
In this article we share with you what we have learned from building tens of commercial parsers for clients all over the world, from startups, to Fortune 500 companies, supporting different use-cases: editors, interpreters, transpilers, and other supporting tools. We will share how to build advanced parsers using Kolasu.
This approach is based on ANTLR but there is more to it. We rely indeed on an open-source library we created, named Kolasu. Using Kolasu we build the Abstract Syntax Tree (AST) layer on top of the first-stage parser built with ANTLR. This permits us to expose a high-level model of the code, simplifying the implementation of all those applications built on top of parsers: from editors to interpreters, from compilers to transpilers.
In this article, we start from an existing open-source grammar for the Python language and we show how to build a complete parser with Kolasu and then create a simple linter. We will show each step and share with you the tools we use to simplify our work and the way we think about these projects: how we build them, how we test them, which APIs we use to traverse the tree, and so on. We hope we will be able to share information useful to you to build your own projects.
As it is always the case with our tutorials you can find all the code on GitHub: https://github.com/Strumenta/kolasu-tutorial
Kolasu: what can it be used for?
There are different applications that need a parser to work:
- Interpreters, compilers, and transpilers: we need to recognize the code and build a model to later execute it (interpreters), translate it into machine code or bytecode (compilers), or translate it into a different language (transpilers)
- Editors: they need a parser to support “code intelligence” features, for example to identify errors and provide functionalities such as autocompletion
- Code Analysis and Code Refactoring applications: if you want to identify issues in the code you need first to parse it to recognize its components. At that point, you can analyze it and possibly improve it automatically.
These applications are all valuable to different stakeholders. Parsers instead are not useful per se: they are useful only to support the creation of those applications. Given their reason to exist is to facilitate the creation of those applications, we should ensure that the parsers we build serve this purpose well.
We think two elements are particularly important:
- Providing a good, high-level model of the code, corresponding to how a developer interprets the code. This model is called Abstract Syntax Tree (AST)
- Providing a good API to traverse, modify, serialize, and process such model
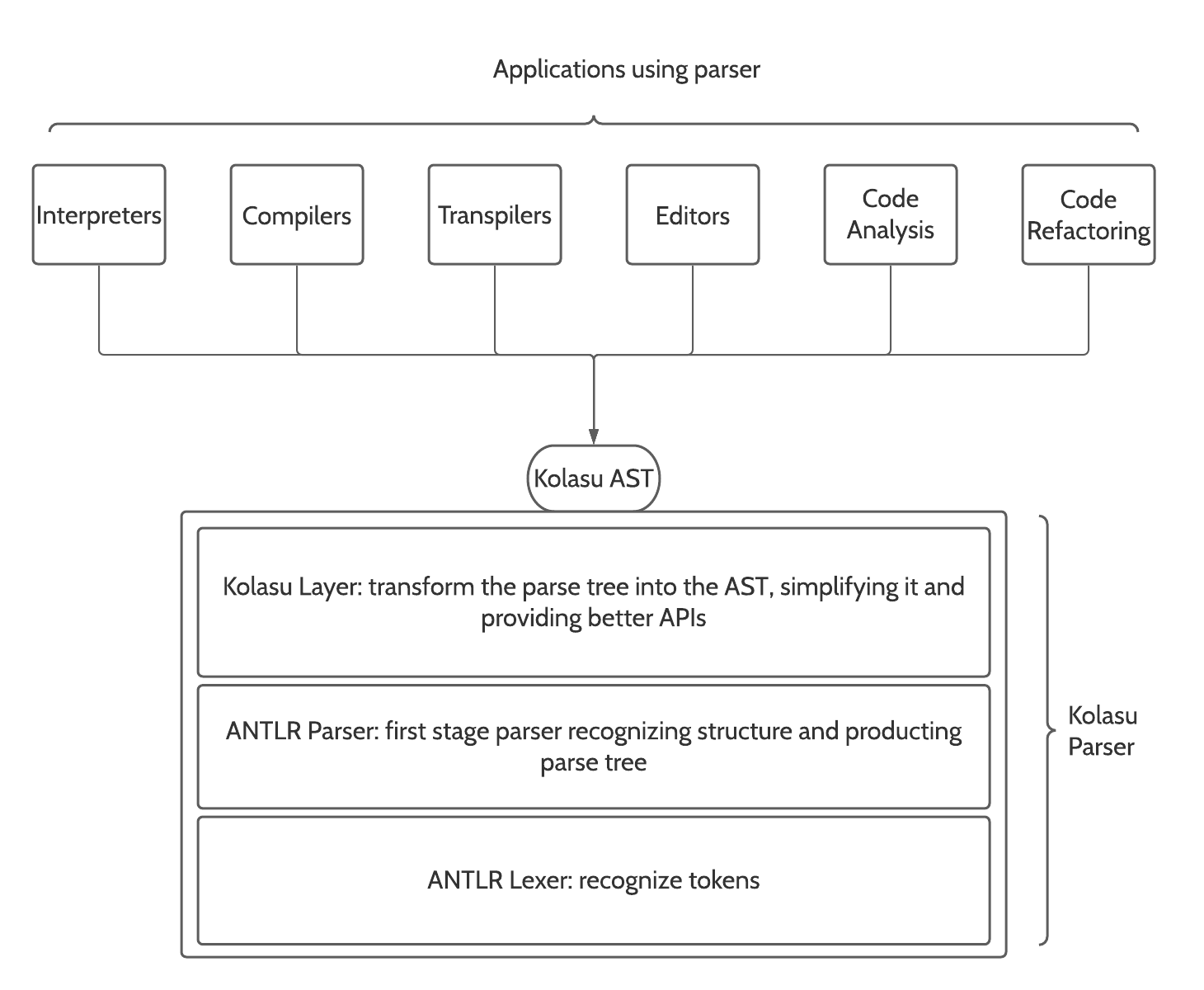
We use Kolasu in combination with ANTLR lexers and parsers. We can think of Kolasu as an adaptation layer which transforms the ANTLR’s output, called parse-tree, into a structure that facilitates the work of those who need to build the applications, producing more maintainable code.
