")
Introduction
In this article, we explain the concepts behind syntactic and semantic highlighting. Humans are great at associating colors with concepts. We link red traffic lights to stopping and blue markers on showers to cold water. The information flows quickly and effortlessly. In programming, we leverage this ability by highlighting pieces of code, making the programs easier to understand and debug.
We then apply the theory by implementing highlighting in Kuki, a language server we created in a previous article for describing cooking recipes. The result is going from no color:
To syntactically highlighted code:
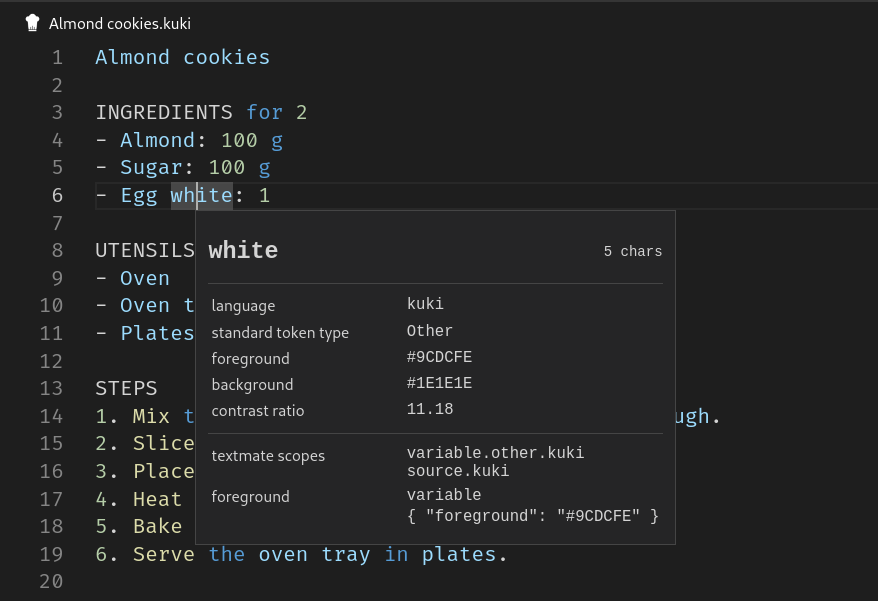
And finally semantically enriched highlighting:
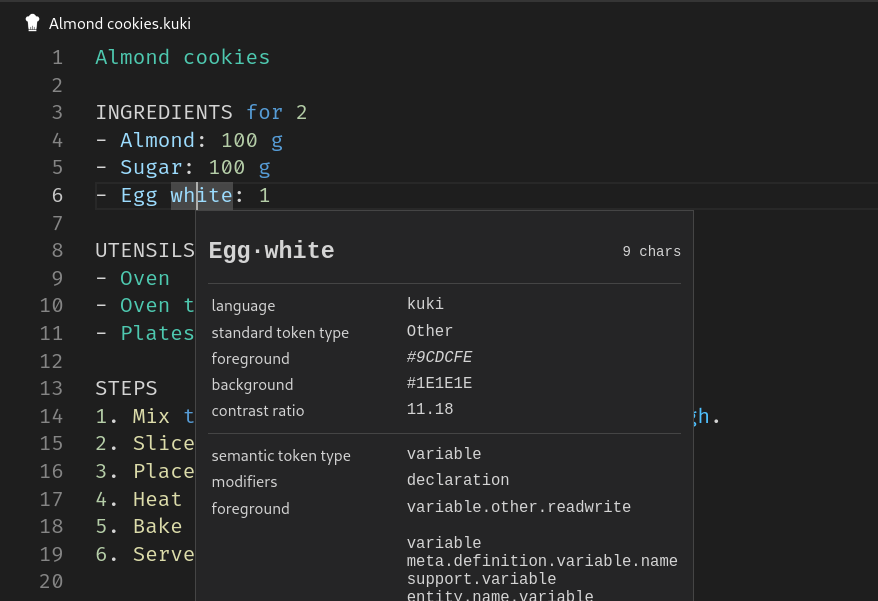
The entire codebase is available on Github on the highlighting branch of the Kuki repository. To keep the article lightweight, we will reference files from the repository and focus on explaining the most important points.
In the following sections, we will introduce syntax highlighting and illustrate how this can be implemented in our example. Then, we will extend our discussion and example implementation to semantic highlighting. Finally, we will discuss the differences between the two approaches.
Syntax highlighting
The idea behind syntax highlighting is to divide the source text into tokens and assign a category to each token depending on its textual representation. For example, in the following javascript code:
if (myNumber === 10) return "My number is ten";
The tokens if and return are keywords, myNumber is an identifier, === is an operator, 10 is a number, “My number is ten” is a string, and the parentheses and the semicolon are punctuation marks.
