
In this article we explore the implementation of a simple compiler able to translate the IBM RPG programming language into executable machine code for modern hardware. It’s not a full featured RPG compiler – it implements a few basic constructs of the language but it’s good enough to understand how the LLVM infrastructure can be used to handle a high-level language.
The topics covered are in this tutorial are:
- Creating the compiler frontend with ANTLR
- Using the LLVM infrastructure and core libraries to generate the machine code
- Generating the debug information for source level debugging
The main benefit of generating a machine executable code is the optimal performance and minimal requirements about the runtime environment. As usual the source code of the project is available on GitHub at https://github.com/Strumenta/article-llvm-rpg. The LLVM infrastructure is mainly in C++ therefore this is a C++ project.
What is LLVM?
Writing a compiler, a software able to translate a high level human-readable code to an executable machine code, involves a lot of work. However by using the LLVM we obtain two main benefits:
- The executables we will obtain will be very fast, as LLVM is a mature, industrial-grade project, with great optimization
- LLVM can generate machine code for different platforms. By writing our frontend for our language (RPG), we get executables for all platforms supported by LLVM, without extra work
More in detail, LLVM provides an infrastructure that simplifies this process providing tools and APIs to write a compiler for an existing language or to implement a brand new programming language. It’s designed to be very modular and supports all compilation phases including frontend processing, code generation, optimization, and so forth. The major building blocks of LLVM can be subdivided in three logical categories: the frontend, the intermediate representation (IR) and the backend.

The frontend components are responsible for translating the source code into the Intermediate Representation (IR) which is the heart of the LLVM infrastructure. The IR is used through all the LLVM compilation phases and can have a different format based on where it is stored: in the compiler memory, on disk as bitcode, or as human readable assembly language.The Intermediate Representation (IR) is a Static Single Assignment (SSA) representation that provides type safety, flexibility, and the capability to implement high-level languages.
The backend module is responsible for translating the IR to a specific hardware such as the Intel X86 or the ARM architecture.
Generating the machine code for a specific CPU model is a very complex task and requires a deep understanding about a lot of low level details of the instruction set. In addition the machine code optimization is another task which involves complex algorithms hard to develop, debug and maintain. The reason LLVM chose an SSA representation is because it makes it possible to apply a bunch of well known code optimization algorithms. The LLVM backend takes in input a valid IR code and generates the optimized machine code simplifying the compiler implementation.
The LLVM project is released under the Apache License v2.0 (with some exceptions) which allows the software as part of commercial products to be included.
LLVM Infrastructure
The installation of the LLVM infrastructure depends on the target operating system.
The easy way is to download the binary distribution from llvm.org. As mentioned on the website, there are differences between the platforms.
The second option consists of cloning the GitHub repository and building the LLVM infrastructure from scratch following the instructions.
LLVM is a C/C++ project, CMake is required to generate the project files and a C/C++ compiler to build the project binaries tools and libraries.
I chose the second option, and I built the LLVM project on an Ubuntu Linux machine. The process took many hours and I had to fix some minor issues such as missing dependencies. I personally prefer compiling the project from scratch when possible to became familiar with the structure of the project and the binaries created. Once LLVM infrastructure ready, it’s possible to take a look at the human readable Intermediate Representation (IR) using clang which is a front-end for languages for the C language family.
hello.c
#include <stdio.h>
int main() {
int a = 1;
int b = 1;
int c = a + b;
printf("%d\n",c);
}
From the shell invoke the clang providing the command line switches to generate the LLVM IR.
strumenta@system-76:~hello$ clang -emit-llvm -S hello.c -o hello.ll
The clang will generate hello.ll as output.
hello.ll
; ModuleID = 'hello.c'
source_filename = "hello.c"
target triple = "x86_64-pc-linux-gnu"
@.str = private unnamed_addr constant [4 x i8] c"%d\0A\00", align 1
; Function Attrs: noinline nounwind optnone uwtable
define dso_local i32 @main() #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
store i32 1, i32* %1, align 4
store i32 1, i32* %2, align 4
%4 = load i32, i32* %1, align 4
%5 = load i32, i32* %2, align 4
%6 = add nsw i32 %4, %5
store i32 %6, i32* %3, align 4
%7 = load i32, i32* %3, align 4
%8 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %7)
ret i32 0
}
declare dso_local i32 @printf(i8*, ...) #1
The file hello.ll is the hello.c C program translated into the LLVM IR.It is possible to execute the IR running the lli which directly execute the IR.
strumenta@system-76:~hello$ lli hello.ll 2
To create an executable binary we can pass the IR file to clang.
strumenta@system-76:~hello$ clang -x ir hello.ll -o hello.out strumenta@system-76:~hello$./hello.out 2
The example above the executable target is the host machine CPU. However LLVM can generate the assembly for many CPU models and can also generate bitcode for the WebAssembly runtime.
The RPG Language
The RPG language (Report Program Generator) was developed by IBM in 1959, with the purpose of generating reports from data files. At Strumenta, we know RPG well as we created an open-source JVM interpreter for it, available on GitHub. More on this later.
The language has evolved overtime and nowadays software in RPG is still used and maintained in many industries and fully supported by IBM.
Although the most recent version of the language provides a free format source code entry, the examples provided are in the original fixed format definition specification which requires a specific positioning of the code within a row.
D NBR S 8 0
The example above declares the NBR variable which is a scalar variable with 8 digits and 0 decimal. Statements are identified by the C, below an example of an assignment.