Setup a project with Kolasu
Over time we’ve defined a way to organize projects based on Kolasu which works well. Given every year we build several parsers, and we want to build them in a repeatable way, we created a Yeoman generator that will set up the skeleton of the project for you.
In this tutorial, we will write a parser using Kotlin, a language we frequently work with. We are planning to write generators also for TypeScript, Java, Python, and other languages.
To use the generator for Kolasu parser projects you will need:
- To have Node.js and npm installed
- To install the yeoman tool (yo)
- To install the parser generator we developed
Npm stands for node package manager. We need both Node.js and npm as yeoman is a Node.js application that we can install through npm.
Node.js can be installed in different ways but we suggest using nvm: https://github.com/nvm-sh/nvm#installing-and-updating
To install npm, in case you are using nvm you can run:
nvm install-latest-npm
You can install the yeoman tool and the parser generator with this command:
npm install -g yo generator-parser
If this worked out running yo parser –help you should get:

If it is now working we can get started for real.
Let’s now create a directory named python3parser. We will store our project there. We move to that directory and we run:
yo parser
Let’s pick Python3 as the language name and keep the suggested package name.
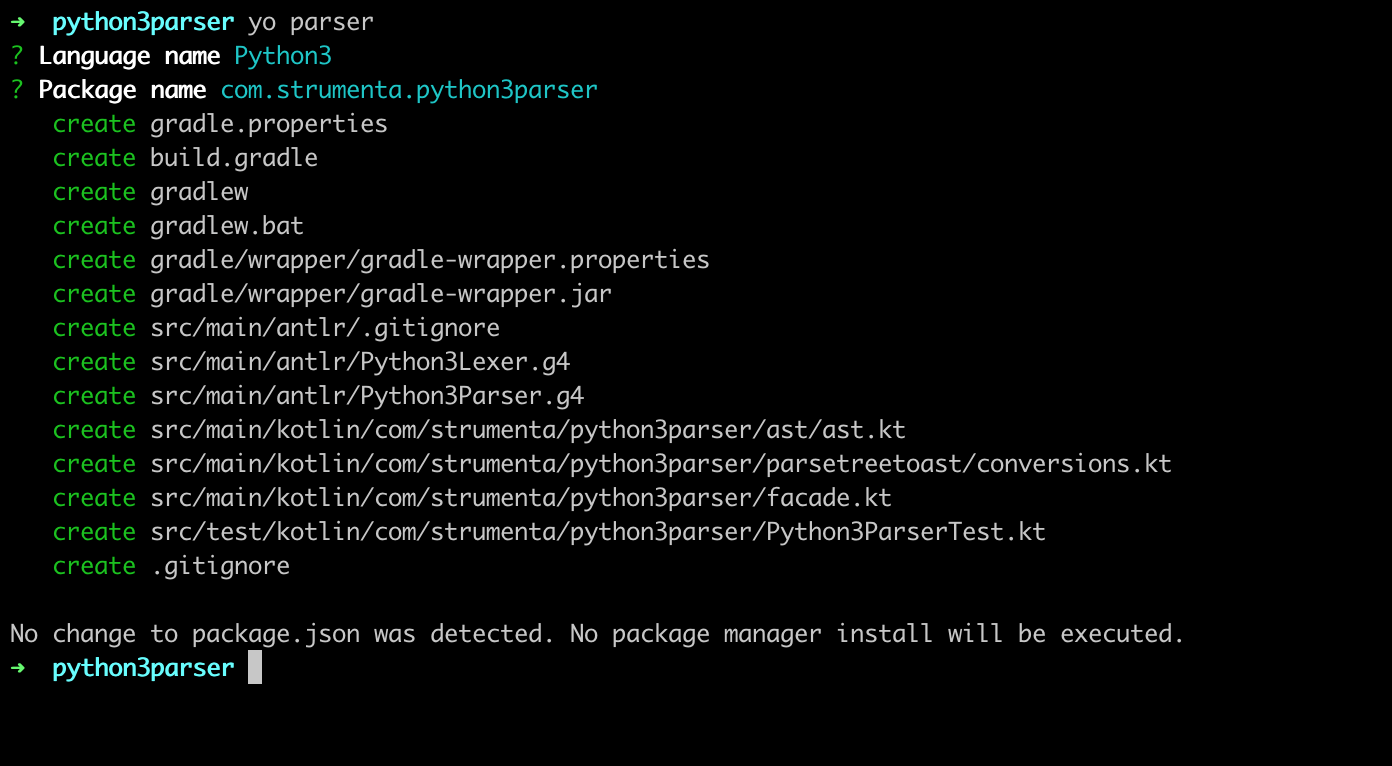
The generated project:
- Uses the gradle build tool and comes with the gradle wrapper
- Contains a sample lexer and parser grammars which are very simple
- It contains some code and some tests
The tests verify the sample parser works at three levels:
- It verifies the lexer produces the list of tokens we expect
- It verifies the first stage parser (the one built with ANTLR) can produce the parse tree we expect it to build
- It verifies the kolasu parser produces the AST we expect it to build
At this point we may also apply formatting by running:
./gradlew ktlintFormat
We verify everything is working as expected by running:
./gradlew check
You can find the corresponding code under the git tag 01_skeleton_generation (reminder: the repository is at https://github.com/Strumenta/kolasu-tutorial).
Importing Python 3 grammar
We will now use existing Python3 grammars for ANTLR from https://github.com/antlr/grammars-v4/tree/master/python/python3
We will need to download three files:
- https://github.com/antlr/grammars-v4/blob/master/python/python3/Python3Lexer.g4
- https://github.com/antlr/grammars-v4/blob/master/python/python3/Python3Parser.g4
- https://github.com/antlr/grammars-v4/blob/master/python/python3/Java/Python3LexerBase.java
The first two files will replace the corresponding files in src/main/antlr.
For the third one we will create the directory src/main/java and under it we will create the package com.strumenta.python3parser. There we will copy the file Python3LexerBase.java. This is a class containing special handling of the indentation, because as you know it is relevant in Python. We will need to set the package by adding this statement at the top of the file:
package com.strumenta.python3parser;
Now we can adapt the code.
