
This is an article similar to a previous one we wrote: Parsing in Java, so the introduction is the same. Skip to chapter 3 if you have already read it.
If you need to parse a language, or document, from JavaScript there are fundamentally three ways to solve the problem:
- use an existing library supporting that specific language: for example a library to parse XML
- building your own custom parser by hand
- a tool or library to generate a parser: for example ANTLR, that you can use to build parsers for any language
Use An Existing Library
The first option is the best for well known and supported languages, like XML or HTML. A good library usually include also API to programmatically build and modify documents in that language. This is typically more of what you get from a basic parser. The problem is that such libraries are not so common and they support only the most common languages. In other cases you are out of luck.
Building Your Own Custom Parser By Hand
You may need to pick the second option if you have particular needs. Both in the sense that the language you need to parse cannot be parsed with traditional parser generators, or you have specific requirements that you cannot satisfy using a typical parser generator. For instance, because you need the best possible performance or a deep integration between different components.
A Tool Or Library To Generate A Parser
In all other cases the third option should be the default one, because is the one that is most flexible and has the shorter development time. That is why on this article we concentrate on the tools and libraries that correspond to this option.
Note: text in blockquote describing a program comes from the respective documentation
Tools To Create Parsers
We are going to see:
- tools that can generate parsers usable from JavaScript (and possibly from other languages)
- JavaScript libraries to build parsers
Tools that can be used to generate the code for a parser are called parser generators or compiler compiler. Libraries that create parsers are known as parser combinators.
Parser generators (or parser combinators) are not trivial: you need some time to learn how to use them and not all types of parser generators are suitable for all kinds of languages. That is why we have prepared a list of the best known of them, with a short introduction for each of them. We are also concentrating on one target language: JavaScript. This also means that (usually) the parser itself will be written in JavaScript.
To list all possible tools and libraries parser for all languages would be kind of interesting, but not that useful. That is because there will be simple too many options and we would all get lost in them. By concentrating on one programming language we can provide an apples-to-apples comparison and help you choose one option for your project.
Useful Things To Know About Parsers
To make sure that these list is accessible to all programmers we have prepared a short explanation for terms and concepts that you may encounter searching for a parser. We are not trying to give you formal explanations, but practical ones.
Structure Of A Parser
A parser is usually composed of two parts: a lexer, also known as scanner or tokenizer, and the proper parser. Not all parsers adopt this two-steps schema: some parsers do not depend on a lexer. They are called scannerless parsers.
A lexer and a parser work in sequence: the lexer scans the input and produces the matching tokens, the parser scans the tokens and produces the parsing result.
Let’s look at the following example and imagine that we are trying to parse a mathematical operation.
437 + 734

The lexer scans the text and find ‘4’, ‘3’, ‘7’ and then the space ‘ ‘. The job of the lexer is to recognize that the first characters constitute one token of type NUM. Then the lexer finds a ‘+’ symbol, which corresponds to a second token of type PLUS, and lastly it finds another token of type NUM.
The parser will typically combine the tokens produced by the lexer and group them.
The definitions used by lexers or parser are called rules or productions. A lexer rule will specify that a sequence of digits correspond to a token of type NUM, while a parser rule will specify that a sequence of tokens of type NUM, PLUS, NUM corresponds to an expression.
Scannerless parsers are different because they process directly the original text, instead of processing a list of tokens produced by a lexer.
It is now typical to find suites that can generate both a lexer and parser. In the past it was instead more common to combine two different tools: one to produce the lexer and one to produce the parser. This was for example the case of the venerable lex & yacc couple: lex produced the lexer, while yacc produced the parser.
Parse Tree And Abstract Syntax Tree
There are two terms that are related and sometimes they are used interchangeably: parse tree and Abstract SyntaxTree (AST).
Conceptually they are very similar:
- they are both trees: there is a root representing the whole piece of code parsed. Then there are smaller subtrees representing portions of code that become smaller until single tokens appear in the tree
- the difference is the level of abstraction: the parse tree contains all the tokens which appeared in the program and possibly a set of intermediate rules. The AST instead is a polished version of the parse tree where the information that could be derived or is not important to understand the piece of code is removed
In the AST some information is lost, for instance comments and grouping symbols (parentheses) are not represented. Things like comments are superfluous for a program and grouping symbols are implicitly defined by the structure of the tree.
A parse tree is a representation of the code closer to the concrete syntax. It shows many details of the implementation of the parser. For instance, usually a rule corresponds to the type of a node. A parse tree is usually transformed in an AST by the user, possibly with some help from the parser generator.
A graphical representation of an AST looks like this.
