing different parsers.
Play Around on the Playground
We have set up a platform to allow testing the RPG parser online, without the need to install anything. You can see what an AST looks like. You can test our RPG parser, or any of our other parsers for that matter, with some example files on our playground.
It is a great way to get a feel of how it works and whether it supports the features you care about. You can try it here: https://playground.strumenta.com. If you need it, you can ask us to test the parser on some examples you provide.
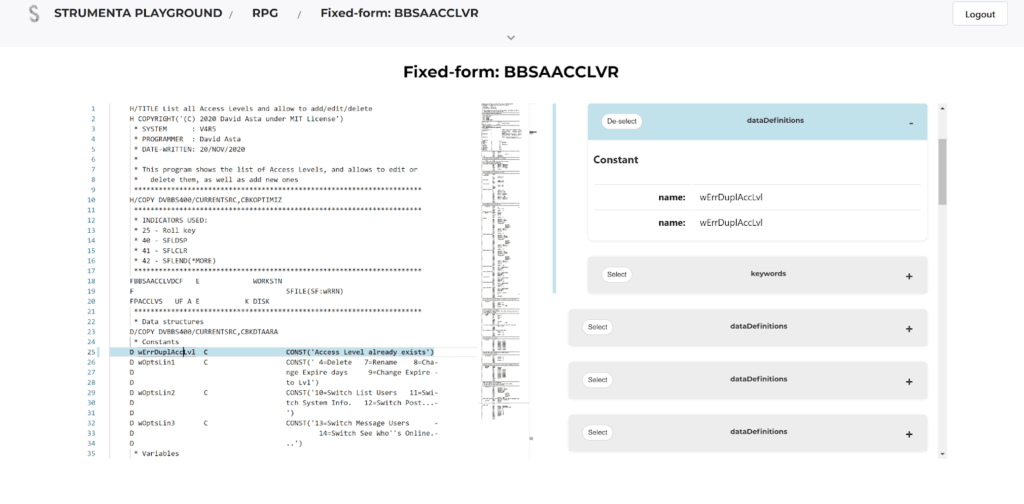
You can also read the documentation on the RPG parser online.
Chisel Methodology
The RPG parser is based on the Chisel methodology. It is the missing link between source code and a convenient structure for its interpretation and manipulation: an AST. When building an interpreter, transpiler, compiler, editor, static analysis tool, etc., at Strumenta we always implement the software using a pipeline. A set of reusable components that can be shared for different projects.
For example, this is a pipeline for an RPG-to-Java transpiler.

The RPG parser and the Semantic Enricher components can be re-used for, let’s say, building an interpreter or an editor. This approach increases productivity and improves the quality of the software. For instance, any improvement to a core component for one project gets automatically shared with others.
StarLasu is the collection of runtime libraries that implement this methodology to support it in Java, Kotlin, Python, Javascript, Typescript, and C#.
At its core, StarLasu permits the definition of ASTs, on which all other functionalities are built. You can navigate and transform ASTs to do everything from reading the original values to simplifying your code. With the features provided by the library, you can do anything from analyzing a codebase to building a transpiler.
Some core features shared by our StarLasu libraries are:
- Navigation: utility methods to traverse, search, and modify the AST
- Serialization: export and print the AST as XML, as JSON, as a parse tree
- EMF and Lionweb interoperability: ASTs and their metamodel can be exported to the EMF or Lionweb formats
Interoperability with EMF and Lionweb is important because these are standard formats used in language engineering so you can mix and match different software, even from different providers.
You can read more about our methodology in a dedicated article.
What Do You Need an RPG Parser For?
RPG is a language often used to build applications from the ground up. Companies have built custom ERP software, software to manager their warehouses, etc. Users have clusters of internal applications built over the decades to handle all their needs.
The software is custom, so it is tailored to the needs of the companies. However, it has grown organically over the years, so the code is often not well organized. It is not rare to have thousands of files without knowing which ones constitute a separate program. So one typical use case is to use an RPG parser to perform analysis and understand which files create each program and how everything works together. A related application is creating documentation for the code, like representing the code behavior with UML diagrams.