We start by revising the Kolasu parser:
class Python3KolasuParser : KolasuParser<CompilationUnit, Python3Parser, Python3Parser.File_inputContext>() {
override fun createANTLRLexer(inputStream: InputStream): Lexer {
return Python3Lexer(CharStreams.fromStream(inputStream))
}
override fun createANTLRParser(tokenStream: TokenStream): Python3Parser {
return Python3Parser(tokenStream)
}
override fun invokeRootRule(parser: Python3Parser): Python3Parser.File_inputContext? {
return parser.file_input()
}
override fun parseTreeToAst(parseTreeRoot: Python3Parser.File_inputContext, considerPosition: Boolean): CompilationUnit? {
TODO()
}
}
We specify the root rule of the parse tree we will use. We can find it out by inspecting the Python3Parser.g4 grammar and identifying the rule used to parse entire Python files:
file_input: (NEWLINE | stmt)* EOF;
For the moment we specify we do not know yet how we will convert the parse tree into the AST, so we place a TODO call in the method parseTreeToAst.
This conversion will be defined in the file conversions.kt. For the moment we remove everything from it, leaving just the package declaration at the top of the file.
Now we will focus on tests:
- We will remove the existing example example1.hello and use a Python file instead (plates.py).
- We will update tests to refer to this example. We will leave only the tests running on files, removing the ones running on strings
- We will delete Python3LexerTest
We can use this Python file in our tests: https://raw.githubusercontent.com/Mindwerks/worldengine/master/worldengine/plates.py
It comes from an old open-source project of mine.
We remove the lexer tests because we will not need them. We typically write lexer tests when developing new grammars and to debug complex issues, but in most cases they are not as necessary as tests for the parse tree and the AST.
We will get these two test files, which at the time are not passing:
class Python3FirstStageParserTest {
@Test
fun parsePlatesFromFile() {
val kolasuParser = Python3KolasuParser()
val result = kolasuParser.parseFirstStage(this.javaClass.getResourceAsStream("/plates.py"))
assertEquals(true, result.correct)
assertEquals(true, result.issues.isEmpty())
assertParseTreeStr(
"""CompilationUnit
| HelloStmt
| T:HELLO[hello]
| T:ID[John]
| T:EOF[<EOF>]""".trimMargin("|"),
result.root!!, Python3Parser.VOCABULARY
)
}
}
class Python3KolasuParserTest {
@Test
fun parsePlatesFromFile() {
val kolasuParser = Python3KolasuParser()
val result = kolasuParser.parse(
this.javaClass.getResourceAsStream("/plates.py"),
considerPosition = false
)
assertEquals(true, result.correct)
assertEquals(true, result.issues.isEmpty())
assertASTsAreEqual(CompilationUnit(listOf(HelloStmt("John"))), result.root!!)
}
}
At this point, we could run ./gradlew generateGrammarSource to generate the ANTLR lexer and parser.
This point corresponds to git tag 02_python_grammars.
Testing the parse tree
Let’s look at the first test, the test for the parse tree. It fails obviously but the log it produces is interesting. It prints the parse tree and we can see how complex it is. Consider for example the parameter sea_level with default value 0.65. It is defined in line 13 of plates.py. The corresponding snippet of the parse tree for the parameter declaration is this:
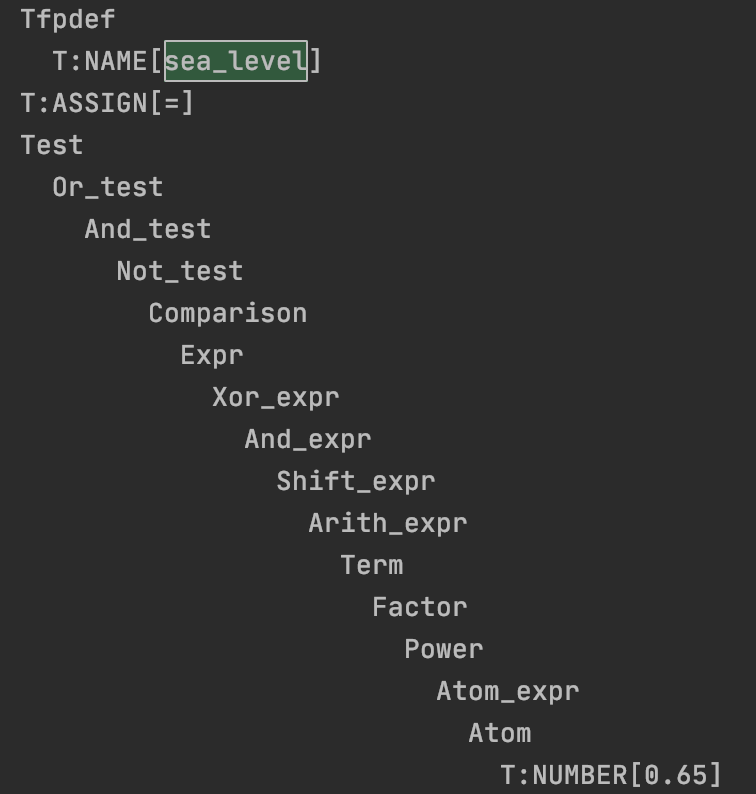
Now, a very simple integer constant leads to a parse tree that is that complicated. This is a typical consequence of defining precedence rules in the grammar by using multiple levels of expressions. In general, this could be avoided in most cases by rewriting the grammar taking advantage of ANTLR4 features for rules precedence, but it is not always strictly possible. In general, however we will always have some complications appearing in the parse tree and we will not like to expose our applications to it. This is exactly why we are going to define an AST.