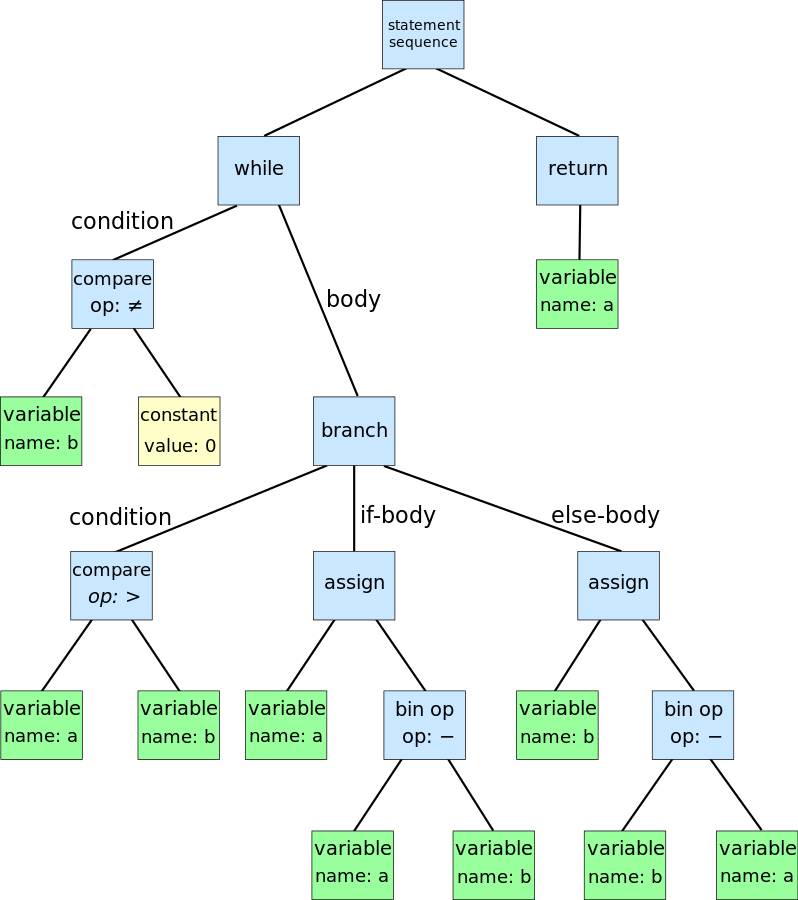
Sometimes you may want to start producing a parse tree and then derive from it an AST. This can make sense because the parse tree is easier to produce for the parser (it is a direct representation of the parsing process) but the AST is simpler and easier to process by the following steps. By following steps we mean all the operations that you may want to perform on the tree: code validation, interpretation, compilation, etc..
Grammar
A grammar is a formal description of a language that can be used to recognize its structure.
In simple terms is a list of rules that define how each construct can be composed. For example, a rule for an if statement could specify that it must starts with the “if” keyword, followed by a left parenthesis, an expression, a right parenthesis and a statement.
A rule could reference other rules or token types. In the example of the if statement, the keyword “if”, the left and the right parenthesis were token types, while expression and statement were references to other rules.
The most used format to describe grammars is the Backus-Naur Form (BNF), which also has many variants, including the Extended Backus-Naur Form. The Extended variant has the advantage of including a simple way to denote repetitions. A typical rule in a Backus-Naur grammar looks like this:
<symbol> ::= __expression__
The <symbol> is usually nonterminal, which means that it can be replaced by the group of elements on the right, __expression__. The element __expression__ could contains other nonterminal symbols or terminal ones. Terminal symbols are simply the ones that do not appear as a <symbol> anywhere in the grammar. A typical example of a terminal symbol is a string of characters, like “class”.
Left-recursive Rules
In the context of parsers an important feature is the support for left-recursive rules. This means that a rule could start with a reference to itself. This reference could be also indirect.
Consider for example arithmetic operations. An addition could be described as two expression(s) separated by the plus (+) symbol, but an expression could also contain other additions.
addition ::= expression '+' expression multiplication ::= expression '*' expression // an expression could be an addition or a multiplication or a number expression ::= addition | multiplication |// a number
This description also match multiple additions like 5 + 4 + 3. That is because it can be interpreted as expression (5) (‘+’) expression(4+3). And then 4 + 3 itself can be divided in its two components.
The problem is that this kind of rules may not be used with some parser generators. The alternative is a long chain of expressions that takes care also of the precedence of operators.
Some parser generators support direct left-recursive rules, but not indirect one.
Types Of Languages And Grammars
We care mostly about two types of languages that can be parsed with a parser generator: regular languages and context-free languages. We could give you the formal definition according to the Chomsky hierarchy of languages, but it would not be that useful. Let’s look at some practical aspects instead.