Notice that we can deduce that without context just by looking at the characters of each token. We express these character patterns with regular expressions:
| Pattern | Explanation |
| if | return | A sequence of characters exactly matching if or return is a keyword |
| “.*?” | Characters surrounded by double quotes are strings |
| [a-zA-Z]+ | A sequence of letters is an identifier |
Consider that prioritization of the patterns is essential; otherwise, if will match both the keyword and the identifier rule.
Most modern editors, including Vscode and IntelliJ, use Textmate grammars to define syntax highlighting rules. They comprise a prioritized list of rules that map regular expression patterns to scopes. Scopes are dot-separated names like entity.name.function.kuki.
Themes select scopes using CSS style selectors and style them with colors and font properties. For example, the selector entity.name.function assigns styles to all function names in any language, while entity.name would apply styles to all the names. These styles can be overridden for Kuki function names by using the entity.name.function.kuki selector because it has the highest specificity.
The article’s goal is not to teach how Textmate grammars work, there is already great documentation online. However, let’s go over the thinking process behind defining the syntax rules for our cooking language:
Syntax highlighting in Kuki
Textmate grammars can be written in XML, JSON or YAML format. In this case, we decided to write the grammar in JSON format. Here is a summary of the rules:
| Rule | Pattern | Scope |
| Section titles | INGREDIENTS|UTENSILS|STEPS | entity.name.section.kuki |
| Functions | Mix|Slice|Place|Add… | entity.name.function.kuki |
| Keywords | the|into|in|to|for|and | keyword.other.kuki |
| Numbers | \d+(\.\d+)? | constant.numeric.kuki |
| Punctuation | :|-|\. | punctuation.kuki |
| Variables | [a-zA-Z]+ | variable.other.kuki |
Textmate grammars are free form, meaning you can assign any scope name to the tokens. However, there is a standardized set of names that is highly recommended to use. That way, existing themes will be readily compatible with your language.
That is why we aim to pick the closest match even though the standard names do not perfectly fit our esoteric programming language. As language engineers, we focus on assigning the correct scopes to each token; then, theme builders style the tokens with pretty colors. Here is the result with a couple of different built-in Vscode themes:

Looking good, but what if we want to distinguish ingredients from utensils? This is not possible with syntax highlighting because they are both syntactically in the same category.
We need context to determine that almond is actually an ingredient because it has been declared in the ingredients block. The same happens in standard programming languages when we want to differentiate local variables from global variables or parameters. Semantic highlighting fixes this problem.
Semantic highlighting
Semantic highlighting uses context-aware language comprehension tools to assign refined categories to tokens.
It is usually found in the realm of language servers. Whenever code changes, the editor requests the server for semantic tokens through the Language Server Protocol (LSP). Thanks to advanced parsers, language servers can understand source files deeply, allowing them to specify more fine-grained semantic categories.
The list of standard semantic categories is fixed. It can be expanded with custom categories, but this should be avoided if possible. In addition to categories, the protocol defines standard semantic modifiers. Tokens can have multiple modifiers at once. For example, a variable may have the read-only and declaration modifiers.
We can inspect the syntactic and semantic scopes assigned to a token by using Vscode’s scope inspector:
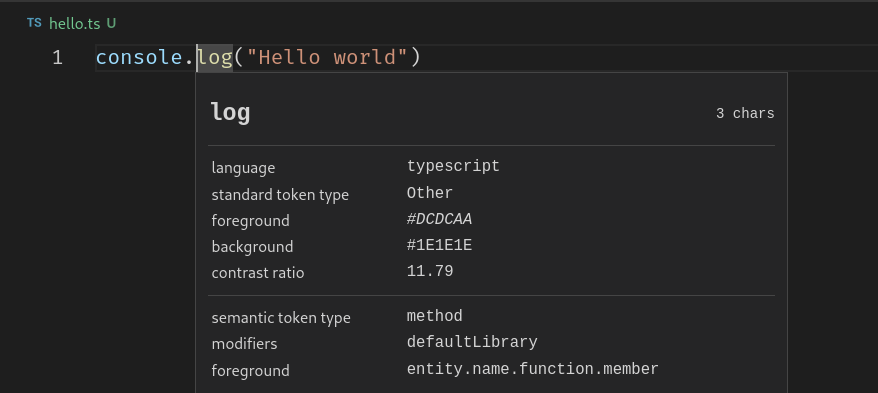
Open the command palette (F1 in my configuration) and search for scope inspector. When you place the cursor over a token, a context menu appears with all the scope information. This is very helpful during development for checking and debugging your rules.
Let’s improve the highlighting of Kuki code by adding semantic highlighting capabilities to the language server.