We cannot test the parse tree for the whole file: it would be simply huge and unmaintainable. Let’s write a parse-tree test for a very, very simple piece of python code:
@Test
fun parseSimpleFunctionFromString() {
val code = """def foo(a, b=10):
| pass
""".trimMargin("|")
val parserFacade = Python3KolasuParserFacade()
val result = parserFacade.parseFirstStage(code)
assertEquals(true, result.correct)
assertEquals(true, result.issues.isEmpty())
assertParseTreeStr(
"""File_input
| Stmt
| Compound_stmt
| Funcdef
| T:DEF[def]
| T:NAME[foo]
| Parameters
| T:OPEN_PAREN[(]
| Typedargslist
| Tfpdef
| T:NAME[a]
| T:COMMA[,]
| Tfpdef
| T:NAME[b]
| T:ASSIGN[=]
| Test
| Or_test
| And_test
| Not_test
| Comparison
| Expr
| Xor_expr
| And_expr
| Shift_expr
| Arith_expr
| Term
| Factor
| Power
| Atom_expr
| Atom
| T:NUMBER[10]
| T:CLOSE_PAREN[)]
| T:COLON[:]
| Suite
| T:NEWLINE[ ]
| T:INDENT[ ]
| Stmt
| Simple_stmt
| Small_stmt
| Pass_stmt
| T:PASS[pass]
| T:NEWLINE[s]
| T:DEDENT[s]
| T:EOF[ pass]""".trimMargin("|"), result.root!!, Python3Parser.VOCABULARY)
}
A couple of lines of Python code are transformed into a very involved parse tree.
The way we write these tests is by running the tests with a bogus expected parse tree and then manually check the actual parse tree. The parseFirstStage method also verifies we consumed the whole stream, a detail that is important to consider. We also verify there are no errors by checking the correct field. If it seems correct after the manual inspection we copy it as the expected parse tree. We could then manually derive more tests from that initial test. For example, changing a few expressions or statements and updating the expected parse tree. These tests will help us ensure that possible future changes to the grammar do not lead to unexpected changes in the generated parse tree. In general, these tests are difficult to maintain and we mostly focus on tests of the AST. The complexity of the parse tree tests is related to the quality of the grammar: a well-written grammar would lead to simple parse trees and simpler tests. In this case, there is space for improvement.
This point corresponds to git tag 03_parse_tree_test.
Goal: building a simple linter for Python
Before moving forward with the code let’s focus on our goal.
We want to build a simple linter: an application that will take as input the path to a Python file or a directory containing Python files. The application will check all the relevant Python files and report possible issues.
The things we are going to check are simple:
- If a file is too long
- If a file contains too many top-level functions
- If a function contains too many parameters
- If a parameter appears to be unused
For example, when running it on our plates.py file we will get this output:
[File src/test/resources/plates.py]
[HIGH] Way too many parameters in function generate_plates_simulation
[HIGH] Way too many parameters in function _plates_simulation
[HIGH] Way too many parameters in function world_gen
When running it instead against this simple file (called params_usage.py):
def fun1(p1, p2, p3): return p1 + p3 def fun2(param): a = param b = not_a_param
It will produce this output:
[File src/test/resources/params_usage.py] [MEDIUM] Unused parameter p2 in fun1
But how will we perform this analysis?
We will need to build a model of the code that will allow us to answer some questions easily. For example:
- How many top-level functions there are in a file
- How many parameters a file is declaring?
- Which parameters are unused in a function declaration?
We will build such a model, that will be our AST. We are now going to see how we will build it.
Defining AST
When defining the AST we typically start from the top: by defining the root representing the whole file. We call it CompilationUnit.
Initial version
Our CompilationUnit will contain a list of top-level statements. It will be an AST Node, so it will extend the class Node. We always add a parameter named specifiedPosition to our nodes.
data class CompilationUnit( val stmts: List<Statement>, override val specifiedPosition: Position? = null ) : Node(specifiedPosition)
At this point we would need to define Statement. In most languages we have two important families of nodes: Statements and Expressions. Those families originate from an abstract class. We start defining it and then we will list below the different subclasses:
sealed class Statement(override val specifiedPosition: Position? = null) : Node(specifiedPosition) sealed class Expression(override val specifiedPosition: Position? = null) : Node(specifiedPosition)
We then start looking at our examples, plates.py. We notice that we want to recognize one particular kind of statement that will be relevant for us: Function declarations.
data class FunctionDeclaration( override val name: String, val params: List<ParameterDeclaration>, val body: List<Statement>, override val specifiedPosition: Position? = null ) : Statement(specifiedPosition), Named
A FunctionDeclaration will contain a body, made of statements, but it will also contain a list of parameter declarations.
data class ParameterDeclaration( override val name: String, val defaultValue: Expression? = null, override val specifiedPosition: Position? = null ) : Statement(specifiedPosition), Named
We revise the AST test:
class Python3KolasuParserTest {
@Test
fun parsePlatesFromFile() {
val kolasuParser = Python3KolasuParser()
val result = kolasuParser.parse(
this.javaClass.getResourceAsStream("/plates.py"),
considerPosition = false
)
assertEquals(true, result.correct)
assertEquals(true, result.issues.isEmpty())
TODO()
}
}
We also add the example params_usage.py that we presented earlier.
This point corresponds to git tag 04_initial_ast.
Expanding the AST
At this point we typically would proceed by identifying small examples and writing tests around them, defining new elements of the AST and the conversion from parse tree to AST, as we face new examples.
To simplify the explanation however we will now proceed to expand the AST before looking into tests.
We will:
- Add new elements to the AST
- Define the conversion from parse tree to AST
- Revise KolasuParser to invoke the conversion
In the AST we start by revising CompilationUnit:
data class CompilationUnit(
val stmts: List<Statement>,
override val specifiedPosition: Position? = null
) : Node(specifiedPosition) {
@Derived
val topLevelFunctions
get() = stmts.filterIsInstance(FunctionDeclaration::class.java)
}
What we have done is adding a relation that is derived. It means that it is a sort of view, of projection of a real relationship, so it could be treated differently for certain operations like serialization.
This derived relation returns all function declarations appearing directly as children of the compilation unit, in other words, all top-level functions.
We then introduce some statements which we are sure to encounter:
data class IfStatement( val condition: Expression, val body: List<Statement>, override val specifiedPosition: Position? = null ) : Statement(specifiedPosition) data class WhileStatement( val condition: Expression, val body: List<Statement>, override val specifiedPosition: Position? = null ) : Statement(specifiedPosition) data class ExpressionStatement(val expression: Expression, override val specifiedPosition: Position? = null) : Statement(specifiedPosition) data class ReturnStatement(val value: Expression?, override val specifiedPosition: Position? = null) : Statement(specifiedPosition)
One important statement here is the ExpressionStatement, which is present in most languages. It represents a sort of adapter because it permits to use an expression where a statement is expected. It is typically used to represent those expressions that are used for their side effects, for example, function calls.