A regular language can be defined by a series of regular expressions, while a context-free one need something more. A simple rule of thumb is that if a grammar of a language has recursive elements it is not a regular language. For instance, as we said elsewhere, HTML is not a regular language. In fact, most programming languages are context-free languages.
Usually to a kind of language correspond the same kind of grammar. That is to say there are regular grammars and context-free grammars that corresponds respectively to regular and context-free languages. But to complicate matters, there is a relatively new (created in 2004) kind of grammar, called Parsing Expression Grammar (PEG). These grammars are as powerful as Context-free grammars, but according to their authors they describe programming languages more naturally.
The Differences Between PEG and CFG
The main difference between PEG and CFG is that the ordering of choices is meaningful in PEG, but not in CFG. If there are many possible valid ways to parse an input, a CFG will be ambiguous and thus wrong. Instead with PEG the first applicable choice will be chosen, and this automatically solve some ambiguities.
Another difference is that PEG use scannerless parsers: they do not need a separate lexer, or lexical analysis phase.
Traditionally both PEG and some CFG have been unable to deal with left-recursive rules, but some tools have found workarounds for this. Either by modifying the basic parsing algorithm, or by having the tool automatically rewrite a left-recursive rule in a non recursive way. Either of these ways has downsides: either by making the generated parser less intelligible or by worsen its performance. However, in practical terms, the advantages of easier and quicker development outweigh the drawbacks.
If you want to know more about the theory of parsing, you should read A Guide to Parsing: Algorithms and Terminology.
Parser Generators
The basic workflow of a parser generator tool is quite simple: you write a grammar that defines the language, or document, and you run the tool to generate a parser usable from your JavaScript code.
The parser might produce the AST, that you may have to traverse yourself or you can traverse with additional ready-to-use classes, such Listeners or Visitors. Some tools instead offer the chance to embed code inside the grammar to be executed every time the specific rule is matched.
Usually you need a runtime library and/or program to use the generated parser.
Regular (Lexer)
Tools that analyze regular languages are typically called lexers.
Lexer
Lexer was (it has now been officially archived) a lexer that claimed to be modelled after flex. Though a fairer description would be a short lexer based upon RegExp. The documentation seems minimal, with just a few examples, but the whole thing is 147 lines of code, so it is actually comprehensive.
However, in a few lines manages to support a few interesting things and it appears to be quite popular and easy to use. One thing is its supports RingoJS, a JavaScript platform on top of the JVM. Another one is the integration with Jison, the Bison clone in JavaScript. If you temper your expectations it can be a useful tool.
There is no grammar, you just use a function to define the RegExp pattern and the action that should be executed when the pattern is matched. So, it is a cross between a lexer generator and a lexer combinator. You cannot combine different lexer functions, like in a lexer combinator, but the lexer it is only created dynamically at runtime, so it is not a proper lexer generator either.
It has been abandoned, but the fact that is so small, means that you can take on maintenance with ease, if you found it useful.
var lexer = new Lexer;
var chars = lines = 0;
lexer.addRule(/n/, function () {
lines++;
chars++;
});
lexer.addRule(/./, function () {
chars++;
});
lexer.setInput("Hello World!n Hello Stars!n!")
lexer.lex();
Context Free
Let’s see the tools that generate Context Free parsers.
ANTLR
ANTLR is a great parser generator written in Java that can also generate parsers for JavaScript and many other languages. ANTLR is based on an new LL algorithm developed by the author and described in this paper: Adaptive LL(*) Parsing: The Power of Dynamic Analysis (PDF).
It is quite popular for its many useful features: for instance, version 4 supports direct left-recursive rules. However a real added value of a vast community it is the large amount of grammars available.
It provides two ways to walk the AST, instead of embedding actions in the grammar: visitors and listeners. The first one is suited when you have to manipulate or interact with the elements of the tree, while the second is useful when you just have to do something when a rule is matched.
The typical grammar is divided in two parts: lexer rules and parser rules. The division is implicit, since all the rules starting with an uppercase letter are lexer rules, while the ones starting with a lowercase letter are parser rules. Alternatively, lexer and parser grammars can be defined in separate files.
grammar simple; basic : NAME ':' NAME ; NAME : [a-zA-Z]* ; COMMENT : '/*' .*? '*/' -> skip ;
If you are interested to learn how to use ANTLR, you can look into this giant ANTLR tutorial we have written. If you are ready to become a professional ANTLR developer, you can buy our video course to Build professional parsers and languages using ANTLR. The course is taught using Python, but the source code is also available in JavaScript.