Semantic highlighting in Kuki
The goal is to semantically differentiate identifiers into recipe titles, ingredients, and utensils:
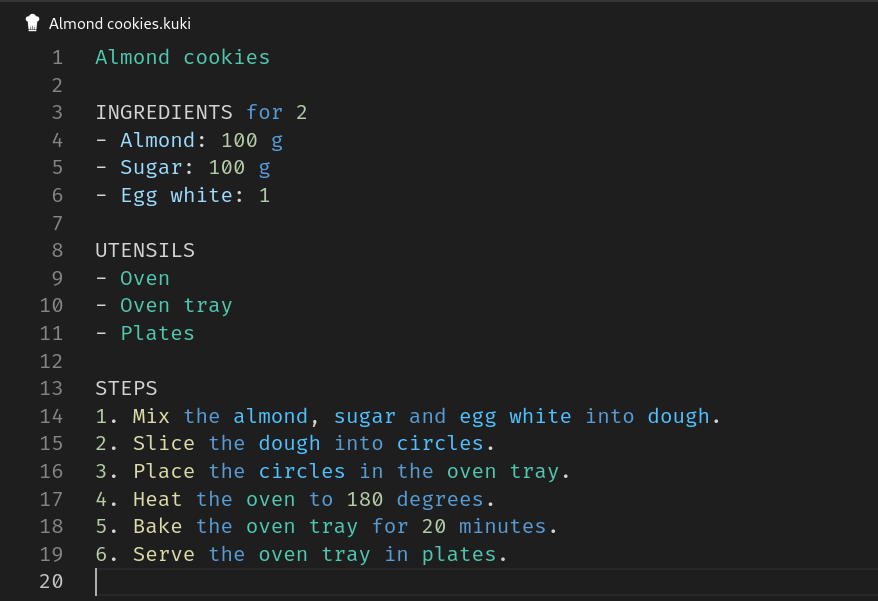
The Kolasu language server plugin defines semantic tokens as a range of code with a semantic category and a list of modifiers:
data class SemanticToken(
val position: Position,
val type: SemanticTokenType,
val modifiers: List<SemanticTokenModifier>)
The plan is to create a list of semantic tokens, one per identifier, and list them in the order they appear in the source code. The language server plugin will then encode this information into a list of numbers following the encoding rules the LSP uses for performance reasons. At the time of writing, this feature is unavailable in the plugin’s public release; it will be available once this issue is marked as closed.
To implement this, we override the semanticTokensFull request of the KolasuServer class in Main.kt. In particular, we create a semantic token for the recipe title with the category Type:
val titlePosition = recipe.name.position tokens.add(SemanticToken(titlePosition, SemanticTokenType.TYPE, listOf()))
We then add a semantic token with the declaration modifier for each ingredient and utensil declaration:
for (ingredient in recipe.ingredients) {
addIngredientAt(ingredient.declaration.position, isDeclaration = true)
}
for (utensil in recipe.utensils) {
addUtensilAt(utensil.declaration.position, isDeclaration = true)
}
Finally, for each item reference, we check the parent node’s type to determine if it is an ingredient or a utensil reference:
fun addTokenFor(item: ItemReference) {
when (item.reference.referred?.parent) {
is Ingredient -> addIngredientAt(item.position)
is Utensil -> addUtensilAt(item.position)
else -> addIngredientAt(item.position)
}
}
We finish the implementation by calling the plugin’s encode function:
return CompletableFuture.completedFuture(encode(tokens))
Syntactic vs semantic highlighting
Here is a table that highlights (heh) the differences between syntactic and semantic highlighting:
| Feature | Syntax highlighting | Semantic highlighting |
| Performance | Fast | Can be arbitrarily slow |
| Runs on | Same thread as renderer (no delay) | In the language server process |
| Reusability | Editors that support Textmate grammars | Editors that support the Language Server Protocol |
| Limitations | Limited to regular expressions | Unbounded logic complexity |
As a general rule, syntactic highlighting is more performant and user-friendly because it is fast and introduces no delay. However, semantic highlighting enables arbitrarily complex rules for coloring code and is available in all the editors that support the LSP.
The good news is that we don’t need to choose between one or another. A language can be highlighted both syntactically and semantically. Semantic rules take precedence over syntax rules, but if they are not present or supported by the theme, syntactic rules will apply.
Summary
We have learned how to add syntactic and semantic highlighting to programming languages. For language servers, syntax highlighting happens on the client side by providing Textmate grammars in XML, JSON, or YAML format.
Semantic highlighting works on top of syntactic highlighting by adding contextual information.
The LSP specifies a list of categories and modifiers we can programmatically set to tokens in the code. The themes will use this to pick the correct color.
By leveraging the power of Kolasu and its language server plugin, we can focus on defining the data (the syntax grammar and the list of semantic tokens), and the rest will be taken care of.
Want to put your semantic highlighting tools into practice? How about grabbing the code from Github and assigning different modifiers to solid and liquid ingredients? Or visualizing ingredients high in protein prominently? With semantic highlighting, the logic used to highlight code is limitless.