C Eval NBR = 55
Implement a LLVM frontend with ANTLR
The frontend parser in this project has been generated using ANTLR, starting from the open source grammar of the RPG language created by Ryan Eberly, and available on GitHub as part of Jariko project. Jariko is an open-source JVM interpreter designed at Strumenta and developed in collaboration with Sme.UP, a client of ours.
ANTLR generates the Lexer and Parser that are used to feed the Symbol Table, and to create Abstract Syntax Tree. Then the Code Generator traverses the AST to generate the LLVM IR.
The compiler is written in C/C++, you can find detailed information about generating parsers for ANTLR in C++ in Getting Started with ANTLR in C++.
The compiler architecture is pretty straightforward. The Lexer and the Parser are generated by ANTLR starting from the grammar files. The parser implementation translate the parse tree in the Abstract Syntax Tree (AST) and populates the Symbol Table.
The Code Generator processes the AST and the Symbol table producing the IR as output.

To implement the translation from the parse tree to the Symbol Table and the AST it is required to extend the Visitor class generated by ANTLR. Depending on the complexity of the language the visitor subclass can become huge. To keep it simple, the process has been divided in two phases, the first process the data declaration which populates the symbol table and the second takes care of the statements and the AST generation.
This design decision allows to maintain two separated visitor subclasses with a well defined behaviour.

The RpgVisitor extends the ANTLR generated parser and implements the common functionality used in the subclasses, such as the expression evaluation.
The RpgDeclarationVisitor is responsible for processing the data declarations and populating the symbol table while the CodeVisitor creates the AST.
// First Pass parse declarations
RpgDeclarationVisitor declarationVisitor(file,this);
declarationVisitor.visit(tree);
symbolTable->dump();
// Second Pass parse statements
RpgCodeVisitor codeVisitor(file,this);
codeVisitor.visit(tree);
codeVisitor.dump();
// Code Generation
GeneratorLLVM *generator = new GeneratorLLVM(file,emitDebugInfo);
generator->process(symbolTable,ast);
generator->dump();
The last section performs the code generation, it takes the Symbol Table and the AST and produces the LLVM IR. The emitDebugInfo is used to instruct the code generator to include the debug information that can be used to run the code with a debugger.
Symbol Table
The Symbol Table is a database that contains information about, variables, subroutines, data structures , and so forth. The design used in this project allows to store RPG data declarations.

A Symbol is represented by its name and one or more SymbolTypes which stores the characteristics of the symbol such as the size, the number of decimals or the list of parameters in case of a function.
The subclasses of the SymbolType class are used to store this kind of information.
The key to access the symbol table is the name of the symbol. Symbols are organized in scopes. In this particular implementation of the RPG language all symbols are global therefore all the symbols are stored in the same scope.
For example consider a simple scalar definition in RPG:
D NBR S 8 0
The declaration defines NBR as a standalone field which is an ordinary scalar variable. It has a name (NBR), a definition type of ‘S’, 8 digits, and 0 decimals.
The representation of the declaration in the symbol table would be an instance of a Symbol class with a SymbolSpecifier which contains the relevant information about its type. The symbol is stored in a Map using the name as the key.

Now let’s consider an array declaration
D NBR S 8 0 DIM(10)
As in the previous case the representation in the symbol table would be an instance of a Symbol class with a SymbolSpecifier and an ArrayDeclarator.

The symbol table API provides the method to add a symbol to a particular scope.
During the declaration processing the RpgDeclarationVisitor class detects the data declaration, inspects the syntax tree and creates an instance of the symbol with the appropriate attributes.
For example take a look at the following code snippet :
Any RpgDeclarationVisitor::visitDspec(DspecContext *ctx) {
/* Attempts to create the symbol */
try {
std::shared_ptr<Symbol> symbol = this->parseSymbol(ctx);
compiler->symbolTable->add(symbol);
} catch(RpgException& e) {
std::cerr << "ERROR " << this->filename << "(" << ctx->getStart()->getLine() << ") : " << e.getMessage() << std::endl;
exit(-1);
}
return RpgParserBaseVisitor::visitDspec(ctx);
}
The processing of the parse tree is implemented within the parseSymbol method.
std::shared_ptr<Symbol> RpgDeclarationVisitor::parseSymbol(DspecContext *ctx) {
if (ctx->ds_name()) {
int size = 0;
int decimals = 0;
/* Symbol Name */
std::string tmp(ctx->ds_name()->getText());
std::string name = trim(tmp);
if(!name.empty()) {
/* Size and decimals */
size = stoi(ctx->TO_POSITION()->getText());
if (ctx->DECIMAL_POSITIONS()) {
if (is_number(ctx->DECIMAL_POSITIONS()->getText())) {
decimals = stoi(ctx->DECIMAL_POSITIONS()->getText());
if(decimals > 0) {
throw RpgException( ctx->getText() + " DECIMAL not supported");
}
}
}
/* Creates the symbol and the specifier */
std::shared_ptr<Symbol> symbol = std::make_shared<Symbol>(name, ctx->ds_name()->getStart()->getLine());
std::shared_ptr<SymbolSpecifier> specifier = std::make_shared<SymbolSpecifier>("S", size, decimals);
for (auto keyword : ctx->keyword()) {
if (keyword->keyword_dim()) {
int arraySize = stoi(keyword->keyword_dim()->simpleExpression()->getText());
std::shared_ptr<ArrayDeclarator> declarator = std::make_shared<ArrayDeclarator>(arraySize);
symbol->addDeclarator(declarator);
}
if (keyword->keyword_inz()) {
if(keyword->keyword_inz()->simpleExpression()->expression()) {
std::shared_ptr<Expression> expression = RpgVisitor::parseExpression(keyword->keyword_inz()->simpleExpression()->expression());
specifier.get()->setValue(expression);
} else {
std::shared_ptr<Expression> expression = RpgVisitor::parseExpression(keyword->keyword_inz()->simpleExpression());
specifier.get()->setValue(expression);
}
}
}
symbol->addSpecifier(specifier);
return symbol;
}
throw RpgException( ctx->getText() + " INVALID identifier ");
}
throw RpgException( ctx->getText() + " UNABLE to parse declaration ");
}
Although the Symbol Table structure is able to represent the typical RPG data declaration and LLVM provides support for fixed point arithmetic and data types for the scope of this project only the 64 bits integer type is supported.
