
What we are going to build
In this post we are going to see how to build a standalone editor with syntax highlighting for our language. The syntax highlighting feature will be based on the ANTLR lexer we have built in the first post. The code will be in Kotlin, however it should be easily convertible to Java. The editor will be named Kanvas.
This post is part of a series. The goal of the series is to describe how to create a useful language and all the supporting tools.
- Building a lexer
- Building a parser
- Creating an editor with syntax highlighting
- Build an editor with autocompletion
- Mapping the parse tree to the abstract syntax tree
- Model to model transformations
- Validation
- Generating bytecode
After writing this series of posts I refined my method, expanded it, and clarified into this book titled How to create pragmatic, lightweight languages
Code
The code is available on GitHub. The code described in this post is associated to the tag syntax_highlighting
Setup
We are going to use Gradle as our build system.
buildscript {
ext.kotlin_version = '1.3.70'
repositories {
mavenCentral()
maven {
name 'JFrog OSS snapshot repo'
url 'https://oss.jfrog.org/oss-snapshot-local/'
}
jcenter()
}
dependencies {
classpath "org.jetbrains.kotlin:kotlin-gradle-plugin:$kotlin_version"
}
}
apply plugin: 'kotlin'
apply plugin: 'application'
apply plugin: 'java'
apply plugin: 'idea'
apply plugin: 'antlr'
repositories {
mavenLocal()
mavenCentral()
jcenter()
}
dependencies {
antlr "org.antlr:antlr4:4.5.1"
compile "org.antlr:antlr4-runtime:4.5.1"
compile "org.jetbrains.kotlin:kotlin-stdlib:$kotlin_version"
compile "org.jetbrains.kotlin:kotlin-reflect:$kotlin_version"
compile 'com.fifesoft:rsyntaxtextarea:2.5.8'
compile 'me.tomassetti:antlr-plus:0.1.1'
testCompile "org.jetbrains.kotlin:kotlin-test:$kotlin_version"
testCompile "org.jetbrains.kotlin:kotlin-test-junit:$kotlin_version"
}
mainClassName = "KanvasKt"
generateGrammarSource {
maxHeapSize = "64m"
arguments += ['-package', 'me.tomassetti.lexers']
outputDirectory = new File("generated-src/antlr/main/me/tomassetti/lexers".toString())
}
compileJava.dependsOn generateGrammarSource
sourceSets {
generated {
java.srcDir 'generated-src/antlr/main/'
}
}
compileJava.source sourceSets.generated.java, sourceSets.main.java
clean {
delete "generated-src"
}
idea {
module {
sourceDirs += file("generated-src/antlr/main")
}
}
This should be pretty straightforward. A few comments:
- our editor will be based on the RSyntaxTextArea component so we added the corresponding dependency
- we are specifying the version of Kotlin we are using. You do not need to install Kotlin on your system: Gradle will download the compiler and use it based on this configuration
- we are using ANTLR to generate the lexer from our lexer grammar
- we are using the idea plugin: by running ./gradlew idea we can generate an IDEA project. Note that we add the generated code to the list of source directories
- when we run ./gradlew clean we want also to delete the generated code
Changes to the ANTLR lexer
When using a lexer to feed a parser we can safely ignore some tokens. For example, we could want to ignore spaces and comments. When using a lexer for syntax highlighting instead we want to capture all possible tokens. So we need to slightly adapt the lexer grammar we defined in the first post by:
- defining a second channel where we will send the tokens which are useless for the parser but needed for syntax highlighting
- we will add a new real named UNMATCHED to capture all characters which do not belong to correct tokens. This is necessary both because invalid tokens need to be displayed in the editor and because while typing the user would temporarily introduce invalid tokens all the time
The parser will consider only tokens in the default channel, while we will use the default channel and the EXTRA channel in our syntax highlighter.
This is the resulting grammar.
lexer grammar SandyLexer;
@lexer::members {
private static final int EXTRA = 1;
}
// Whitespace
NEWLINE : 'rn' | 'r' | 'n' ;
WS : [t ]+ -> channel(EXTRA) ;
// Keywords
VAR : 'var' ;
// Literals
INTLIT : '0'|[1-9][0-9]* ;
DECLIT : '0'|[1-9][0-9]* '.' [0-9]+ ;
// Operators
PLUS : '+' ;
MINUS : '-' ;
ASTERISK : '*' ;
DIVISION : '/' ;
ASSIGN : '=' ;
LPAREN : '(' ;
RPAREN : ')' ;
// Identifiers
ID : [_]*[a-z][A-Za-z0-9_]* ;
UNMATCHED : . -> channel(EXTRA);
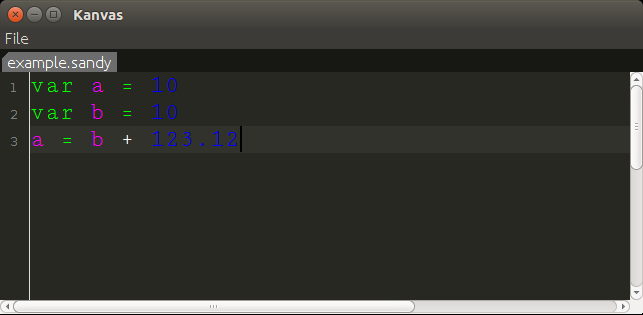
Our editor
Our editor will support syntax highlighting for multiple languages. For now, I have implemented support for Python and for Sandy, the simple language we are working on in this series of post. For implementing syntax highlighting for Python I started from here an ANTLR grammar for Python. I started by removing the parser rules, leaving only the lexer rules. Then U did very minimal changes to get the final lexer present in the repository.