We then focus on expressions:
data class NumberLiteral(val value: String, override val specifiedPosition: Position? = null) : Expression(specifiedPosition)
data class ReferenceExpression(val reference: String, override val specifiedPosition: Position? = null) : Expression(specifiedPosition) {
val isParameterReference: Boolean
get() = this.findAncestorOfType(FunctionDeclaration::class.java)?.params?.any { it.name == reference } ?: false
}
data class ArrayLiteral(val elements: List<Expression>, override val specifiedPosition: Position? = null) : Expression(specifiedPosition)
data class FunctionInvocation(
val function: Expression,
val paramValues: List<ParameterAssignment>,
override val specifiedPosition: Position? = null
) : Expression(specifiedPosition)
data class FieldAccess(val container: Expression, val fieldName: String, override val specifiedPosition: Position? = null) : Expression(specifiedPosition)
data class BooleanLiteral(val value: Boolean, override val specifiedPosition: Position? = null) : Expression(specifiedPosition)
data class StringLiteral(val value: String, override val specifiedPosition: Position? = null) : Expression(specifiedPosition)
data class AssignmentExpression(val assigned: Expression, val value: Expression, override val specifiedPosition: Position? = null) :
Expression(specifiedPosition)
enum class ComparisonOp {
LESS_THAN(),
LESS_EQ(),
GREATER_THAN(),
GREATER_EQ(),
EQUAL();
companion object {
fun from(text: String): ComparisonOp {
return when (text) {
"==" -> EQUAL
else -> TODO()
}
}
}
}
data class ComparisonExpr(val op: ComparisonOp, val left: Expression, val right: Expression, override val specifiedPosition: Position? = null) :
Expression(specifiedPosition)
data class AdditionExpression(val left: Expression, val right: Expression, override val specifiedPosition: Position? = null) :
Expression(specifiedPosition)
data class SubtractionExpression(val left: Expression, val right: Expression, override val specifiedPosition: Position? = null) :
Expression(specifiedPosition)
data class TupleExpression(val elements: List<Expression>, override val specifiedPosition: Position? = null) : Expression(specifiedPosition)
data class ParameterAssignment(val value: Expression, val name: String? = null, override val specifiedPosition: Position? = null) : Node(specifiedPosition)
data class NoneLiteral(override val specifiedPosition: Position? = null) : Expression(specifiedPosition)
These expressions are quite typical, and they appear in most languages.
We have:
- Literals: NumberLiteral, ArrayLiteral, BooleanLiteral, StringLiteral, NoneLiteral. We could also consider TupleExpression as a literal. They all represent immediate values
- We have binary operations: AdditionExpression, SubtractionExpression, ComparisonExpr. They all represent combinations of values
- We then have other common expressions such as ReferenceExpression, FunctionInvocation, AssignmentExpression, and FieldAccess
Now let’s look into how we convert the parse tree produced by ANTLR into the AST composed by the nodes we just defined. This happens in conversion.kt. We create extension methods for each type of parse tree node.
We focus on cover only the case we encounter and we complete the conversion as we encounter more cases. Let’s see some examples. You can refer to the repository to see the whole code.
Let’s start from the beginning:
fun Python3Parser.File_inputContext.toAst(considerPosition: Boolean = true): CompilationUnit {
return CompilationUnit(
this.stmt().map { it.toAst(considerPosition) }.flatten(),
toPosition(considerPosition)
)
}
GIven a File_inputContext we want to get a CompilationUnit. How? We just need to convert all statements in the parse tree node into AST statements. You may also notice that this conversion can include or not the position. Typically we want the generated AST nodes to include their position but in some cases, we don’t, for example in tests, where it would make the comparison more complex.
How does a “stmt” look like in the ANTLR grammar?
stmt: simple_stmt | compound_stmt;
It means that it sometimes is composed by a simple_stmt and sometimes by a compount_stmt.
But how does a compount_stmt looks like?
compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated | async_stmt;
This is how we convert it:
private fun Python3Parser.StmtContext.toAst(considerPosition: Boolean = true): List<Statement> {
return when {
this.compound_stmt()?.funcdef() != null -> {
val parseTreeNode = this.compound_stmt().funcdef()!!
val params = parseTreeNode.parameters().typedargslist().tfpdef().sortedBy { it.position }
val initialValues = parseTreeNode.parameters().typedargslist().test().sortedBy { it.position }
val initialValuesByParam = HashMap<Python3Parser.TfpdefContext, Python3Parser.TestContext>()
initialValues.forEach { iv ->
val param = params.last { p -> p.position.end.isBefore(iv.position.start) }
require(param !in initialValuesByParam)
initialValuesByParam[param] = iv
}
val paramsWithInitialValues = params.map { Pair(it, initialValuesByParam[it]) }
return listOf(
FunctionDeclaration(
parseTreeNode.NAME().text,
paramsWithInitialValues.map { it.toAst(considerPosition) },
parseTreeNode.suite().toAst(considerPosition),
toPosition(considerPosition)
)
)
}
this.compound_stmt()?.if_stmt() != null -> {
val parseTreeNode = this.compound_stmt()?.if_stmt()!!
return listOf(
IfStatement(
parseTreeNode.test()[0].toAst(considerPosition),
parseTreeNode.suite()[0].toAst(considerPosition),
toPosition(considerPosition)
)
)
}
this.compound_stmt()?.while_stmt() != null -> {
val parseTreeNode = this.compound_stmt()?.while_stmt()!!
require(parseTreeNode.suite().size == 1)
return listOf(
WhileStatement(
parseTreeNode.test().toAst(considerPosition),
parseTreeNode.suite()[0].toAst(considerPosition),
toPosition(considerPosition)
)
)
}
this.simple_stmt() != null -> {
return this.simple_stmt().toAst(considerPosition)
}
else -> TODO()
}
}
In other words, we look at what elements it contains and use that information to decide which AST node to produce. Again, that would be simpler if the grammar was using features of ANTLR that help with precedence and if it was using labels. Conversion code is not always that complex. It is very frequently a bit complex but we are taking out the complexity here, to simplify the life of who will use the AST instead of having to navigate a too-detailed and messy parse tree.