Abstract Syntax Tree (AST)
The second pass of the compiler consists of the processing of the code statements and expressions and generating the AST.
All the nodes in the AST are subclasses of the Node class, which store information about the statement such as the line in the source code, the type and the accept method invoked by the visitor when traversing the tree.

The class diagram is a simplified version of the actual AST but provides the basic idea behind the data structure. The Node class contains a Vector of Node instances that implement the tree structure.
The RpgCodeVisitor extends the ANTLR generated visitor and implements the logic to create the tree structure creating and inserting the nodes into the appropriate branch.For example, when the parser detects an assignment statement it extracts the relevant information from the parse tree, creates the appropriate Node subclass and inserts it into the AST.
antlrcpp::Any RpgCodeVisitor::visitCsEVAL(CsEVALContext *ctx) {
if(ctx->target()) {
std::string target = ctx->target()->getText();
/* Parse the right side of the assignment */
std::shared_ptr<Expression> expression =
parseExpression(ctx->fixedexpression->expression());
/* Creates the assignment statement node */
std::shared_ptr<AssignmentStatement> assignment =
AssignmentStatement::create(
target,
expression,
ctx->getStart()->getLine());
/* Add the node to the AST */
addNode(assignment);
}
return RpgParserBaseVisitor::visitCsEVAL(ctx);
}
The addNode method implements the logic to insert the new Node into the proper position within the tree.
Each Node implements the accept method which takes a Generator class as parameter and invokes the correspondent visit method implementing the visitor pattern functionality.
class AssignmentStatement : public Statement {
public:
/* Creates the assignment statement node */
llvm::Value *accept(Generator *v, void *param = nullptr) override {
return v->visit(this,param);
}
};
The code Generator is the base class, declares a visit method, which takes the Node as an argument, for each subclass of Node. The concrete GeneratorLLVM is derived from the Generator class and implements the visit methods, each method implements part of the code generation for the specific AST Node. The instructions produced during the code generation are maintained by the GeneratorLLVM class through the LLVM API described later.
class Generator {
public:
virtual void declare(Symbol *) = 0;
virtual llvm::Value* visit(AssignmentStatement *assignment,void *param)=0;
virtual llvm::Value* visit(MathExpression *expression,void *param)=0;
virtual llvm::Value* visit(ComparisonExpression *expression,void *param)=0;
virtual llvm::Value* visit(IntegerLiteral *integer,void *param)=0;
virtual llvm::Value* visit(Identifier *string,void *param)=0;
virtual llvm::Value* visit(SelectStatement *select,void *param)=0;
virtual llvm::Value* visit(ForStatement *loop,void *param)=0;
virtual llvm::Value* visit(SubroutineDeclaration *subroutine,void *param)=0;
virtual llvm::Value* visit(SubroutineInvocation *subroutine,void *param)=0;
};
LLVM IR API
So far we took a look to the parser implementation and the data structures required to capture the relevant information about the RPG source code, the next step consists of generating the IR representation.
Before proceeding, it is necessary to provide detail about the API available in LLVM to generate the IR.
There are three main constructs required to work with the IR: llvm::Module, llvm::IRBuilder and llvm::Context.
The llvm::Module class is the top-level container used to store the code, it provides methods to define functions and global variables.
The llvm::IRBuilder is a helper object that provides the methods to generate LLVM instructions such as store, load, add, etc, keeps track of the position where the instructions are inserted and provides methods to set the insert position.
Finally the llvm::Context is an object which contains the internal LLVM data structures and it is required as a parameter in many of the IRbuilder methods.
In this project the llvm::Module, llvm::IRBuilder and llvm::Context are declared as attributes of the GeneratorLLVM class and initialized in the constructor.
class GeneratorLLVM : public Generator {
public:
GeneratorLLVM(std::string name, bool emitDebugInfo = false) {
/* Module instantiation */
this->module = std::make_unique<llvm::Module>(llvm::StringRef(name),llvmContext);
/* IRBuilder instantiation */
this->builder = std::make_unique<llvm::IRBuilder<>>(llvmContext);
}
private:
std::unique_ptr<llvm::Module> module;
std::unique_ptr<llvm::IRBuilder<>> builder;
llvm::LLVMContext llvmContext;
}
Another key class of the LLVM IR API is the llvm::Value class which is the base class for all the computed values and other key classes like llvm::Instruction and llvm::Function. The LLVM IR API provides many other helper classes that return subclasses of llvm::Value, for example to represent a integer constant the API provides the llvm::ConstantInt::get method which returns an llvm::ConstantInt subclass. The code generator in this implementation makes use of this method,for example, when processing the IntegerLiteral nodes.
llvm::Value* GeneratorLLVM::visit(IntegerLiteral *integer,void *param) {
int64_t ivalue = stoi(integer->getValue());
/* Creates the LLVM constant representation */
return llvm::ConstantInt::get(llvmContext,llvm::APInt(64,ivalue,true));
}
The llvm::Value is also the base class of llvm:BasicBlock which is another important concept with the LLVM IR and represents a list of non-terminating instructions followed by a single terminator instruction.