To create the GUI we will need some pretty boring Swing code. We basically need to create a frame with a menu. The frame will contained a tabbed panel. We will have one tab per file. In each tab we will have just one editor, implemented using an RSyntaxTextArea.
fun createAndShowKanvasGUI() {
UIManager.setLookAndFeel(UIManager.getSystemLookAndFeelClassName())
val xToolkit = Toolkit.getDefaultToolkit()
val awtAppClassNameField = xToolkit.javaClass.getDeclaredField("awtAppClassName")
awtAppClassNameField.isAccessible = true
awtAppClassNameField.set(xToolkit, APP_TITLE)
val frame = JFrame(APP_TITLE)
frame.background = BACKGROUND_DARKER
frame.contentPane.background = BACKGROUND_DARKER
frame.defaultCloseOperation = JFrame.EXIT_ON_CLOSE
val tabbedPane = MyTabbedPane()
frame.contentPane.add(tabbedPane)
val menuBar = JMenuBar()
val fileMenu = JMenu("File")
menuBar.add(fileMenu)
val open = JMenuItem("Open")
open.addActionListener { openCommand(tabbedPane) }
fileMenu.add(open)
val new = JMenuItem("New")
new.addActionListener { addTab(tabbedPane, "<UNNAMED>", font) }
fileMenu.add(new)
val save = JMenuItem("Save")
save.addActionListener { saveCommand(tabbedPane) }
fileMenu.add(save)
val saveAs = JMenuItem("Save as")
saveAs.addActionListener { saveAsCommand(tabbedPane) }
fileMenu.add(saveAs)
val close = JMenuItem("Close")
close.addActionListener { closeCommand(tabbedPane) }
fileMenu.add(close)
frame.jMenuBar = menuBar
frame.pack()
if (frame.width < 500) {
frame.size = Dimension(500, 500)
}
frame.isVisible = true
}
fun main(args: Array<String>) {
languageSupportRegistry.register("py", pythonLanguageSupport)
languageSupportRegistry.register("sandy", sandyLanguageSupport)
SwingUtilities.invokeLater { createAndShowKanvasGUI() }
}
Note that in the main function we register support for our two languages. In the future we could envision a pluggable system to support more languages.
The specific support for Sandy is defined in the object sandyLanguageSupport (for Java developers: an object is just a singleton instance of a class). The support needs a SyntaxScheme and an AntlrLexerFactory.
The SyntaxScheme just return the style for each given token type. Quite easy, eh?
object sandySyntaxScheme : SyntaxScheme(true) {
override fun getStyle(index: Int): Style {
val style = Style()
val color = when (index) {
SandyLexer.VAR -> Color.GREEN
SandyLexer.ASSIGN -> Color.GREEN
SandyLexer.ASTERISK, SandyLexer.DIVISION, SandyLexer.PLUS, SandyLexer.MINUS -> Color.WHITE
SandyLexer.INTLIT, SandyLexer.DECLIT -> Color.BLUE
SandyLexer.UNMATCHED -> Color.RED
SandyLexer.ID -> Color.MAGENTA
SandyLexer.LPAREN, SandyLexer.RPAREN -> Color.WHITE
else -> null
}
if (color != null) {
style.foreground = color
}
return style
}
}
object sandyLanguageSupport : LanguageSupport {
override val syntaxScheme: SyntaxScheme
get() = sandySyntaxScheme
override val antlrLexerFactory: AntlrLexerFactory
get() = object : AntlrLexerFactory {
override fun create(code: String): Lexer = SandyLexer(org.antlr.v4.runtime.ANTLRInputStream(code))
}
}
Now, let’s take a look at the AntlrLexerFactory. This factory just instantiate an ANTLR Lexer for a certain language. It can be used together with an AntlrTokenMaker. The AntlrTokenMaker is the adapter between the ANTLR Lexer and the TokenMaker used by the RSyntaxTextArea to process the text. Basically a TokenMakerBase is invoked for each line of the file separately as the line is changed. So we ask our ANTLR Lexer to process just the line and we get the resulting tokens and instantiate the TokenImpl instances which are expected by the RSyntaxTextArea.
interface AntlrLexerFactory {
fun create(code: String) : Lexer
}
class AntlrTokenMaker(val antlrLexerFactory : AntlrLexerFactory) : TokenMakerBase() {
fun toList(text: Segment, startOffset: Int, antlrTokens:List<org.antlr.v4.runtime.Token>) : Token?{
if (antlrTokens.isEmpty()) {
return null
} else {
val at = antlrTokens[0]
val t = TokenImpl(text, text.offset + at.startIndex, text.offset + at.startIndex + at.text.length - 1, startOffset + at.startIndex, at.type, 0)
t.nextToken = toList(text, startOffset, antlrTokens.subList(1, antlrTokens.size))
return t
}
}
override fun getTokenList(text: Segment?, initialTokenType: Int, startOffset: Int): Token {
if (text == null) {
throw IllegalArgumentException()
}
val lexer = antlrLexerFactory.create(text.toString())
val tokens = LinkedList<org.antlr.v4.runtime.Token>()
while (!lexer._hitEOF) {
tokens.add(lexer.nextToken())
}
return toList(text, startOffset, tokens) as Token
}
}
This would be a problem for tokens spanning multiple lines. There are workarounds for that but for now let’s keep the things simple and do not consider that, given that Sandy has not tokens spanning multiple lines.
Conclusions
Of course this editor is not feature complete. However I think it is interesting to see how an editor with syntax highlighting can be built with a couple of hundreds of lines of quite simple Kotlin code.
In future posts we will see how to enrich this editor building things like auto-completion.
Read more:
If you want to understand how to use ANTLR, you can read our article The ANTLR Mega Tutorial.