Now, let’s look to a couple of expressions. For example and and or:
or_test: and_test ('or' and_test)*;
and_test: not_test ('and' not_test)*;
This is basically saying that an or expression could be two different things:
- a proper or expression, made of two or more operands (of type and_test) and one or more operators (‘or’)
- alternatively it could be a single operand of type and_test, so not really an or expression
This is not how we would think conceptually of or expressions. A single element is not or expressions to us, and four elements separated by three ‘or’ operators to us look like three or expressions, not one. This is the kind of thing we want to correct in our conversion.
private fun Python3Parser.Or_testContext.toAst(considerPosition: Boolean = true): Expression {
return when {
this.and_test().size == 1 -> this.and_test()[0].toAst(considerPosition)
else -> TODO()
}
}
private fun Python3Parser.And_testContext.toAst(considerPosition: Boolean = true): Expression {
return when {
this.not_test().size == 1 -> this.not_test()[0].toAst(considerPosition)
else -> TODO()
}
}
In the conversion, we cover for now only the case in which we have just one element. In both cases, we throw away the or/and expression and just convert directly the contained element. The fake and/or expression was there just because the parser needed to handle precedence, and we do not need to keep it.
Finally, we use these conversions in our Kolasu Parser:
class Python3KolasuParser : KolasuParser<CompilationUnit, Python3Parser, Python3Parser.File_inputContext>() {
…
override fun parseTreeToAst(parseTreeRoot: Python3Parser.File_inputContext, considerPosition: Boolean): CompilationUnit? {
return parseTreeRoot.toAst(considerPosition)
}
}
We call toAst on the parseTreeRoot and as it converts its children it will call toAst on them, recursively, producing our complete AST as the output.
This point corresponds to git tag 05_conversion.
Testing the AST
At this point we may write a test to verify the AST for a complex file (plates.py) is produced correctly. In particular we are interested in recognizing correctly function declarations but not their body. Let’s see how we can do that.
@Test
fun parsePlatesFromFile() {
val kolasuParser = Python3KolasuParser()
val result = kolasuParser.parse(this.javaClass.getResourceAsStream("/plates.py"), considerPosition = false)
assert(result.correct)
assertEquals(3, result.root!!.stmts.size)
val generatePlatesSimulation = FunctionDeclaration(
"generate_plates_simulation",
listOf(
ParameterDeclaration("seed"),
ParameterDeclaration("width"),
ParameterDeclaration("height"),
ParameterDeclaration("sea_level", defaultValue = NumberLiteral("0.65")),
ParameterDeclaration("erosion_period", defaultValue = NumberLiteral("60")),
ParameterDeclaration("folding_ratio", defaultValue = NumberLiteral("0.02")),
ParameterDeclaration("aggr_overlap_abs", defaultValue = NumberLiteral("1000000")),
ParameterDeclaration("aggr_overlap_rel", defaultValue = NumberLiteral("0.33")),
ParameterDeclaration("cycle_count", defaultValue = NumberLiteral("2")),
ParameterDeclaration("num_plates", defaultValue = NumberLiteral("10")),
ParameterDeclaration("verbose", defaultValue = FunctionInvocation(ReferenceExpression("get_verbose"), emptyList())),
),
body = IgnoreChildren()
)
val platesSimulation = FunctionDeclaration(
"_plates_simulation",
listOf(
ParameterDeclaration("name"),
ParameterDeclaration("width"),
ParameterDeclaration("height"),
ParameterDeclaration("seed"),
ParameterDeclaration(
"temps",
defaultValue = ArrayLiteral(
listOf(
NumberLiteral(".874"),
NumberLiteral(".765"),
NumberLiteral(".594"),
NumberLiteral(".439"),
NumberLiteral(".366"),
NumberLiteral(".124"),
)
)
),
ParameterDeclaration(
"humids",
defaultValue = ArrayLiteral(
listOf(
NumberLiteral(".941"),
NumberLiteral(".778"),
NumberLiteral(".507"),
NumberLiteral(".236"),
NumberLiteral("0.073"),
NumberLiteral(".014"),
NumberLiteral(".002"),
)
)
),
ParameterDeclaration("gamma_curve", defaultValue = NumberLiteral("1.25")),
ParameterDeclaration("curve_offset", defaultValue = NumberLiteral(".2")),
ParameterDeclaration("num_plates", defaultValue = NumberLiteral("10")),
ParameterDeclaration("ocean_level", defaultValue = NumberLiteral("1.0")),
ParameterDeclaration("step", defaultValue = FunctionInvocation(FieldAccess(ReferenceExpression("Step"), "full"), emptyList())),
ParameterDeclaration("verbose", defaultValue = FunctionInvocation(ReferenceExpression("get_verbose"), emptyList())),
),
body = IgnoreChildren()
)
val worldGen = FunctionDeclaration(
"world_gen",
listOf(
ParameterDeclaration("name"),
ParameterDeclaration("width"),
ParameterDeclaration("height"),
ParameterDeclaration("seed"),
ParameterDeclaration(
"temps",
defaultValue = ArrayLiteral(
listOf(
NumberLiteral(".874"),
NumberLiteral(".765"),
NumberLiteral(".594"),
NumberLiteral(".439"),
NumberLiteral(".366"),
NumberLiteral(".124"),
)
)
),
ParameterDeclaration(
"humids",
defaultValue = ArrayLiteral(
listOf(
NumberLiteral(".941"),
NumberLiteral(".778"),
NumberLiteral(".507"),
NumberLiteral(".236"),
NumberLiteral("0.073"),
NumberLiteral(".014"),
NumberLiteral(".002"),
)
)
),
ParameterDeclaration("num_plates", defaultValue = NumberLiteral("10")),
ParameterDeclaration("ocean_level", defaultValue = NumberLiteral("1.0")),
ParameterDeclaration("step", defaultValue = FunctionInvocation(FieldAccess(ReferenceExpression("Step"), "full"), emptyList())),
ParameterDeclaration("gamma_curve", defaultValue = NumberLiteral("1.25")),
ParameterDeclaration("curve_offset", defaultValue = NumberLiteral(".2")),
ParameterDeclaration("fade_borders", defaultValue = BooleanLiteral(true)),
ParameterDeclaration("verbose", defaultValue = FunctionInvocation(ReferenceExpression("get_verbose"), emptyList())),
),
body = IgnoreChildren()
)
assertASTsAreEqual(generatePlatesSimulation, result.root!!.stmts[0])
assertASTsAreEqual(platesSimulation, result.root!!.stmts[1])
assertASTsAreEqual(worldGen, result.root!!.stmts[2])
assertASTsAreEqual(
CompilationUnit(
listOf(
generatePlatesSimulation,
platesSimulation,
worldGen
)
),
result.root!!