RPG is still used in many companies but it was developed decades ago. It works ok when you are maintaining old and thoroughly tested programs, but it is less productive for creating new programs. It is also not great when you need to integrate new technologies. The reason is partly because of the long history and partly because of the design patterns that were common at that time.
For instance, the data definition and the database are effectively part of the program. This is a consequence of the system it was used in.
RPG Programs Are Integrated With Their Platform
Having a long history implies that it is important to preserve backward compatibility. IBM leadership was still very much concerned with selling hardware, so the idea was to make the software integrated with the whole platform (i.e., the operating system that was designed for the specific line of hardware). So, while RPG itself is just a language, programs are often integrated with the systems they were designed for. This is simply how programs were developed back then.
These are just a general description of the challenges, we have written an article to discuss the issues with legacy code on a platform using RPG, like the AS/400 or System i.
When such challenges outweigh the benefits of RPG, you want to build a transpiler. Rewriting all the code from scratch is risky and costly. Throwing all the custom code away results in less productivity, given that the software was designed for the company. So you want to migrate the code from RPG and do it automatically. The way to do that is with a transpiler. And for building that you first need a parser to understand the code.
There are also standard uses for a parser that are valid for an RPG parser,, too. For instance you can use s a parser for building an editor: it will help the editor to provide syntax highlighting and autocompletion. You can create a static analysis tool, etc.
Why Use a Ready-to-go Parser?
You need a parser that has been thoroughly tested, which is documented, and gives you someone to call in case you encounter any problems.
We are experts and we have built tons of parsers for our clients. This means that we completely understand the importance of this component and we have a solid methodology. And we build parsers designed for what our users need. For example, our SAS parser is geared to support data lineage, because that is what the typical user needs.
Our RPG Parser has also been built for the needs of our clients, so it is battle-tested and used in production. It supports all RPG statements and most Data Description Specifications (DDS).
It can handle both the traditional fixed format, free format, and the two formats mixed together. This is important because the fixed format is quite obnoxious to use, so new developers prefer start using the free format as soon as possible. The result is that actively maintained files soon go from fixed format to mixed format.
How to Setup the Parser
The only two requirements you need to use the parser are rpg-parser and Kolasu packages. For example, for a Java Maven, you would write something like this.
<dependencies>
<dependency>
<groupId>com.strumenta</groupId>
<artifactId>rpg-parser</artifactId>
<version>2.1.52</version>
</dependency>
<dependency>
<groupId>com.strumenta.kolasu</groupId>
<artifactId>kolasu-javalib</artifactId>
<version>1.5.56</version>
</dependency>
</dependencies>
This would use the rpg-parser and kolasu-javalib, the version of Kolasu tailored for use from Java.
You can easily adapt this for another build system like Gradle.
dependencies {
implementation "com.strumenta.kolasu:kolasu-core:1.5.56"
implementation "com.strumenta.kolasu:kolasu-javalib:1.5.56"
implementation "com.strumenta:rpg-parser:2.1.52"
}
That is all you need to be able to use the parser in your code just as easily as any other library.
Understanding Which Programs Your Code Calls
One feature of RPG is that you can easily call external programs with just one statement. Imagine you want to get an understanding of all the external programs every file calls.
So, you want to collect all statements like the following one.
C CALL 'MAGIC'
C PARM NAME
C PARM PASS
You can do that, all with a few lines of code. We are going to use Kotlin for this example, but of course, you could also do the same with Java.
val compilationUnits = File("examples_dir/").walk().map {
RPGKolasuParser.parserFromExtension(it).parse(FileInputStream(it))
}
compilationUnits.forEach {
assert(it.root != null)
assert(it.correct)
}
var calls = compilationUnits.flatMap {
it.root!!.walk().filterIsInstance<CallProgramStatement>()
}.toList()
In the first statement, we parse all the examples in the creatively called folder examples_dir.
In the second one, we ensure that the parsing succeeded, by checking that root of the AST is a valid node and no issues have been reported.
