
In this post we are going to see how to build autocompletion in our editor. We will derive the items to suggest automatically from our ANTLR grammar.
This post is the part of a series. The goal of the series is to describe how to create a useful language and all the supporting tools.
- Building a lexer
- Building a parser
- Creating an editor with syntax highlighting
- Build an editor with autocompletion
- Mapping the parse tree to the abstract syntax tree
- Model to model transformations
- Validation
- Generating bytecode
After writing this series of posts I refined my method, expanded it, and clarified into this book titled How to create pragmatic, lightweight languages
Code
Code is available on GitHub. The code described in this post is associated to the tag autocompletion
How this will work
The main point here is that we need to understand what kind of token could follow the caret. These are the relevant interfaces:
interface TokenType {
val type : Int
}
interface EditorContext {
fun preceedingTokens() : List<Token>
}
/**
* The goal of this is to find the type of tokens that can be used in a given context
*/
interface AutoCompletionSuggester {
fun suggestions(editorContext: EditorContext) : Set<TokenType>
}
EditorContext will describe what precedes the caret. It will basically be a list of tokens.
How can we find those tokens? By using the ANTLR lexer on all the text preceding the caret. We then take all the tokens from the channel 0 (the default channel: we are not interested in comments or whitespace) and put them in a list. Now, the last token will be the EOF token representing the end of the stream we sent to the lexer. We put instead a special token of type CARET_TOKEN_TYPE.
class EditorContextImpl(val code: String, val antlrLexerFactory: AntlrLexerFactory) : EditorContext {
override fun preceedingTokens(): List<Token> {
val lexer = antlrLexerFactory.create(code)
return lexer.toList()
}
}
val CARET_TOKEN_TYPE = -10
fun Lexer.toList() : List<Token> {
val res = LinkedList<Token>()
do {
var next = this.nextToken()
if (next.channel == 0) {
if (next.type < 0) {
next = CommonToken(CARET_TOKEN_TYPE)
}
res.add(next)
}
} while (next.type >= 0)
return res
}
Now it comes the funny part: we are going to simulate the choices of our ANTLR parser and then look which tokens it would expect to keep parsing.
class AntlrAutoCompletionSuggester(val ruleNames: Array<String>, val vocabulary: Vocabulary, val atn: ATN) : AutoCompletionSuggester {
override fun suggestions(editorContext: EditorContext): Set<TokenType> {
val collector = Collector()
process(ruleNames, vocabulary, atn.states[0], MyTokenStream(editorContext.preceedingTokens()), collector, ParserStack())
return collector.collected()
}
}
All the magic happen in the process function. To it we pass ruleNames and vocabulary which are just needed for debugging. We then pass the initial ATN state. ATN is an internal structure used by the ANTLR parser. It represents an automata that can change state through epsilon transitions or when a certain token is received. We will start from the initial state and process the tokens we have in front of us until we reach the special token representing the caret. At that point we will look which transitions are available in the current state. The tokens used by those transitions are the tokens the parser would expect and therefore they will be the tokens we will suggest to the user.
Note that multiple transitions are possible from some states so we will follow all possible paths. We will collect all suggestions using the collector object. At this stage we are not concern about performance issue. In practice we may want to use some form of caching.
There is another object we did not discuss: it is the ParserStack instance. It is needed to track the path followed by the automata. This is because certain transitions should be followed only if the parser arrives from a certain path. For example at the end of an expression we may want to recognize a right parenthesis to complete parsing an expression surrounded by parenthesis. However this makes sense only if we have recognized a left parenthesis before. The ParserStack tell us that.