)
}
We:
- Define the expected AST
- Use the function assertASTsAreEqual for the comparison
- We use the special collection IgnoreChildren for the body of the function. The function assertASTsAreEqual will take in account and not compare it with the actual body of the function
This point corresponds to git tag 06_ast_test.
Traversing the AST
Most parser-based applications need to do one thing all the time: traverse the tree.
The main operations needed are:
- Finding children of a given node type
- Finding children with certain values (e.g., a given name)
- Finding all the descendants (i.e., children and their children recursively) of a given type
- Finding the closest ancestor of a given type
These operations are well supported by Kolasu. They support navigating the tree in different orders, transforming the tree, and more. In this article, we want to focus on the main ones.
Finding children of a given node type is something we have already seen when we defined the relation topLevelFunctions in CompilationUnit:
@Derived val topLevelFunctions get() = stmts.filterIsInstance(FunctionDeclaration::class.java)
Let’s now write a test where we can see filtering by value:
@Test
fun parseStatementsInGeneratePlatesSimulation() {
val kolasuParser = Python3KolasuParser()
val result = kolasuParser.parse(this.javaClass.getResourceAsStream("/plates.py"), considerPosition = false)
val generatePlatesSimulation = result.root!!.topLevelFunctions.find { it.name == "generate_plates_simulation" }
assertNotNull(generatePlatesSimulation)
assertEquals(7, generatePlatesSimulation.body.size)
}
In this test, we show you how we can easily get a function with a given name.
In the next test instead, we want to find all the assignments contained in a function. Potentially they could be annidated in other statements, like this:
if foo:
while bar:
if zum:
...my assignment…
In Kolasu we can use walkDescendants for this:
@Test
fun distinguishParameterReference() {
val kolasuParser = Python3KolasuParser()
val result = kolasuParser.parse(this.javaClass.getResourceAsStream("/params_usage.py"), considerPosition = false)
val fun2 = result.root!!.topLevelFunctions.find { it.name == "fun2" }
assertNotNull(fun2)
val assignments = fun2.walkDescendants(AssignmentExpression::class).toList()
assertEquals("a", (assignments[0].assigned as ReferenceExpression).reference)
assertEquals(true, (assignments[0].value as ReferenceExpression).isParameterReference)
assertEquals("b", (assignments[1].assigned as ReferenceExpression).reference)
assertEquals(false, (assignments[1].value as ReferenceExpression).isParameterReference)
}
In other cases we may want to do the opposite: given an assignment find in which function they are contained.
This point corresponds to git tag 07_ast_traversal.
Linter
Now that we are able to build an AST let’s use it to build our linter.
Let’s start with looking at src/main/kotlin/com/strumenta/python3linter/Tool.kt. Let’s start with the entry point:
fun main(args: Array<String>) {
if (args.isEmpty()) {
println("Please specify which programs you want us to analyze")
}
args.forEach {
val file = File(it)
if (file.exists()) {
when {
file.isDirectory -> {
println("path '$it' indicates a directory, analyzing each file in it")
analyzeDirectory(file)
}
file.isFile -> {
println("path '$it' indicates a file, analyzing it")
analyzeFile(file)
}
else -> {
System.err.println("path '$it' is neither a directory or a file: ignoring it")
}
}
} else {
System.err.println("path '$it' does not exist")
}
}
}
We can receive as input files or directories and we analyze them both.
When we need to analyze a file we invoke our linter and print the findings:
fun analyzeFile(file: File) {
println("[File $file]")
val analysisResult = Python3Linter().analyze(file)
if (analysisResult.findings.isEmpty()) {
println(" no findings")
} else {
analysisResult.findings.sortedBy { it.severity }.forEach {
println(" [${it.severity}] ${it.message}")
}
}
println()
}
While we traverse directories looking for more directories and files to process:
fun analyzeDirectory(file: File) {
file.listFiles()?.forEach { child ->
when {
child.isDirectory -> {
analyzeDirectory(child)
}
child.isFile -> {
analyzeFile(child)
}
}
}
}
The interesting bits are in our linter itself.
class Python3Linter {
fun analyze(file: File): AnalysisResult {
val findings = LinkedList<Finding>()
val parsingResult = Python3KolasuParser().parse(file, true)
if (parsingResult.root == null) {
findings.add(Finding(Severity.HIGH, "The AST could not be produced. Aborting"))
} else {
if (!parsingResult.correct) {
findings.add(Finding(Severity.MEDIUM, "The file contains error, this may affect the analysis"))
}
val ast = parsingResult.root!!