Then we walk through all the ASTs, one for each file, and we look for nodes of type CallProgramStatement. The walk method comes from Kolasu; it explores the whole tree, visiting each node. Flatmap is a method from the standard Kotlin library that transforms a series of lists into one list.
How to Detect Duplicate Code
RPG was designed before was common to encapsulate code into classes or even functions. You can separate code into procedures, but you can also put all your statements in the global scope. One of the consequences of this pattern is that a lot of code gets reused.
Imagine you have a program to calculate sales taxes in state A and you need to calculate sales taxes in state B. You just copy the code from the first program and start changing some bits here and there.
This is not ideal, because if you ever find a bug, you will probably fix it in one program but not the other one. The problem is how do you find all that similar code and who wants to fix all that code? Well, we cannot help you with finding the will, but the RPG parser can help you in detecting similarities.
Why We Need the RPG Lexer
What you need to use is to use the lexer that comes with the parser. You can think of the lexer as the first step of the whole parser. The lexer identifies simple patterns in the text and transforms them into tokens. For instance, it takes a series of characters enclosed between two quotes becomes a STRING token. The parser will then look at this sequence of tokens for the whole file and use it to create an AST. So, the lexer reads the stream of characters of the input and transforms into a stream of tokens. The parser organize this stream of tokens into an AST.
This image represents the relationship between the two.

If you are interested in more information about the whole parsing process, you can read it in our Guide to Parsing: Algorithms and Terminology.
You need to use the lexer because it is difficult to compare two ASTs, since they might have a different structure. Imagine having two files with the same statements but in one file they are contained in different subroutines, but in the other one are directly in the global scope. It is difficult to find a way to detect similarities between them programmatically. This in addition to the practical difficulties of equality comparison between complex objects.
It is Just a List of Tokens
It is easier to do this with the result of lexing, because that is just a list of tokens. So, all you need to do is to compare the elements of two lists.
val lexingResult1 = RPGKolasuLexer().lex(File("file1.rpgle/"))
val lexingResult2 = RPGKolasuLexer().lex(File("file2.rpgle/"))
You can lex a file by using RPGKolasuLexer and the method lex.
Then you can compare the two lists of tokens.
val codes : List<RPGToken> findSimilarPiecesOfCode(lexingResult1, lexingResult2)
Now, there are many possible ways of comparing two sequences. Here we choose a trivial one. We look at the first element of the first sequence. We compare this element with any of the second sequence until we find a match or we reach the end of the second sequence.
If we find a match, we advance in parallel, adding the text of the match to our list of matches (we save them in the variable codes).
fun findSimilarPiecesOfCode(first : LexingResult<RPGToken>, second: LexingResult<RPGToken>) : List<String> {
val codes = mutableListOf<String>()
var indexSecond = 0
var index = 0
var lastMatch = 0
while(index < first.tokens.size) {
if(first.tokens[index] == second.tokens[indexSecond]) {
var text = ""
while(first.tokens[index] == second.tokens[indexSecond]
&& index < first.tokens.size
&& indexSecond < second.tokens.size) {
text += first.tokens[index].text
index++
indexSecond++
}
lastMatch = indexSecond
codes.add(text)
}
else {
indexSecond++
}
if (indexSecond >= second.tokens.size) {
indexSecond = lastMatch
index++
}
}
return codes
}
When we reach the end of the second sequence, we advance the first sequence by one and restart the comparison from the last match with the second sequence.
This is obviously a simple way of doing a comparison, riddled with caveats, but it works in getting a quick list of equal sections of code.
Generate Documentation Diagrams From Code
RPG is not a bad language, but it is hard to follow what the code does at a glance. If nothing else for the impossibility of using formatting and whitespace to group code in a logical way.
So, one thing you might want to do is to generate diagrams to represent the workflow of code. A diagram would also make the code easier to understand for people new to RPG and therefore do not understand its syntax.
You want to get a diagram like this one.