APG
APG is a recursive-descent parser using a variation of Augmented BNF, that they call Superset Augmented BNF. ABNF is a particular variant of BNF designed to better support bidirectional communications protocol. APG also support additional operators, like syntactic predicates and custom user defined matching functions.
It can generate parsers in C/C++, Java and JavaScript. Support for the last language seems superior and more up to date: it has a few more features and it is more recently updated. In fact, the documentation says it is designed to have the look and feel of JavaScript RegExp. There is also a separate Python version that is developed on its own.
And because it is based on ABNF, it is especially well suited to parsing the languages of many Internet technical specifications. In fact, it is the parser of choice for several large Telecom companies.
An APG grammar is very clean and easy to understand.
// example from a tutorial of the author of the tool available here
// https://www.sitepoint.com/alternative-to-regular-expressions/
phone-number = ["("] area-code sep office-code sep subscriber
area-code = 3digit ; 3 digits
office-code = 3digit ; 3 digits
subscriber = 4digit ; 4 digits
sep = *3(%d32-47 / %d58-126 / %d9) ; 0-3 ASCII non-digits
digit = %d48-57 ; 0-9
Jison
Jison generates bottom-up parsers in JavaScript. Its API is similar to Bison’s, hence the name.
Despite the name Jison can also replace flex, so you do not need a separate lexer. Although you can use one or build your own custom lexer. All you need is an object with the functions setInput and lex. It can best recognize languages described by LALR(1) grammars, though it also has modes for LR(0), SLR(1).
The generated parser does not require a runtime component, you can use it as a standalone software.
It has a good enough documentation with a few examples and even a section to try your grammars online. Although at times it relies on the Bison manual to cover the lack of its own documentation.
A Jison grammar can be inputted using a custom JSON format or a Bison-styled one. Both requires you to use embedded actions if you want to do something when a rule is matched. The following example is in the custom JSON format.
// example from the documentation
{
"comment": "JSON Math Parser",
// JavaScript comments also work
"lex": {
"rules": [
["s+", "/* skip whitespace */"],
["[0-9]+(?:.[0-9]+)?b", "return 'NUMBER'"],
["*", "return '*'"],
["/", "return '/'"],
["-", "return '-'"],
["+", "return '+'"],
[..] // skipping some parts
]
},
"operators": [
["left", "+", "-"],
["left", "*", "/"],
["left", "UMINUS"]
[..] // skipping some parts
],
"bnf": {
"expressions": [["e EOF", "return $1"]],
"e" :[
["e + e", "$$ = $1+$3"],
["e - e", "$$ = $1-$3"],
["- e", "$$ = -$2", {"prec": "UMINUS"}],
["NUMBER", "$$ = Number(yytext)"],
[..] // skipping some parts
]
}
}
It is very popular and used by many project including CoffeeScript and Handlebars.js.
Nearley
nearley uses the Earley parsing algorithm augmented with Joop Leo’s optimizations to parse complex data structures easily. nearley is über-fast and really powerful. It can parse literally anything you throw at it.
The Earley algorithm is designed to easily handle all grammars, including left-recursive and ambiguous ones. Essentially its main advantage it is that it should never catastrophically fail. On the other hand, it could be slower than other parsing algorithms. Nearly itself also is able to detect some ambiguous grammars. It can also reports multiple results in the case of an ambiguous input.
A Nearley grammar is a written in a .ne file that can include custom code. A rule can include an embedded action, which the documentation calls a postprocessing function. You can also use a custom lexer.
# from the examples in Nearly
# csv.ne
@{%
var appendItem = function (a, b) { return function (d) { return d[a].concat([d[b]]); } };
var appendItemChar = function (a, b) { return function (d) { return d[a].concat(d[b]); } };
var empty = function (d) { return []; };
var emptyStr = function (d) { return ""; };
%}
file -> header newline rows {% function (d) { return { header: d[0], rows: d[2] }; } %}
# id is a special preprocessor function that return the first token in the match
header -> row {% id %}
rows -> row
| rows newline row {% appendItem(0,2) %}
row -> field
| row "," field {% appendItem(0,2) %}
field -> unquoted_field {% id %}
| """ quoted_field """ {% function (d) { return d[1]; } %}
quoted_field -> null {% emptyStr %}
| quoted_field quoted_field_char {% appendItemChar(0,1) %}
quoted_field_char -> [^"] {% id %}
| """ """ {% function (d) { return """; } %}
unquoted_field -> null {% emptyStr %}
| unquoted_field char {% appendItemChar(0,1) %}
char -> [^nr",] {% id %}
newline -> "r" "n" {% empty %}ca
| "r" | "n" {% empty %}
Another interesting feature is that you could build custom tokens. You can define them using a tokenizing library, a literal or a test function. The test function must return true if the text corresponds to that specific token.