To explain the basic idea of a llvm:BasicBlock let’s consider a function.
The body of the function is a llvm:BasicBlock where the non terminating instructions represent the logic of the code and the terminator instruction is the return instruction.A practical example of a function definition can be found when processing the SubroutineDeclaration node.
llvm::Value* GeneratorLLVM::visit(SubroutineDeclaration *subroutine) {
/* Lookup if the Module to find the function definition */
llvm::Function *function = module->getFunction(subroutine->getName());
if(function) {
/* Creates a new BasicBlock as the body of the function. */
llvm::BasicBlock *body =
llvm::BasicBlock::Create(llvmContext, "entry", function);
// Instruct the builder to generate the instruction in the body
builder->SetInsertPoint(body);
/* Emit the subroutine body, non-terminating instructions */
for (auto stmt = s>getNodes().begin(); stmt != s->getNodes().end();) {
stmt->get()->accept( this );
}
/* Insert the block terminator */
llvm::Value *ret =
llvm:: ConstantInt::get(llvmContext, llvm::APInt(32, 0, true));
builder->CreateRet(ret);
} else {
std::cout << subroutine->getName() << " not found!" << std::endl;
}
}
Generating the LLVM IR : Data Declarations
The generation of the LLVM IR happens in the GeneratorLLVM class, which implements the logic to translate the Symbol Table into data declaration and traverses the AST to produce the IR code instructions.
The GeneratorLLVM class acts like a visitor of the AST Node class which provides the accept method.
void GeneratorLLVM::process(std::shared_ptr<SymbolTable> symbolTable,std::shared_ptr<AST> ast) {
// Generates data declaration
std::map<...> global = symbolTable->getSymbols(0);
for(auto symbol = global.begin(); symbol != global.end();symbol++) {
declare(symbol->second.get());
}
// Generates the runtime initialization function
initializeRunTime(symbolTable);
// Generates code
for(node = ast->getNodes().begin();node!= ast->getNodes().end();++node) {
node->get()->accept(this);
}
}
The code is pretty straight forward. For each symbol in the symbol table a data declaration is produced. The last loop is used to traverse the AST and generates the required IR instructions for the execution of the code.
To have an idea generated LLVM IR, below an example for a basic RPG data declaration.
D COUNT S 8 0 D NBR S 8 0 D RESULT S 8 0 INZ(1)
As previously explained the GeneratorLLMV class defines two attributes that represent the interface with the LLVM libraries llvm::Module and llvm::IRBuilder.The declare method of the GeneratorLLVM makes use of llvm::Module to create the global variables.
void GeneratorLLVM::declare(class Symbol *symbol) {
// Declares a global variable
SymbolSpecifier *variable = symbol->getSpecifier();
if(variable) {
if( !module->getNamedGlobal(symbol->getName())) {
if(variable->getDecimals() == 0) {
module->getOrInsertGlobal(
symbol->getName(),
builder->getInt64Ty()
);
}
// Creates the variable
llvm::GlobalVariable *var =
module->getNamedGlobal(symbol->getName());
if(var) {
llvm::Constant *initValue =
llvm::ConstantInt::get(
llvmContext, llvm::APInt(64, 0, true)
);
var->setInitializer(initValue);
var->setLinkage(llvm::GlobalValue::CommonLinkage);
}
}
}
The method takes a Symbol as parameter, checks if the symbol is already defined within the module using module->getNamedGlobal(symbol->getName()) then creates the global variable executing module->getOrInsertGlobal(…).
As mentioned above this implementation supports only Integer types therefore the variable is created as int64.
The last step consists of initialization, which by default is set to 0.
// Data declarations @COUNT = common global i64 0 @NBR = common global i64 0 @RESULT = common global i64 0
The initializeRunTime is used to generate the code required for the data initialization.
In this example the RESULT variable specifies the initialization value of 1. In this implementation the initialization is intentionally generated as a separate function invoked when execution starts to generate the instructions when the initialization value is an expression.
D A S 8 0 INZ(1) D B S 8 0 INZ(A+1)
The initializeRunTime takes care of generating the INZ function, producing the code required to compute the expression and store the initialization value into the target variable.
void GeneratorLLVM::initializeRunTime(std::shared_ptr<SymbolTable> symbolTable) {
/* Emit the INZ function */
std::vector<llvm::Type*> params;
llvm::FunctionType *ft =
llvm::FunctionType::get(llvm::Type::getVoidTy(llvmContext),params,false);
llvm::Function *inz = llvm::Function::Create(ft,
llvm::Function::ExternalLinkage, "INZ", this->module.get());
llvm::BasicBlock *BB = llvm::BasicBlock::Create(llvmContext, "",inz);
builder->SetInsertPoint(BB);
/* Process the symbol table and create the initialization values */
std::map<..> global = symbolTable->getSymbols(0);
for(auto symbol = global.begin(); symbol != global.end();symbol++) {
SymbolSpecifier *specifier = symbol->second->getSpecifier();
if(specifier) {
llvm::Constant *initValue;
llvm::GlobalVariable *var = module->getNamedGlobal(symbol->first);
try {
std::shared_ptr<Expression> expression =
specifier->getValue();
if(expression) {
/* Evaluates the initialization expression */
llvm::Value* value = expression->accept(this);
/* Creates the store instruction */
builder->CreateStore(value,var);
}
} catch(RpgException& e) {
std::cerr << "ERROR " << this->filename << "(" <<
symbol->getLine() << ") : " << e.getMessage() << std::endl;
exit(-1);
}
}
}
/* Function terminator */
builder->CreateRetVoid();
if(llvm::verifyFunction(*inz)) {
std::cout << "verify function INZ failed!" << std::endl;
}
}
The implementation gives the opportunity to discover more about the LLVM API.