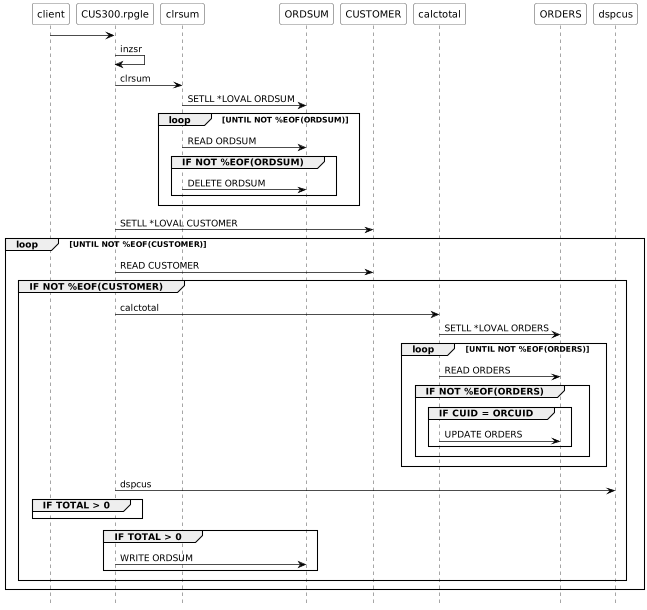
This is a diagram generated by PlantUML, so all we need to is to transform the AST into a textual representation understandable by PlantUML, which will generate the diagram.
The textual representation looks like this.
@startuml
'https://plantuml.com/sequence-diagram
!pragma teoz true
hide footbox
skinparam sequence {
ArrowColor Black
LifeLineBorderColor #000000
LifeLineBackgroundColor #FFFFFF
ParticipantBorderColor #000000
ParticipantBackgroundColor #FFFFFF
ParticipantFontColor #000000
}
client -> CUS300.rpgle :
CUS300.rpgle -> CUS300.rpgle : inzsr
CUS300.rpgle -> clrsum : clrsum
[..]
So it is basically a list of configuration statements. We need to get from the AST to this.
In Where We Accidentally Build a Transpiler
We already know how to parse the code, so we assume that you have done that and now have an AST that you need to transform into a diagram.
In the following example, an AST is given as the argument model of the method.
/**
* Transforms a given RPG AST into a PUML diagram.
*
* @param model the RPG AST to be transformed.
* @return the AST representing the PUML diagram.
* @throws Exception if the transformation fails.
*/
@Override
public Node transform(Node model) throws Exception {
PUMLDiagram target = new PUMLDiagram();
String file = inputFile.getName();
if (model instanceof CompilationUnit) {
CompilationUnit cu = (CompilationUnit) model;
// RPG code contains an initialization routine it is executed first
for (Subroutine s : cu.getSubroutines()) {
if (s.isInitializationSubroutine()) {
target.add(
new PUMInvoke(file, file, "inzsr", List.of()
));
}
}
// Process the main statements
for (Statement s : cu.getMainStatements()) {
target.add(transformStatement(cu, s));
}
return target;
}
throw new Exception(String.format("Invalid input Model: %s",
model.getClass().getName()));
}
As you can see, it is fairly easy, we first check for any standard initialization routine. This is automatically executed, so we need to add it to a diagram manually. That is because the call is implicit and not in the code itself.
Then we walk through all the global statements, that are conveniently accessible using the getMainStatements method in the AST root (CompilationUnit).
The transformStatement method is the one doing the work of transforming an AST node into an element of a PlantUML diagram. Each statement is then transformed into a string. For instance, an IfSstatement of RPG is transformed into an IF node for PlantUML, PUMLIf. Then the PUMLIf node is translated into a string with a string formatter.
nodePrinters.put(PUMLIf.class, (statement) -> {
PUMLIf s = (PUMLIf) statement;
ArrayList<String> sequence = new ArrayList<>();
sequence.add(String.format("group IF %s",s.getCondition()) );
for(PUMLStatement ps : s.getBody()) {
sequence.add(print(ps));
}
sequence.add("end");
return String.join("\n",sequence);
});
Then this list of strings is inserted into a template to generate the final textual representation. This way, we also accidentally learned how to create a transpiler. Because that is a transpiler: a software that transforms a code in one language into another one. In this case RPG Code into PlantUML code. Our production transpilers are more sophisticated, but the general principle remains the same: you transform the original AST into your target AST and then transform your target AST into text.