@{%
var print_tok = {literal: "print"};
var number_tok = {test: function(x) {return x.constructor === Number; }}
%}
main -> %print_tok %number_tok
Nearley include tools for debugging and understanding your parser. For instance, Unparser can automatically generate random strings that are considered correct by your parser. This is useful to test your parser against random noise or even to generate data from a schema (e.g. a random email address). It also include a tool to generate SVG railroad diagrams: a graphical way to represent a grammar.

A Nearley parser requires the Nearley runtime.
Nearley documentation is a good overview of what is available and there is also a third-party playground to try a grammar online. But you will not find a complete explanation of all the features.
PEG
After the CFG parsers is time to see the PEG parsers available for JavaScript.
Canopy
Canopy is a parser compiler targeting Java, JavaScript, Python and Ruby. It takes a file describing a parsing expression grammar and compiles it into a parser module in the target language. The generated parsers have no runtime dependency on Canopy itself.
It also provides easy access to the parse tree nodes.
A Canopy grammar has the neat feature of using actions annotation to use custom code in the parser. In practical terms. you just write the name of a function next to a rule and then you implement the function in your source code.
// the actions are prepended by %
grammar Maps
map <- "{" string ":" value "}" %make_map
string <- "'" [^']* "'" %make_string
value <- list / number
list <- "[" value ("," value)* "]" %make_list
number <- [0-9]+ %make_number
The JavaScript file containing the action code.
var maps = require('./maps');
var actions = {
make_map: function(input, start, end, elements) {
var map = {};
map[elements[1]] = elements[3];
return map;
},
[..]
};
Ohm
Ohm is a parser generator consisting of a library and a domain-specific language
Ohm grammars are defined in a custom format that can be put in a separate file or in a string. However, the parser is generated dynamically and not with a separate tool. In that sense it works like a parser library more than a traditional parser generator.
A helper function to create an AST is included among the extras.
In Ohm, a grammar defines a language, and semantic actions specify what to do with valid inputs in that language
A grammar is completely separated from semantic actions. This simplify portability and readability and allows to support different languages with the same grammar. At the moment Ohm only supports JavaScript, but more languages are planned for the future. The typical grammar is then clean and readable.
Arithmetic {
Exp
= AddExp
AddExp
= AddExp "+" PriExp -- plus
| AddExp "-" PriExp -- minus
| PriExp
PriExp
= "(" Exp ")" -- paren
| number
number
= digit+
}
Semantic actions can be implemented using a simple API. In practical terms this ends up working like the visitor pattern with the difference that is easier to define more groups of semantic actions.
var semantics = g.createSemantics().addOperation('eval', {
Exp: function(e) {
return e.eval();
},
AddExp: function(e) {
return e.eval();
},
AddExp_plus: function(left, op, right) {
return left.eval() + right.eval();
},
AddExp_minus: function(left, op, right) {
return left.eval() - right.eval();
},
PriExp: function(e) {
return e.eval();
},
PriExp_paren: function(open, exp, close) {
return exp.eval();
},
number: function(chars) {
return parseInt(this.sourceString, 10);
},
});
var match = g.match('1 + (2 - 3) + 4');
console.log(semantics(match).eval());
To support debugging Ohm has a text trace and (work in progress) graphical visualizer. You can see the graphical visualizer at work and test a grammar in the interactive editor.
The documentation is not that bad, though you have to go under the doc directory to find it. There is no tutorial, but there are a few examples and a reference. In particular the documentation suggests reading a well commented Math example.
PEG.js/Peggy
PEG.js is a simple parser generator for JavaScript that produces fast parsers with excellent error reporting.
Note: the development of project PEG.js stopped in 2019. The original developer gave the project to a new maintainer, which then go dark. Peggy is the unofficial successor to PEG.js.
Peggy can work as a traditional parser generator and create a parser with a tool or can generate one using a grammar defined in the code. It supports different module loaders (e.g. AMD, CommonJS, etc.).
Peggy has a neat online editor that allows to write a grammar, test the generated parser and download it.
A Peggy grammar is usually written in a .pegjs file and can include embedded actions, custom initializing code and semantic predicates. That is to say functions that determine if a specific match is activated or not.