The llvm::FunctionType::get creates the signature of the function, in this case it is a void function with no parameters. The llvm::Function::Create invocation creates the function “INZ” within the current module.
The resulting IR output for RPG example above looks like this:
// Data declarations
@COUNT = common global i64 0
@NBR = common global i64 0
@RESULT = common global i64 0
// main
define i32 @main(i32 %0) {
entry:
call void @INZ() // Runtime initialization
ret i32 0
}
// Runtime initialization function
define void @INZ() {
store i64 1, i64* @RESULT, align 4 // INZ(1)
ret void
}
The code generator has included the invocation of the INZ function as the first statement in the main function, which ensures that the variables are initialized properly.
Generating the LLVM IR : Code Generation
The last phase of the code generator traverses the AST and emits the IR instructions required to implement the logic of the RPG program.
As explained in the AST section the GeneratorLLVM implements a visitor pattern which implements the visit method for each subclass of Node. The AssignmentStatement node contains the name of the target variable and the expression to be generated.
llvm::Value* GeneratorLLVM::visit(AssignmentStatement *assignment,void *param) {
/* Retrieve the global variable */
llvm::GlobalVariable* target =
module->getGlobalVariable(assignment->getTarget());
if(!target) {
std::cout << assignment->getTarget() << " not found!" << std::endl;
return nullptr;
}
if(assignment->getExpression()) {
/* Visit and resolve the expression */
llvm::Value* v = assignment->getExpression()->accept(this);
if(v) {
/* Emit the store instruction */
builder->CreateStore(v, target);
}
}
return target;
}
The implementation retrieve the variable form the global storage using the llvm::Module->getGlobalVariable method, visits the expression subtree to generate the IR instructions required to implement the calculation and finally generates the assignment instruction using the llvm::builder->CreateStore method.
RPG source code
C EVAL COUNT = 0
LLVM IR
store i64 0, i64* @COUNT, align 4
An expression is generated visiting the MathExpression AST node which contains the left and right side and the operator stored as token type.
llvm::Value* GeneratorLLVM::visit(MathExpression *expression) {
std::cout << expression->toString() << std::endl;
llvm::Value* L = expression->getLeft()->accept(this,param);
llvm::Value* R = expression->getRight()->accept(this,param);
switch (expression->getType()) {
case Token::PLUS:
return builder->CreateAdd(L, R, "addtmp");;
case Token::MINUS:
return builder->CreateSub(L, R, "subtmp");
case Token::MULTIPLY:
return builder->CreateMul(L, R, "multmp");
case Token::DIVIDE:
return builder->CreateSDiv(L, R, "divtmp");
}
return nullptr;
}
Based on the operator the llvm::builder emits the correspondent IR instruction, the “tmp” parameter is used internally by LLVM to represent temporary values.
RPG source code
C EVAL COUNT = A + 1
LLVM IR
%1 = load i64, i64* @A, align 4 %addtmp = add i64 %1, 1 store i64 %addtmp, i64* @COUNT, align 4
In this case LLVM implementation figured out that the result of 2 multiplied by 1 is 2 so there is no need to emit the multiplication instruction.
The processing of comparison expressions works in a very similar way, generating the IR compare instructions.
llvm::Value *GeneratorLLVM::visit(ComparisonExpression *expression) {
llvm::Value* L = expression->getLeft()->accept(this,param);
llvm::Value* R = expression->getRight()->accept(this,param);
switch (expression->getType()) {
case Token::EQUAL:
return builder->CreateICmp(llvm::ICmpInst::ICMP_EQ,L,R,"");
case Token::NE:
return builder->CreateICmp(llvm::ICmpInst::ICMP_NE,L,R,"");
case Token::LE:
return builder->CreateICmp(llvm::ICmpInst::ICMP_SLE,L,R,"");
case Token::GE:
return builder->CreateICmp(llvm::ICmpInst::ICMP_SGE,L,R,"");
case Token::GT:
return builder->CreateICmp(llvm::ICmpInst::ICMP_SGT,L,R,"");
case Token::LT:
return builder->CreateICmp(llvm::ICmpInst::ICMP_SLT,L,R,"");
default:
break;
}
return nullptr;
}
The ComparisonExpression is used in the RPG SELECT statement to evaluate the WHEN condition.