Let’s start by looking at the function process:
private fun process(ruleNames: Array<String>, vocabulary: Vocabulary,
state: ATNState, tokens: MyTokenStream, collector: Collector,
parserStack: ParserStack,
alreadyPassed: Set<Int> = HashSet<Int>(), history : List<String> = listOf("start")) {
val atCaret = tokens.atCaret()
val stackRes = parserStack.process(state)
if (!stackRes.first) {
return
}
state.transitions.forEach {
val desc = describe(ruleNames, vocabulary, state, it)
when {
it.isEpsilon -> {
if (!alreadyPassed.contains(it.target.stateNumber)) {
process(ruleNames, vocabulary, it.target, tokens, collector, stackRes.second,
alreadyPassed.plus(it.target.stateNumber),
history.plus(desc))
}
}
it is AtomTransition -> {
val nextTokenType = tokens.next()
if (atCaret) {
if (isCompatibleWithStack(it.target, parserStack)) {
collector.collect(it.label)
}
} else {
if (nextTokenType.type == it.label) {
process(ruleNames, vocabulary, it.target, tokens.move(), collector, stackRes.second, HashSet<Int>(), history.plus(desc))
}
}
}
it is SetTransition -> {
val nextTokenType = tokens.next()
it.label().toList().forEach { sym ->
if (atCaret) {
if (isCompatibleWithStack(it.target, parserStack)) {
collector.collect(sym)
}
} else {
if (nextTokenType.type == sym) {
process(ruleNames, vocabulary, it.target, tokens.move(), collector, stackRes.second, HashSet<Int>(), history.plus(desc))
}
}
}
}
else -> throw UnsupportedOperationException(it.javaClass.canonicalName)
}
}
}
We start by checking if we have reached the caret (in that case atCaret will be true). We then pass the current state to the stack to be processed: in many cases it will just add the state at the top of the stack. However some states are used to match previously states. They sort of close some operation which was started by another state that should be on the top of the stack. If the matching state is found on top of the stack it is removed, if it is not found it means this parsing path is unsuccessful and we abort it.
If the parsing path has not been aborted we look at all the transitions leaving the current state. We just follow all the epsilon transitions (with a small caveat to avoid infinite loops: see the alreadyPassed variable). If instead we have an AtomTransition it means that the transition needs a specific token:
- if we have not yet reached the caret we look at the next token in the stream: if it match the one required by the transition we follow it, otherwise we don’t
- if we have reached the caret this is a potential next token, so we collect it. We just check if the state at the end of the transition is compatible with our current stack
Let’s now look at ParserStack:
class ParserStack(val states : List<ATNState> = emptyList()) {
fun process(state: ATNState) : Pair<Boolean, ParserStack> {
return when (state) {
is RuleStartState, is StarBlockStartState, is BasicBlockStartState, is PlusBlockStartState, is StarLoopEntryState -> {
return Pair(true, ParserStack(states.plus(state)))
}
is BlockEndState -> {
if (states.last() == state.startState) {
return Pair(true, ParserStack(states.minusLast()))
} else {
return Pair(false, this)
}
}
is LoopEndState -> {
val cont = states.last() is StarLoopEntryState && (states.last() as StarLoopEntryState).loopBackState == state.loopBackState
if (cont) {
return Pair(true, ParserStack(states.minusLast()))
} else {
return Pair(false, this)
}
}
is RuleStopState -> {
val cont = states.last() is RuleStartState && (states.last() as RuleStartState).stopState == state
if (cont) {
return Pair(true, ParserStack(states.minusLast()))
} else {
return Pair(false, this)
}
}
is BasicState, is BlockEndState,is StarLoopbackState, is PlusLoopbackState -> return Pair(true, this)
else -> throw UnsupportedOperationException(state.javaClass.canonicalName)
}
}
}
private fun isCompatibleWithStack(state: ATNState, parserStack:ParserStack) : Boolean {
val res = parserStack.process(state)
if (!res.first) {
return false
}
if (state.epsilonOnlyTransitions) {
return state.transitions.any { isCompatibleWithStack(it.target, res.second) }
} else {
return true
}
}
Depending on the states we:
- ignore them (e.g., BasicState)
- add them at the top of the stack (e.g., RuleStartState)
- check if a corresponding state is at the top of the stack. If it is matched we remove the previous state from the stack. If it is not matched we return a Pair starting with false to indicate an error.