// example from the documentation
{
function makeInteger(o) {
return parseInt(o.join(""), 10);
}
}
start
= additive
additive
= left:multiplicative "+" right:additive { return left + right; }
/ multiplicative
multiplicative
= left:primary "*" right:multiplicative { return left * right; }
/ primary
primary
= integer
/ "(" additive:additive ")" { return additive; }
integer "integer"
= digits:[0-9]+ { return makeInteger(digits); }
The documentation is good enough, there are a few example grammars, but there are no official tutorials available. However, the good news is that we made one: A Peggy.js Tutorial. The popularity of the project had led to the development of third-party tools, like one to generate railroad diagrams, and plugins, like one to generate TypeScrypt parsers.
Waxeye
Waxeye is a parser generator based on parsing expression grammars (PEGs). It supports C, Java, Javascript, Python, Ruby and Scheme.
Waxeye can facilitate the creation of an AST by defining nodes in the grammar that will not be included in the generated tree. That is quite useful, but a drawback of Waxeye is that it only generates a AST. In the sense that there is no way to automatically execute an action when you match a node. You have to traverse and execute what you need manually.
One positive side-effect of this limitation is that grammars are easily readable and clean. They are also independent from any language.
// from the manual
calc <- ws sum
sum <- prod *([+-] ws prod)
prod <- unary *([*/] ws unary)
unary <= '-' ws unary
| :'(' ws sum :')' ws
| num
num <- +[0-9] ?('.' +[0-9]) ws
ws <: *[ tnr]
A particular feature of Waxeye is that it provides some help to compose different grammars together and then it facilitates modularity. For instance, you could create a common grammar for identifiers, that are usually similar in many languages.
Waxeye has a great documentation in the form of a manual that explains basic concepts and how to use the tool for all the languages it supports. There are a few example grammars.
Waxeye seems to be maintained, but it is not actively developed.
Parser Combinators
They allow you to create a parser simply with JavaScript code, by combining different pattern matching functions, that are equivalent to grammar rules. They are generally considered best suited for simpler parsing needs. Given they are just JavaScript libraries you can easily introduce them into your project: you do not need any specific generation step and you can write all of your code in your favorite editor. Their main advantage is the possibility of being integrated in your traditional workflow and IDE.
In practice this means that they are very useful for all the little parsing problems you find. If the typical developer encounters a problem, that is too complex for a simple regular expression, these libraries are usually the solution. In short, if you need to build a parser, but you don’t actually want to, a parser combinator may be your best option.
Bennu, Parjs And Parsimmon
Bennu is no more, the website redirect to spam, but the code is still available.
Parsimmon still exists, but it is officially unmaintained.
Parjs also still exists, but it is unofficially unmaintained, being stuck in 2019.
So, death abound in the area of parser combinators for JavaScript. If you are interested in the topic you may want to take over maintenanced of Parsimmon.
Bennu is a JavaScript parser combinator library based on Parsec. The Bennu library consists of a core set of parser combinators that implement Fantasy Land interfaces. More advanced functionality such as detailed error messaging, custom parser state, memoization, and running unmodified parsers incrementally is also supported.
All libraries are inspired by Parsec. Bennu and Parsimmon are the oldest and Bennu the more advanced between the two. They also all have an extensive documentation, but they have no tutorial. Bennu seems to be maintained, but it is not actively developed.
An example from the documentation.
var parse = require('bennu').parse;
var text = require('bennu').text;
var aOrB = parse.either(
text.character('a'),
text.character('b'));
parse.run(aOrB, 'b'); // 'b'
Parsimmon is a small library for writing big parsers made up of lots of little parsers. The API is inspired by parsec and Promises/A+.
Parsimmon is the most popular among the three, it is stable and updated.
The following is a part of the JSON example.
let whitespace = P.regexp(/s*/m);
let JSONParser = P.createLanguage({
// This is the main entry point of the parser: a full JSON value.
value: r =>
P.alt(
r.object,
r.string,
[..]
).thru(parser => whitespace.then(parser)),
[..]
// Regexp based parsers should generally be named for better error reporting.
string: () =>
token(P.regexp(/"((?:.|.)*?)"/, 1))
.map(interpretEscapes)
.desc('string'),
[..]
object: r =>
r.lbrace
.then(r.pair.sepBy(r.comma))
.skip(r.rbrace)
.map(pairs => {
let object = {};
pairs.forEach(pair => {
let [key, value] = pair;
object[key] = value;
});
return object;
}),
});
///////////////////////////////////////////////////////////////////////
let text = // JSON Object
let ast = JSONParser.value.tryParse(text);
Parjs is a JavaScript library of parser combinators, similar in principle and in design to the likes of Parsec and in particular its F# adaptation FParsec.
It’s also similar to the parsimmon library, but intends to be superior to it.
Parjs is only a few months old, but it is already quite developed. It also has the advantage of being written in TypeScript.
All the libraries have good documentation, but Parjs is great: it explains how to use the parser and also how to design good parsers with it. There are a few examples, including the following on string formatting.