If you are interested in looking deeper into this example, you can read the dedicated article on how to use the RPG parser to generate sequence diagrams.
Using the Parser From the Command Line
Most users want to integrate the parser into their software, so they are going to use it as a library. However, you can use the parser JAR just as a command line tool, to create save your AST into a EMF representation, if you wish. It is as easy as this.
java -jar rpgparser-<verion>.jar <input.rpgle> --output ./
This would generate a JSON file for each input file (you can also provide a directory as input). Then you could take advantage of any EMF library to work with the result. This feature is included with every Kolasu-based parser, so you do not have to worry about it. And you can also have it for free if you build your own Kolasu-based parser.
Performing Symbol Resolution on an RPG Project
A typical situation that we need to deal with is that a company has a bunch of files and a few software. The problem is that they do not know which files implement which software. That might seem surprising if you have never used RPG. If you have, you know why that happens. Given that RPG software is supposed to be integrated with the whole platform, calling an external program is just as easy as calling a function.
The issue is that this confusion makes it harder to migrate the whole software stack. You want to start the migration from the programs that have no dependencies on others and move up from there. This is easier to manage and reduces the risk of getting stuck in the migration. So, your first step is to identify the programs you have.
Given the reality of RPG codebases to do that you need to solve all references in a RPG program. So, all you start with is a bunch of RPG files and a bunch of DDS files and you need to understand which ones go together. To do that you can follow how the Data Descriptions are used in an RPG file and from which DDS comes from.
All you need to do is write three lines of code.
val compilationUnit: CompilationUnit = parseRPGLE(File("src/test/resources/rpgle/CALCFIBF.rpgle"))
RPGExternalProcessor.resolve(compilationUnit, ddsFolder = File("src/test/resources/dds"))
rpgSemantics().symbolResolver.resolve(compilationUnit)
The first line parses the RPG code.
The second one tells our processor where the DDS files are.
The third one resolves the symbols.
Symbol Resolution in Action
This code takes a file like this.
* Calculates number of Fibonacci in an iterative way
D NBR S 8 0
D RESULT S 8 0 INZ(0)
D COUNT S 8 0
D A S 8 0 INZ(0)
D B S 8 0 INZ(1)
D DSP S 50
FLOGFILE Up E Disk
FPHYFILE2 Up E Disk
*--------------------------------------------------------------*
[..]
*--------------------------------------------------------------*
C *INZSR BEGSR
C EVAL DSP='INZSR'
C DSPLY DSP
C ENDSR
C* Entry Point
C *LOVAL SETLL LOGFILE
C READ LOGFILE
C DOW NOT %EOF(LOGFILE)
C EVAL NBR = %DEC(SNBR : 8 : 0)
And a DDS file, called LOGFILE.dds like this one.
A*
A**********************************************************************
A R RCALCFIB PFILE(PHYFILE1)
A K SNBR
And resolve all symbols, providing information on symbols like the one used in the SetLowerLimit statement LOGFILE, in the third-to-last line. The resolver first looks up the FileEntry FLOGFILE to identify the file and then it can link to the proper definition in the file from any reference in the source code.

The reference to SNBR in the last line of the code is now linked to the proper Data definition in LOGFILE.dds.
Summary
We hope you have seen how easy it is to use our RPG parser. It has been battle-tested and is used in production by various companies.
We have distilled our knowledge about parsing into this software, to make the most productive RPG parser out there. Built using a solid methodology, that is open to all and can be applied to build your software. This multiplies our ability to improve the software we build.
We have seen how to use the parser to identify how programs call each other, to find similarities between files, and even to document the code.
You can start playing with the parser on the Strumenta Playground.
Resources
Play with parsers on the Strumenta Playground
Discover our parsers Ready-to-go