C SELECT C WHEN NBR = 0 C EVAL RESULT = 0 C WHEN NBR = 1 C EVAL RESULT = 1 C OTHER C EVAL RESULT = A + B C ENDSL
The SELECT statement is a little bit more complicated and gives the opportunity to explore additional functionality of the LLVM API where conditional branching is involved.
llvm::Value* GeneratorLLVM::visit(SelectStatement *select) {
/* Create the SELECT block linked to the parent */
llvm::Function *selectBlock = builder->GetInsertBlock()->getParent();
/* Creates a block for the ENDSL, does not requires a terminator */
llvm::BasicBlock *selectEnd = llvm::BasicBlock::Create(llvmContext, "endselect");
/* Creates a block for the OTHER clause (if any) */
llvm::BasicBlock *otherBlock = nullptr;
if (select->getOther()) {
otherBlock = llvm::BasicBlock::Create(llvmContext, "other");
}
// Creates a block for each WHEN clause
for (int i = 0; i < select->getWhen().size(); i++) {
llvm::BasicBlock *trueBlock = llvm::BasicBlock::Create(llvmContext, "when_true", selectBlock);
llvm::BasicBlock *falseBlock;
// Last WHEN clause, if the OTHER is present became the false block
if (i == select->getWhen().size() - 1) {
if (otherBlock) {
falseBlock = otherBlock;
} else {
falseBlock = selectEnd;
}
} else {
falseBlock = llvm::BasicBlock::Create(llvmContext, "else");
}
llvm::Value *condition =
select->getWhen().at(i)->getExpression()->accept(this);
builder->CreateCondBr(condition, trueBlock, falseBlock);
// Emits the true block
builder->SetInsertPoint(trueBlock);
for (auto stmt = select->getWhen().at(i)->getNodes().begin();
stmt != select->getWhen().at(i)->getNodes().end(); ++stmt) {
stmt->get()->accept(this );
}
builder->CreateBr(selectEnd);
// Emits the true false block
selectBlock->getBasicBlockList().push_back(falseBlock);
builder->SetInsertPoint(falseBlock);
}
// Emits the other block
if (otherBlock) {
selectBlock->getBasicBlockList().push_back(otherBlock);
builder->SetInsertPoint(otherBlock);
for (auto stmt = select->getOther()->getNodes().begin(); stmt != select->getOther()->getNodes().end(); ++stmt) {
stmt->get()->accept(this,param);
}
builder->CreateBr(selectEnd);
}
/* Emits the ENDSL block */
selectBlock->getBasicBlockList().push_back(selectEnd);
builder->SetInsertPoint(selectEnd);
}
The key concept for is the LLV llvm::builder->CreateCondBr(condition, trueBlock, falseBlock) method which accepts a condition instruction and two llvm::BasicBlock, the first represent the instruction to execute if the condition is true the second if the condition is false.
The complexity of this method consists of creating the proper block chain so that if the condition is true the corresponding instructions are executed otherwise proceed to evaluate the next condition. The OTHER clausole is optional and kept in consideration only if present.
LLVM IR
%1 = load i64, i64* @NBR, align 4 /* evaluates WHEN NBR = 0 */ %2 = icmp eq i64 %1, 0 br i1 %2, label %when_true, label %else /* WHEN NBR = 0 is true */ when_true: store i64 0, i64* @RESULT, align 4 br label %endselect /* WHEN NBR = 0 is false */ else: %3 = load i64, i64* @NBR, align 4 /* evaluates WHEN NBR = 1 */ %4 = icmp eq i64 %3, 1 br i1 %4, label %when_true1, label %other2 /* WHEN NBR = 1 is true */ when_true1: store i64 1, i64* @RESULT, align 4 br label %endselect /* WHEN NBR = 1 is false */ other2: /* OTHER */ %5 = load i64, i64* @A, align 4 %6 = load i64, i64* @B, align 4 %addtmp = add i64 %5, %6 store i64 %addtmp, i64* @RESULT, align 4 store i64 2, i64* @COUNT, align 4 /* ENDSL */ endselect:
The very last RPG statement is the RPG FOR loop which is represented by the ForStatement AST node. Similar to the SELECT statement the key is the llvm::builder->CreateCondBr which evaluates if the loop has completed.
In addition to the conditional branching it is required to generate the instructions required to increment the loop variable.
llvm::Value *GeneratorLLVM::visit(ForStatement *loop,void *param) {
/* Initialize the loop variable */
llvm::Value *startVal = loop->getStart()->accept(this);
/* Loop variable */
llvm::GlobalVariable* variable =
module->getGlobalVariable(loop->getStart().get()->getTarget());
llvm::Function *forLoop = builder->GetInsertBlock()->getParent();
llvm::BasicBlock *loopBody = llvm::BasicBlock::Create(llvmContext, "loop", forLoop);
/* Start insertion in loop body */
builder->SetInsertPoint(loopBody);
/* Adds the statements to the loop body */
for (auto stmt = loop->getNodes().begin(); stmt != loop->getNodes().end(); ++stmt) {
stmt->get()->accept(this);
}
/* Computes the step value */
llvm::Value *step = nullptr;
if(loop->getStep()) {
step = loop->getStep()->accept(this);
} else {
/* If not specified step is 1 */
step = llvm:: ConstantInt::get(llvmContext, llvm::APInt(64, 1, true));
}
/* Emits instructions to update the loop variable */
llvm::Value* next = builder->CreateLoad(variable);
llvm::Value* tmp = builder->CreateAdd(next, step, "next");
builder->CreateStore(tmp, variable);
/* Create the "exit loop" block */.