/**
* Created by lifeg on 04/04/2017.
*/
import "../setup";
import {Parjs, LoudParser} from "../src";
//+ DEFINING THE PARSER
//Parse an identifier, an asciiLetter followed by an asciiLetter or digit, e.g. a12b but not 1ab.
let ident = Parjs.letter.then(Parjs.letter.or(Parjs.digit).many()).str;
//Parse a format token, an `ident` between `{` and `}`. Return the result as a Token object.
let formatToken = ident.between(Parjs.string("{"), Parjs.string("}")).map(x => ({token: x}));
//Parse an escaped character. This parses "`{a}" as the text "{a}" instead of a token.
//Also escapes the escaped char, parsing "``" as "`".
//Works for arbitrary characters like `a being parsed as a.
let escape = Parjs.string("`").then(Parjs.anyChar).str.map(x => ({text: x.substr(1)}));
//Parse text which is not an escape character or {.
let text = Parjs.noCharOf("`{").many(1).str.map(x => ({text: x}));
//The parser itself. Parses either a formatToken, e.g. {abc} or an escaped combo `x, or text that doesn't contain `{.
//Parses many times.
let formatParser = formatToken.or(escape, text).many();
//This prints a sequence of tokens {text: "hello, my name is "}, {token: name}, {text: " and I am "}, {token: " years old}, ...
console.log(formatParser.parse("hello, my name is {name} and I am {age} years old. This is `{escaped}. This is double escaped: ``{name}."));
JavaScript Libraries Related to Parsing
There are also some other interesting libraries related to parsing that are not part of a common category.
JavaScript Libraries That Parse JavaScript
There is one special case that could be managed in more specific way: the case in which you want to parse JavaScript code in JavaScript. Contrary to what we have found for Java and C# there is not a definitive choice: there are many good choices to parse JavaScript.
The three most popular libraries seems to be: Acorn, Esprima and UglifyJS. We are not going to say which one it is best because they all seem to be awesome, updated and well supported (except for Esprima, that slowly died).
One important difference is that UglifyJS is also a mangler/compressor/beautifier toolkit, which means that it also has many other uses. On the other hand, it is the only one to support only up to the version ECMAScript 5. Another thing to consider is that only esprima have a documentation worthy of projects of such magnitude.
Interesting Parsing Libraries: Chevrotain
Chevrotain is a very fast and feature rich JavaScript LL(k) Parsing DSL. It can be used to build parsers/compilers/interpreters for various use cases ranging from simple configuration files, to full fledged programing languages.
There is another interesting parsing tool that does not really fit in more common categories of tools, like parser generators or combinators: Chevrotain, a parsing DSL. A parsing DSL works as a cross between a parser combinator and a parser generator. You define a grammar in JavaScript code directly, but using the (Chevrotain) API and not a standard syntax like EBNF or PEG. You can see some reasons to prefer a parsing DSL rather than a parser generator on their documentation.
Chevrotain supports many advanced features typical of parser generators: like semantic predicates, separate lexer and parser and a grammar definition (optionally) separated from the actions. The actions can be implemented using a visitor and thus you can reuse the same grammar for multiple projects.
The following is a partial JSON example grammar from the documentation. As you can see the syntax is clearer to understand for a developer unexperienced in parsing, but a bit more verbose than a standard grammar.
const { CstParser, Lexer, createToken } = require("chevrotain")
// ----------------- lexer -----------------
const True = createToken({ name: "True", pattern: /true/ })
const False = createToken({ name: "False", pattern: /false/ })
const Null = createToken({ name: "Null", pattern: /null/ })
const LCurly = createToken({ name: "LCurly", pattern: /{/ })
const RCurly = createToken({ name: "RCurly", pattern: /}/ })
const LSquare = createToken({ name: "LSquare", pattern: /\[/ })
const RSquare = createToken({ name: "RSquare", pattern: /]/ })
const Comma = createToken({ name: "Comma", pattern: /,/ })
const Colon = createToken({ name: "Colon", pattern: /:/ })
const StringLiteral = createToken({
name: "StringLiteral",
pattern: /"(?:[^\\"]|\\(?:[bfnrtv"\\/]|u[0-9a-fA-F]{4}))*"/
})
const NumberLiteral = createToken({
name: "NumberLiteral",
pattern: /-?(0|[1-9]\d*)(\.\d+)?([eE][+-]?\d+)?/
})
const WhiteSpace = createToken({
name: "WhiteSpace",
pattern: /[ \t\n\r]+/,
group: Lexer.SKIPPED
})
const allTokens = [
WhiteSpace,
NumberLiteral,
StringLiteral,
LCurly,
RCurly,
LSquare,
RSquare,
Comma,
Colon,
True,
False,
Null
]
const JsonLexer = new Lexer(allTokens)
// ----------------- parser -----------------
class JsonParser extends CstParser {
// Unfortunately no support for class fields with initializer in ES2015, only in esNext...