// Check if the file is too long
val numberOfLines = ast.position!!.end.line
when {
numberOfLines > 5000 -> findings.add(Finding(Severity.HIGH, "File way too long!"))
numberOfLines > 2000 -> findings.add(Finding(Severity.MEDIUM, "File too long!"))
numberOfLines > 500 -> findings.add(Finding(Severity.LOW, "File a bit long"))
}
// Check if we have too many functions
when {
ast.topLevelFunctions.size > 50 -> findings.add(Finding(Severity.HIGH, "Way too many top level functions!"))
ast.topLevelFunctions.size > 30 -> findings.add(Finding(Severity.MEDIUM, "Too many top level functions!"))
ast.topLevelFunctions.size > 15 -> findings.add(Finding(Severity.LOW, "A bit too many top level functions"))
}
ast.topLevelFunctions.forEach { fd ->
// Check if functions have too many parameters
val nParams = fd.params.size
when {
nParams > 10 -> findings.add(Finding(Severity.HIGH, "Way too many parameters in function ${fd.name}", fd.position?.start?.line))
nParams > 7 -> findings.add(Finding(Severity.MEDIUM, "Too many parameters in function ${fd.name}", fd.position?.start?.line))
nParams > 4 -> findings.add(Finding(Severity.LOW, "A bit too many parameters in function ${fd.name}", fd.position?.start?.line))
}
// Check if there are unused parameters
val referredNames: List<String> = fd.body.map { it.walkDescendants(ReferenceExpression::class).map { it.reference }.distinct().toList() }.flatten()
fd.params.forEach {
if (it.name !in referredNames) {
findings.add(Finding(Severity.MEDIUM, "Unused parameter ${it.name} in ${fd.name}", it.position?.start?.line))
}
}
}
}
return AnalysisResult(file, findings)
}
}
Our linter has just a method that given a file:
- Build the AST, using our parser. Note that in case of errors in the source code we still get an AST to process, but error recovery could affect our findings
- We then analyze the AST to populate our list of findings
- We return our findings as an AnalysisResult
Let’s look at the checks. We start by looking at the length of a file:
// Check if the file is too long
val numberOfLines = ast.position!!.end.line
when {
numberOfLines > 5000 -> findings.add(Finding(Severity.HIGH, "File way too long!"))
numberOfLines > 2000 -> findings.add(Finding(Severity.MEDIUM, "File too long!"))
numberOfLines > 500 -> findings.add(Finding(Severity.LOW, "File a bit long"))
}
We then look at the number of functions:
// Check if we have too many functions
when {
ast.topLevelFunctions.size > 50 -> findings.add(Finding(Severity.HIGH, "Way too many top level functions!"))
ast.topLevelFunctions.size > 30 -> findings.add(Finding(Severity.MEDIUM, "Too many top level functions!"))
ast.topLevelFunctions.size > 15 -> findings.add(Finding(Severity.LOW, "A bit too many top level functions"))
}
Then we look at each function:
ast.topLevelFunctions.forEach { fd ->
// Check if functions have too many parameters
val nParams = fd.params.size
when {
nParams > 10 -> findings.add(Finding(Severity.HIGH, "Way too many parameters in function ${fd.name}", fd.position?.start?.line))
nParams > 7 -> findings.add(Finding(Severity.MEDIUM, "Too many parameters in function ${fd.name}", fd.position?.start?.line))
nParams > 4 -> findings.add(Finding(Severity.LOW, "A bit too many parameters in function ${fd.name}", fd.position?.start?.line))
}
// Check if there are unused parameters
val referredNames: List<String> = fd.body.map { it.walkDescendants(ReferenceExpression::class).map { it.reference }.distinct().toList() }.flatten()
fd.params.forEach {
if (it.name !in referredNames) {
findings.add(Finding(Severity.MEDIUM, "Unused parameter ${it.name} in ${fd.name}", it.position?.start?.line))
}
}
}
We check if they have too many parameters and then we check if they have unused parameters. The way we identify unused parameters is not completely correct as we do not consider shadowing. In any case, we look at each reference and we make a list (without duplicates) of all the names used. We then check if there is any parameter that does not appear in this list of referred values. If that is the case we report it as unused.
This point corresponds to git tag 08_linter.
Testing the linter
Time to test our linter!
We can first test it on our large example file, plates.py:
@Test
fun analyzePlates() {
val file = File("src/test/resources/plates.py")
val analysisResult = Python3Linter().analyze(file)
assertEquals(
AnalysisResult(
file = file,
findings = listOf(
Finding(severity = Severity.HIGH, message = "Way too many parameters in function generate_plates_simulation", line = 13),
Finding(severity = Severity.HIGH, message = "Way too many parameters in function _plates_simulation", line = 38),
Finding(severity = Severity.HIGH, message = "Way too many parameters in function world_gen", line = 55)
)
),
analysisResult
)
}
Then we can test it with our smaller file, which contains an unused parameter:
@Test
fun analyzeParamsUsage() {
val file = File("src/test/resources/params_usage.py")
val analysisResult = Python3Linter().analyze(file)
assertEquals(
AnalysisResult(
file = file,
findings = listOf(
Finding(severity = Severity.MEDIUM, message = "Unused parameter p2 in fun1", line = 1)
)
),
analysisResult
)
}
Nothing much to notice here: it just works!
This point corresponds to git tag 09_linter_tests.
Kolasu: what we have not seen
There are many things we have not seen:
- More usages of derived properties
- Serialization/unserialization of ASTs to JSON and XML
- EMF integration
- Integration with Parser Bench, our web application to visualize ASTs
- Integration with our AST Documentation Tool
- Support for generating bindings in multiple languages and speed up execution by using GraalVM
All these possibilities are based on Kolasu and on building a good AST. It is an invaluable tool in our work. In this article we shared how it can be used to build maintainable and solid applications to process code.
We hope this has been an interesting reading!
Conclusions
There are many interesting applications that can be built by processing languages. Our goal is to enable the possibility of building such great tools by building first the layer they will rely upon: building advanced parser with Kolasu. What makes a parser great? The fact it exposes a simple, high-level AST which can be easily processed through a nice API and easily integrated with other systems through a proper serialization mechanism. This leads to solutions which are much easier to develop and more maintainable. We will work on improving our approach and solidify Kolasu so that anyone can use it to build more solid solutions and amazing applications based on those parsers.
Read more:
To discover more about how to write a python parser, you can read Parsing In Python: Tools And Libraries
To understand how to use ANTLR, you can read The ANTLR Mega Tutorial
To discover more about parsing in Javascript, you can read Parsing in JavaScript: Tools and Libraries
For a full understanding how parsers works, see A Guide to Parsing: Algorithms and Terminology
To discover more about parsing in Java, you can read Parsing in Java: Tools and Libraries
To discover more about parsing in C#, you can read Parsing in C#: Tools and Libraries
To discover more about parsing SQL, you can read Parsing SQL