llvm::BasicBlock *loopEnd = builder->GetInsertBlock();
llvm::BasicBlock *afterBB = llvm::BasicBlock::Create(llvmContext, "exitLoop", forLoop);
llvm::Value *endCond = loop->getEnd()->accept(this);
/* Insert the conditional branch */
builder->CreateCondBr(endCond, loopBody, loopEnd);
/* Restore the insert point the end of the loop */
builder->SetInsertPoint(loopEnd);
}
RPG
C FOR COUNT = 2 TO NBR C EVAL A = B C EVAL B = RESULT C ENDFOR
LLVM IR
/* FOR COUNT = 2 initialize COUNT */ store i64 2, i64* @COUNT, align 4 loop: %7 = load i64, i64* @B, align 4 store i64 %7, i64* @A, align 4 %8 = load i64, i64* @RESULT, align 4 store i64 %8, i64* @B, align 4 /* UPDATE COUNT */ %9 = load i64, i64* @COUNT, align 4 %next = add i64 %9, 1 store i64 %next, i64* @COUNT, align 4 /* TO NBR compare if COUNT == NBR */ %10 = load i64, i64* @COUNT, align 4 %11 = load i64, i64* @NBR, align 4 %12 = icmp sle i64 %10, %11 /* REPEAT from label loop or exit */ br i1 %12, label %loop, label %exitLoop exitLoop:
In the output IR is relatively easy to identify how the IR instructions have been generated by the llvm::builder.
It is possible to produce a graphical representation of the building blocks generated for the FIB subroutine using the LLVM opt tool to generate a graphic representation of the logic of the algorithm.
strumenta@system-76:~hello$ llvm-as < hello.ll | opt -analyze -view-cfg

Runtime functions
The LLVM API provides the methods to create and invoke functions defined within the module. It is possible to invoke external functions implemented in a library such as the standard C library function printf.
To call the printf function from the IR it is required to provide the function definition and provide the parameters required.
The RPG code below implements the algorithm to compute the Fibonacci’s number taken from an example provided by Franco Lombardo available in the Jariko GitHub repository.
* Calculates number of Fibonacci in an iterative way D ppdat S 8 D NBR S 8 0 D RESULT S 8 0 INZ(0) D COUNT S 8 0 D A S 8 0 INZ(0) D B S 8 0 INZ(1) C *entry plist C parm ppdat I * C Eval NBR = 55 C EXSR FIB C DSPLY RESULT *--------------------------------------------------------------* C FIB BEGSR C EVAL COUNT = 0 C SELECT C WHEN NBR = 0 C EVAL RESULT = 0 C WHEN NBR = 1 C EVAL RESULT = 1 C WHEN NBR = 2 C EVAL RESULT = 2 C OTHER C FOR COUNT = 2 TO NBR C EVAL RESULT = A + B C EVAL A = B C EVAL B = RESULT C DSPLY RESULT C ENDFOR C ENDSL C ENDSR C SETON LR
The implementation of the DSPLY performs the invocation of the standard printf C function, it is slightly different from the original RPG functionality as it can only accept a variable as argument.
To invoke the printf function it is required to provide the function definition, the format string and the return value. The initializeRunTime takes care of creating the format string and the declaration of the external function.
/* Emit the format string for the printf */
std::string str = "%lld\n";
auto charType = llvm::IntegerType::get(llvmContext, 8);
/* Initialize the vector */
std::vector<llvm::Constant *> chars(str.length());
for(unsigned int i = 0; i < str.size(); i++) {
chars[i] = llvm::ConstantInt::get(charType, str[i]);
}
/* Add '\0' at the end of the string */
chars.push_back(llvm::ConstantInt::get(charType, 0));
/* Initialize the string from the characters */
auto stringType = llvm::ArrayType::get(charType, chars.size());
/* declaration statement */
auto globalDeclaration = (llvm::GlobalVariable*) module->getOrInsertGlobal("pstr", stringType);
globalDeclaration->setInitializer(llvm::ConstantArray::get(stringType, chars));
globalDeclaration->setConstant(true);
globalDeclaration->setLinkage(llvm::GlobalValue::LinkageTypes::PrivateLinkage);
globalDeclaration->setUnnamedAddr (llvm::GlobalValue::UnnamedAddr::Global);
std::vector<llvm::Type*> pparams;
pparams.push_back(llvm::Type::getInt8PtrTy(llvmContext));
llvm::FunctionType *pft = llvm::FunctionType::get(llvm::Type::getInt32Ty(llvmContext),pparams, true);
llvm::Function *printf = llvm::Function::Create(pft, llvm::Function::ExternalLinkage, "printf", this->module.get());
The method basically transforms the format string “%lld\n” into a LLVM global declaration, and declares the printf function as external with a string parameter and variable list of arguments.
It translate to the following in LLVM IR
llvm::Value *GeneratorLLVM::visit(DisplayStatement *dsply,void *param) {
auto charType = llvm::IntegerType::get(llvmContext, 8);
llvm::Value* format =
llvm::ConstantExpr::getBitCast(module->getNamedGlobal("pstr"),
charType->getPointerTo());
llvm::Value* variable =
builder->CreateLoad(module->getGlobalVariable(
dsply->getIdentifier()->getValue()));
std::vector<llvm::Value *> args;
args.push_back(format);
args.push_back(variable);
llvm::Function *target = module->getFunction("printf");
llvm::CallInst *printf = builder->CreateCall(target, args);
return printf;
}
This is a little bit more complex than usual because the C printf function expects a pointer to a string for the format argument and must be converted using llvm::ConstantExpr::getBitCast.The arguments of the are pushed into a vector, the printf function declaration is retrieved from the module and finally it is possible to create the invocation statements using builder->CreateCall.