The nice thing about this algorithm is that is completely generic: we can reuse it for all of our languages. We will just need an instance of LanguageSupport to tell us how to instantiate the lexer, the parser and get some other data. This is the instance for our toy language, Sandy.
object sandyLanguageSupport : LanguageSupport {
override val syntaxScheme: SyntaxScheme
get() = sandySyntaxScheme
override val antlrLexerFactory: AntlrLexerFactory
get() = object : AntlrLexerFactory {
override fun create(code: String): Lexer = SandyLexer(org.antlr.v4.runtime.ANTLRInputStream(code))
}
override val parserData: ParserData?
get() = ParserData(SandyParser.ruleNames, SandyLexer.VOCABULARY, SandyParser._ATN)
}
Testing
No solution is complete without tests, right?
Let’s see some simple test. Given a certain piece of code preceeding the caret we expect our algorithm to suggest certain tokens.
class CompletionTest {
@test fun emptyFile() {
val code = ""
assertEquals(setOf(TokenTypeImpl(SandyLexer.VAR), TokenTypeImpl(SandyLexer.ID)), AntlrAutoCompletionSuggester(SandyParser.ruleNames,SandyLexer.VOCABULARY,SandyParser._ATN)
.suggestions(EditorContextImpl(code, sandyLanguageSupport.antlrLexerFactory)))
}
@test fun afterVar() {
val code = "var"
assertEquals(setOf(TokenTypeImpl(SandyLexer.ID)), AntlrAutoCompletionSuggester(SandyParser.ruleNames,SandyLexer.VOCABULARY,SandyParser._ATN)
.suggestions(EditorContextImpl(code, sandyLanguageSupport.antlrLexerFactory)))
}
@test fun afterEquals() {
val code = "var a ="
assertEquals(setOf(TokenTypeImpl(SandyLexer.INTLIT), TokenTypeImpl(SandyLexer.DECLIT), TokenTypeImpl(SandyLexer.MINUS)
, TokenTypeImpl(SandyLexer.LPAREN), TokenTypeImpl(SandyLexer.ID)), AntlrAutoCompletionSuggester(SandyParser.ruleNames,SandyLexer.VOCABULARY,SandyParser._ATN)
.suggestions(EditorContextImpl(code, sandyLanguageSupport.antlrLexerFactory)))
}
@test fun afterLiteral() {
val code = "var a = 1"
assertEquals(setOf(TokenTypeImpl(SandyLexer.NEWLINE), TokenTypeImpl(SandyLexer.EOF), TokenTypeImpl(SandyLexer.PLUS), TokenTypeImpl(SandyLexer.MINUS), TokenTypeImpl(SandyLexer.DIVISION), TokenTypeImpl(SandyLexer.ASTERISK)),
AntlrAutoCompletionSuggester(SandyParser.ruleNames,SandyLexer.VOCABULARY,SandyParser._ATN)
.suggestions(EditorContextImpl(code, sandyLanguageSupport.antlrLexerFactory)))
}
@test fun incompleteAddition() {
val code = "var a = 1 +"
assertEquals(setOf(TokenTypeImpl(SandyLexer.LPAREN), TokenTypeImpl(SandyLexer.ID), TokenTypeImpl(SandyLexer.MINUS), TokenTypeImpl(SandyLexer.INTLIT), TokenTypeImpl(SandyLexer.DECLIT)), AntlrAutoCompletionSuggester(SandyParser.ruleNames,SandyLexer.VOCABULARY,SandyParser._ATN)
.suggestions(EditorContextImpl(code, sandyLanguageSupport.antlrLexerFactory)))
}
}
Integrating in the UI
Ok, now we now which kinds of token should follow the caret. How we go from there to an autocompletion function that we can use in our editor?
We will use the autocomplete extension for RSyntaxTextArea (see the build.gradle file on GitHub). We have to instantiate a CompletionProvider and attach it to our text editor. We do this in the function instantiate the text editor for every tab.
val provider = createCompletionProvider(languageSupport)
val ac = AutoCompletion(provider)
ac.install(textArea)
The instance of the CompletionProvider will call our AntlrAutoCompletionSuggester, using the specific LanguageSupport corresponding to the language used in the given tab (it is derived from the file extension).
fun createCompletionProvider(languageSupport: LanguageSupport): CompletionProvider {
val cp = object : CompletionProviderBase() {
override fun getCompletionsAt(comp: JTextComponent?, p: Point?): MutableList<Completion>? {
throw UnsupportedOperationException("not implemented") //To change body of created functions use File | Settings | File Templates.