// so the parsing rules are defined inside the constructor, as each parsing rule must be initialized by
// invoking RULE(...)
// see: https://github.com/jeffmo/es-class-fields-and-static-properties
constructor() {
super(allTokens)
// not mandatory, using $ (or any other sign) to reduce verbosity (this. this. this. this. .......)
const $ = this
// the parsing methods
$.RULE("json", () => {
$.OR([
{ ALT: () => $.SUBRULE($.object) },
{ ALT: () => $.SUBRULE($.array) }
])
})
$.RULE("object", () => {
$.CONSUME(LCurly)
$.OPTION(() => {
$.SUBRULE($.objectItem)
$.MANY(() => {
$.CONSUME(Comma)
$.SUBRULE2($.objectItem)
})
})
$.CONSUME(RCurly)
})
$.RULE("objectItem", () => {
$.CONSUME(StringLiteral)
$.CONSUME(Colon)
$.SUBRULE($.value)
})
$.RULE("array", () => {
$.CONSUME(LSquare)
$.OPTION(() => {
$.SUBRULE($.value)
$.MANY(() => {
$.CONSUME(Comma)
$.SUBRULE2($.value)
})
})
$.CONSUME(RSquare)
})
$.RULE("value", () => {
$.OR([
{ ALT: () => $.CONSUME(StringLiteral) },
{ ALT: () => $.CONSUME(NumberLiteral) },
{ ALT: () => $.SUBRULE($.object) },
{ ALT: () => $.SUBRULE($.array) },
{ ALT: () => $.CONSUME(True) },
{ ALT: () => $.CONSUME(False) },
{ ALT: () => $.CONSUME(Null) }
])
})
// very important to call this after all the rules have been defined.
// otherwise the parser may not work correctly as it will lack information
// derived during the self analysis phase.
this.performSelfAnalysis()
}
}
// ----------------- wrapping it all together -----------------
// reuse the same parser instance.
const parser = new JsonParser()
module.exports = {
jsonTokens: allTokens,
JsonParser: JsonParser,
parse: function parse(text) {
const lexResult = JsonLexer.tokenize(text)
// setting a new input will RESET the parser instance's state.
parser.input = lexResult.tokens
// any top level rule may be used as an entry point
const cst = parser.json()
return {
cst: cst,
lexErrors: lexResult.errors,
parseErrors: parser.errors
}
}
}
It is very fast, faster than any other JavaScript library and can compete with a custom parser written by hand, depending on the JavaScript engine on which it runs on. You can see the numbers and get more details on the benchmark of parsing libraries developed by the author of the library.
It also supports features useful for debugging like railroad diagram generation and custom error reporting. There are also a few features that are useful for building compiler, interpreters or tools for editors, such as automatic error recovery or syntactic content assist. The last one means that it can suggests the next token given a certain input, so it could be used as the building block for an autocomplete feature.
This is not all, Chevrotain even makes available its own engine to external use. This means that you can build your own parsing library on top of Chevrotain. For instance, you can create your own format for a grammar and then use the Chevrotain engine to power the parsing. It even gives you for free error checking features, such as detecting ambiguous alternatives, left recursion, etc.
Chevrotain has a great and well-organized documentation, with a tutorial, examples grammars and a reference. It also has a neat online editor/playground.
Chevrotain is written in TypeScript.
Summary
As we said in the sisters article about parsing in Java and C#, the world of parsers is a bit different from the usual world of programmers. In the case of JavaScript also the language lives in a different world from any other programming language. There is such disparate level of competence between its developers that you could find the best ones working with people that just barely know how to put together a script. And both want to parse things.
So, for JavaScript there are tools that a bit all over this spectrum. We have serious tools developed by academics for their courses or in the course of their degrees together with much simpler tools. Some of which blur the lines between parser generators and parser combinators. And all of them have their place. A further complication is that while usually parser combinators are reserved for easier uses, with JavaScript it is not always the case. You could find very powerful and complex parser combinators and much easier parser generators.
So, with JavaScript more than ever we cannot definitely suggest one software over the other. What it is best for a user might not be the best for somebody else. And we all know that the most technically correct solution might not be ideal in real life with all its constraints. So we wanted to share what we have learned on the best options for parsing in JavaScript.
We would like to thank Shahar Soel for having informed us of Chevrotain and having suggested some needed corrections.