RPG CODE
C DSPLY RESULT
LLVM IR
%2 = load i64, i64* @RESULT, align 4 %3 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([5 x i8], [5 x i8]* @pstr, i32 0, i32 0), i64 %2)
We can run the FIBCALC.rpgle generating the LLVM IR code using the rpg compiler.
strumenta@system-76:~fib$./rpg CALCFIB.rpgle > calcfib.ll Compiling file:CALCFIB.rpgle
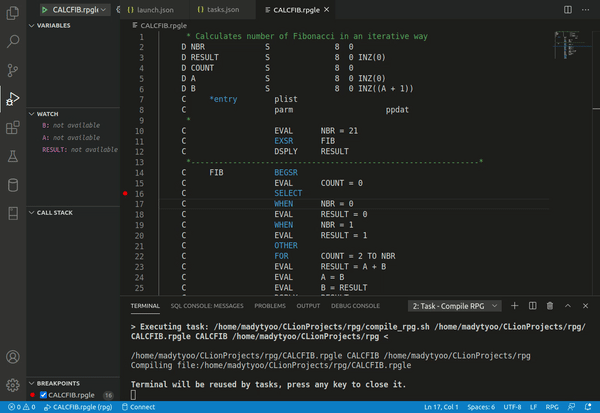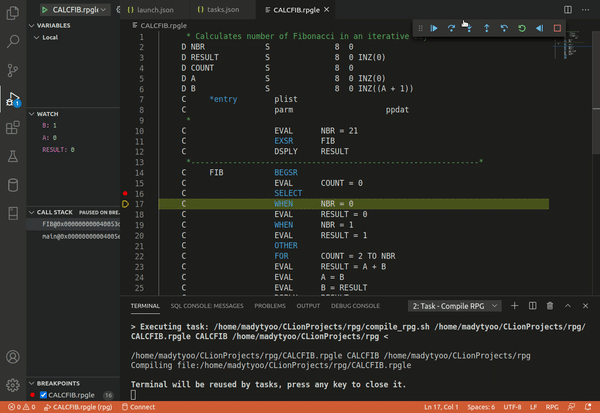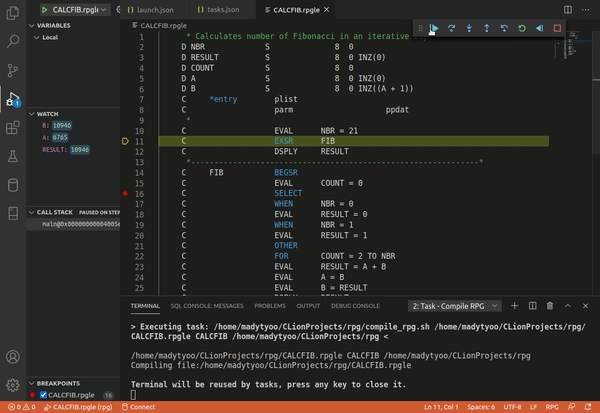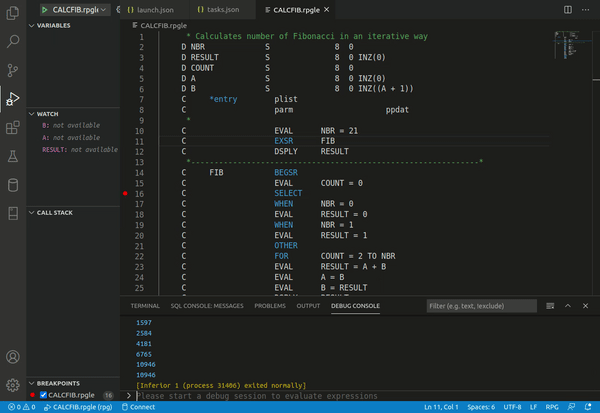
Debugging
Modern software development usually happens within an enviroment (IDE) which provides source level debugging making possible to step through execution a line at a time, inspect the variables and set breakpoints. It
In order to support source level debugging, the compiler has to include additional information to identify the corresponding positions in the source code.
LLVM provides the llvm::DIBuilder for generating debug information.
The compiler described in this project can generate the debug information using the –debug option on the command line.
LLVM uses a format called DWARF which is a compact encoding to represent types, code and variable locations within the source code.
Debuggers like gdb support the DWARF format giving the opportunity to debug the code at source level.
After generating the Fibonacci IR with the debug information it is possible to make the executable using clang.
strumenta@system-76:~fib$./rpg --debug CALCFIB.rpgle > calcfib.ll strumenta@system-76:~fib$ clang -x ir calcfib.ll -o calcfib.out
Microsoft(TM) Visual Studio Code is an IDE that can use gdb as an integrated debugger but with a more intuitive user interface.
Conclusions
In this article we have seen how we could build a simple, but efficient compiler. By leveraging LLVM it is possible to build industrial-grade compilers with a limited investment. Using a product as mature as LLVM brings some added benefits, like the advanced support for debugging.
The LLVM infrastructure provides tools and libraries to generate the IR and produce the binary executable code.
When we complement LLVM with ANTLR for the parser generation we get a very effective combination.
While these great tools reduce significantly the cost of developing a compiler, a significant effort would be still required to implement the full functionality available in a high level language like RPG such as different data types, data structures, string representation and manipulation, built-in function, file management and so forth.
To simplify the process, it would be possible to take advantage of the existing C/C++ libraries creating an interface for the functions that are common to both languages (i.e. math functions) and provide the implementation for those that are not available.
In any case we hope this tutorial will help you getting started with LLVM, and at the very least understand its potential.
Read more:
If you want to understand the difference between compiler and interpreter, you can read our article The Difference Between a Compiler and an Interpreter.
To discover more about how to write a python parser, you can read Parsing In Python: Tools And Libraries
To understand how to use ANTLR, you can read The ANTLR Mega Tutorial
To discover more about parsing SQL, you can read Parsing SQL