}
override fun getParameterizedCompletions(tc: JTextComponent?): MutableList<ParameterizedCompletion>? {
throw UnsupportedOperationException("not implemented") //To change body of created functions use File | Settings | File Templates.
}
private val seg = Segment()
private val autoCompletionSuggester = AntlrAutoCompletionSuggester(languageSupport.parserData!!.ruleNames,
languageSupport.parserData!!.vocabulary, languageSupport.parserData!!.atn)
private fun beforeCaret(comp: JTextComponent) : String {
val doc = comp.document
val dot = comp.caretPosition
val root = doc.defaultRootElement
val index = root.getElementIndex(dot)
val elem = root.getElement(index)
var start = elem.startOffset
val len = dot - start
return doc.getText(start, len)
}
override fun getCompletionsImpl(comp: JTextComponent): MutableList<Completion>? {
val retVal = ArrayList<Completion>()
val code = beforeCaret(comp)
autoCompletionSuggester.suggestions(EditorContextImpl(code, languageSupport.antlrLexerFactory)).forEach {
if (it.type != -1) {
var proposition : String? = languageSupport.parserData!!.vocabulary.getLiteralName(it.type)
if (proposition != null) {
if (proposition.startsWith("'") && proposition.endsWith("'")) {
proposition = proposition.substring(1, proposition.length - 1)
}
retVal.add(BasicCompletion(this, proposition))
}
}
}
return retVal
}
protected fun isValidChar(ch: Char): Boolean {
return Character.isLetterOrDigit(ch) || ch == '_'
}
override fun getAlreadyEnteredText(comp: JTextComponent): String {
val doc = comp.document
val dot = comp.caretPosition
val root = doc.defaultRootElement
val index = root.getElementIndex(dot)
val elem = root.getElement(index)
var start = elem.startOffset
var len = dot - start
try {
doc.getText(start, len)
} catch (ble: BadLocationException) {
ble.printStackTrace()
return EMPTY_STRING
}
val segEnd = seg.offset + len
start = segEnd - 1
while (start >= seg.offset && seg.array != null && isValidChar(seg.array[start])) {
start--
}
start++
len = segEnd - start
return if (len == 0) EMPTY_STRING else String(seg.array, start, len)
}
}
return cp
}
What we do here is getting all the text preceding the caret to pass it to the autoCompletionSuggester. When we get back the type of tokens we ignore EOF (type -1) and we translate the others in the corresponding piece of text by calling vocabulary.getLiteralName and removing the apexes.
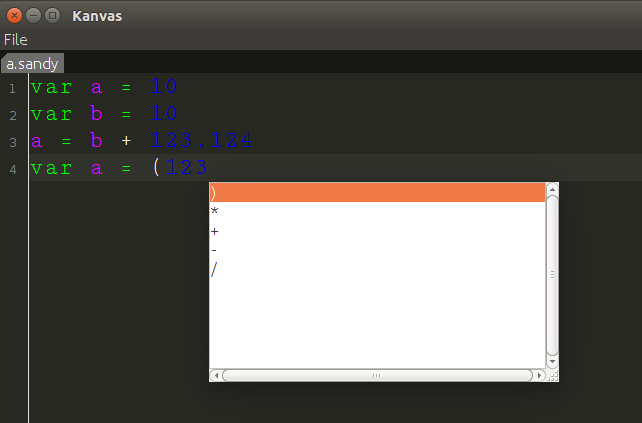
Here we go!
Conclusions
We have seen that we can implement autocompletion in a generic way: the algorithm we have defined can be reused with any ANTLR language. This is a very important point because we are building an infrastructure to provide free tool support for any new language we are going to define.
Our approach is simple and it requires a small amount of neat Kotlin code to be implemented. There are some refinements to do because the current solution suggests static tokens but it does not suggest references which are accessible in a certain point. For that we would need more information about the semantics of the language and its scoping rules. This is beyond the scope of this introduction but it something we could discuss in the future.
Some references you may want to take a look at: