NDepend is a tool that helps .NET developers to write beautiful code
This is a definition that does not come from the official documentation, but from a post on the blog of its developer. We like it because it is more interesting than the technical one: NDepend is a static analysis tool for .NET code (i.e., .NET assemblies). More importantly, it gives a more holistic picture of what static analysis can do for your project. In fact, not all developers agree on what static analysis can and should actually do. This is also due to the fact that the concept and the tools themselves have evolved during the years.
So, what can NDepend do for you? It can:
- calculate standard metrics to understand your project
- check whether your code respect standard quality rules
- provide you with a tool to create your own metrics and enforce your custom rules
It integrates with Visual Studio, continuous integration tools (e.g., JetBrains TeamCity) and all sort of tools that works around the building of code like (Visual Studio) Team Foundation Server.
NDepend is a tool that affects mostly the life of developers, but it is relevant to the job of software architects, too. That is because it can give a high level picture of the quality of the code. So it can provide information to the people that make decisions on how to design software. A software architect could use the tool on its own, or use it to guide developers in developing software.
How We Are Reviewing NDepend
Programming is a peculiar job in many ways. The one that interest us right now is how much varies the quality of its practitioners is. This is also compounded by the fact that international projects and collaborations are pretty common. In traditional professions this an issue that is dealt with people higher in the management chain, instead this is actually the norm for many programmers.
This lead to the issue that all sorts of people can read this article, each we different assumptions. So we think it is necessary to make a few notes to have everybody on the same page.
NDepend Is Commercial Software
NDepend is a commercial tool that is reasonably priced for a company (see the pricing model), but it can be too costly for individual developers in certain countries. We cannot say if NDepend is worth its price for you, we can only review what it does.
If you are unfamiliar with commercial professional software you might be surprised by the fact that it has good documentation. And they even present all the features of their tool! Joking aside, this is obviously normal for commercial software, but it is sadly not the norm for open source software, even in the case of successful projects. So the official documentation gives you the information you need, though it might be a little outdated (e.g., it talks about a rumor on version of C# of VB.NET successive to the number five) and the formatting could be improved.
There are also good explanations accessible while working with the tool.

For example, if your project violates a rule, you can see what the rule means and how to fix the underlying issue.
What We Are Reviewing
NDepend mainly works as a Visual Studio plugin, so it is available for all recent editions of Visual Studio, even the free Visual Studio Community. It would not work with the older free Visual Studio Express edition. It can also be used independently of Visual Studio with its own UI, called Visual NDepend.
As said before, it can also be integrated with several tools used in the build process. We are not going to the review that part because the static analysis features are the same of the Visual Studio plugin. The only differences are obvious ones, such as the fact that it can block the build process in case of a failure of a quality check.
We have tested the NDepend Version v2017.2.2.
What Kind Of Static Analysis?

We have already mentioned that there are many kinds of static analysis tools. They all work on code, so they all work in the realm of developers, but they can be created for different people.
The NDepend documentation mentions an integration with SonarQube, another static analysis tool. It also says, essentially, that their tool is higher level than SonarQube:
Basically the Roslyn analyzers and SonarQube rules are good at analyzing what is happening inside a method, the code flow while the NDepend code model, on which the NDepend rules are based, is optimized for a 360 view of particular higher-scale areas including OOP, dependencies, metrics, breaking changes, mutability, naming…
Concretely Roslyn analyzers and SonarQube rules can warn about problems like a reference that doesn’t need to be tested for nullity because in the actual scope it cannot be null, while NDepend can warn you about too complex classes or components, and offer advices about how to refactor to make the code cleaner and more maintainable.
You should always be cautious with the information that a seller gives about its product, but it seems to us a good comparison. Nothing is presented as better, both tools have their uses. NDepend is a tool designed for an higher level of static analysis, it helps you to design better software, rather than simply to write more correct code.
This means that is most useful if your work consist in taking care of the whole design process. Depending on the organization you work in, this might mean that you are a software architect, a senior developer or the only developer. It also mean that some features can be of a limited use for a beginner developer working on something as a library.
The Static Analysis Engine
The core of NDepend is a static analysis engine that can detect some properties of the code and, more importantly, whether it respects a certain rule.
The foundation of the engine are the code metrics, they are used by the rules and to create visualizations of the project. They range from basic statistical data about the whole project, and its constituent parts, to complex structural measures.
An example of the first is the number of lines of code, that is measured for all levels: application, assembly, namespace, class (type) and method. These are easy to understand, although they are generated based on PDB files, so they do not depend on the physical lines of code, but what they call logical Lines of Code (LOC) instead. PDB files are also used to calculate how many lines of comments there are. PDB files contain are generated by the compiler and contain debugging information.
An example of the second kind of measure is cyclomatic complexity. Even if you did not follow a computer science course there is a good explanation that is easy to follow. Basically cyclomatic complexity is the number of different paths that a method can take. It measure the decision points in the code that can lead it to do different things.
For instance, if the source code contains no control flow statements the complexity is 1, since there is only a single path through the code. If the code had one single if statement, there are two paths through the code: one when the condition on the if is true and the other when is false.
Acting On The Code Metrics
We do not think that understanding the concept is the issue, the problem is what to do with it. The documentation says that you should be concerned if the number is higher than 15 and split the method if it is higher than 30. So there is some guidance, but if you do not understand its impact and how it affects larger issues like testing and QA. You might not know whether this indicate a larger design problem that cannot be solved simply by refactoring a bit.
That is where the software architect target audience becomes more evident.
An important note is that some of these measures are only available for C#, while a version for Visual Basic .NET is under development. So if your projects are written in VB.NET you have to check carefully what is available from the documentation.
A Few Interesting Metrics
Let’s see a few interesting metrics to understand the structure of the project.
Metrics For Assemblies
The main objective of the metrics for assemblies is to let you understand which ones can be hard to maintain (concrete/stable) and which ones are of little use (abstract/instable). The first ones are assemblies whose types are used by many other assemblies, thus they can create cascade effect in case of modifications. The second ones are full of abstract types (interfaces and abstract classes).
To do that it relies on the concept of efferent coupling:
The number of types outside this assembly used by child types of this assembly. High efferent coupling indicates that the concerned assembly is dependant
…and afferent coupling:
The number of types outside this assembly that depend on types within this assembly
The ratio of efferent coupling to total coupling define instability, the closer this value is to 1 the more instable the assembly is. At the opposite the value of 0 indicates an assembly resistant to change.
Metrics For Types (Classes)
The aforementioned ciclomatic complexity is related to types.
Type rank applies the Google PageRank algorithm on the graph of types dependencies. The higher the value is the more important a type is and and should be carefully checked, because a bug could affect the whole software.
There are a couple of interesting metrics related to the inheritance of classes: number of children and depth of inheritance tree. They can be useful to detect design issues, but it is hard to have general rule. That is because there is a lot of inheritance that comes with the language and the standard library itself.
The most notable metric is the Lack of Cohesion Methods (LCOM) which is designed to find which classes respect the Single Responsibility in SOLID. A class that respect this principle is said to be cohesive.
The underlying idea behind these formulas can be stated as follow: a class is utterly cohesive if all its methods use all its instance field
We find this metric particularly interesting because it is a smart way to calculate an abstract principle. And an abstract principle can be hard to understand and apply without the necessary experience. Sadly, there are not metrics to easily detect problems with other SOLID principles, but one is already one more than we expected.
Metrics For Methods
Method rank applies the Google PageRank algorithm on the graph of types dependencies. The higher the value is the more important a type is and should be carefully checked, because a bug could affect the whole software.
IL Nesting Depth indicates the maximum number of encapsulated scopes inside the body of a method. The number is generally the one you could expect looking at the source code, but the compiler could have optimized the original code and thus changed its structure a bit.
The Default Rules
There are many default rules included in 19 categories, plus one category of samples for custom rules. These rules perform all sorts of checks:
- about the architecture of the software (e.g., Avoid partitioning the code base through many small library Assemblies)
- issues related to code smell (e.g., Avoid methods potentially poorly commented)
- the correct usage of some .NET functions (e.g., Remove calls to GC.Collect(), but if you must use it at least Don’t call GC.Collect() without calling GC.WaitForPendingFinalizers())
- …and many others
The rules also varies in their concerns. That is to say some of the rules takes care of facilitating the respect of well known design rules (e.g., rules about using the lowest visibility possible to increase encapsulation), while others deal with simpler issues like naming (e.g., you should not name random functions Dispose, it should be reserved for types that implement System.IDisposable).
They are all listed in the documentation. Both in the documentation and in Visual Studio you can find a description and how to fix the corresponding issue. The online documentation also shows how each rule is implemented.
The positive thing is that there are few false positives, the kind of rules that are always matched. They are an issue because if all code is bad, but it actually keeps working fine, maybe the code is actually right and the metric is wrong. In reality, usually things are more nuanced, you should not do certain things except when you have no other choice. Simpler tools for static analysis cannot understand that. And if they show thousands of false positive errors you might as well check the code manually.
A Few Issues
NDepend instead generally is doing good in that regard, so there few false positive. But there are a few issues. The most common one is the rule named Avoid methods with too many parameters, which invariably end up being a long list of constructors. Not all constructors needs many parameters, but when they do there is no good alternative.
Rules about avoiding the Singleton pattern at all cost or having types with too many lines of code, can be considered correct according to current best practices. However some people might disagree, and if you think there are nuances, you will have to modify the rules and put the nuances yourself.
There are also rules that measure things, statistics concerning the evolution of the project (e.g., how many issues you have solved) or certain properties of the code (e.g., most used methods).
Code Query LINQ
The rules are implemented using a language called Code Query LINQ (CQLinq). It is very similar to LINQ and thus quite easy to grasp by the average .NET programmer.
The language allows you to create rules that query:
- code metrics
- statistics about the evolution of the project (e.g., issues solves, code diff, code coverage)
- code object model (i.e., the organization of the code: the fields and methods that each class contains, the classes that each namespace contains, etc.)
- mutability of types
- basic info about source code (e.g., names of things, source code paths)
- code dependencies (i.e., which methods are called by each method, which assemblies are referenced by each project, etc.)
- quality gates
- technical debt
Let us concentrate on three things, the first of which is code coverage. The tool does not actually perform code coverage checks, but it can make available through CQLinq data generated by a third-party tool that does code coverage. The tools listed in the documentation are: NCover, JetBrains DotCover and obviously Visual Studio. Note that Visual Studio provide code coverage only with the Enterprise version.
Quality gates fundamentally combine the results of rules to produce a status for the project (pass, warn, fail). They are useful because they can inform of the high-level status of the project and larger problems that arise from the combination of many issues. For instance, if all the rules generate 10 critical issues you might want to see it instantly or throw a big red fail in front of the developer.
They can be used in the Visual Studio plugin, but in that case they can just inform the developer of a problem. They are more useful in the building process to automatically stop it or perform some action, like warning the developer responsible for a section of code or even somebody higher up in the hierarchy.
Measuring Technical Debt
Probably the most important metric is the last one: technical debt. Each rule defines something to check, but also how much time it would take to fix the underlying issue, this is the technical-debt. It also defines how much time it would be lost each year if the issue is left unfixed, this is the annual-interest. The standard rules define these values and you would have to do the same for your own custom rules.
These values can be combined to obtain an important business information: how much time it would pass before the time lost because of the issue reaches the cost of fixing it. This is called breaking-point in the documentation. For example, if an issue costs 1 day to fix it (technical debt) and cause 6 hours of wasted time each year (annual interest), it would take 4 years before the cost of fixing it reaches the time lost because of it.

There are also a few settings that you can change relative to the technical debt: they affect the hours of work and the hourly cost of a developer. Related settings are the ones involved in the SQALE method, which is a standardized way to assess the business impact of technical debt. NDepend implements only part of said method.
The SQALE Debt Ratio express the effort of solving technical debt compared to the time it would take to rewrite the code from scratch. The time it would take to rewrite the code for scratch is based on the setting called Estimated number of man-days to develop 1000 logical lines and the number or logical LOCs in the project.

For example, to solve all the issue for the project in this image it would take 14.39% of the time that it would take to rewrite the code from scratch.
It is obvious that by changing the setting about the time it takes to write 1000 lines of code, you can get a very different debt ratio. For instance, if the value of Estimated number of man-days to develop 1000 logical lines was set to 50, the project would have a debt of 5.18% and an A rating.

So it is extremely important to note that the default setting (18 days) is just an estimate. You would have to set the proper value for your business.
The default value is 18 man-days which represents an average of 55 new logical lines of code, 100% covered by unit-tests, written per day, per developer.
Note that your estimate should include the time it takes to create both the code and the corresponding unit tests to check its correct behavior.
Custom CQLinq Rules
You can use CQLinq to create custom rules. This can be done in several ways, for instance in special files or inside the source code with annotations. The annotations can also be used to target whole sections of code. You can use an annotation on each class you want to work on together and then write one rule to target all of them. You can event try the rules live and have them automatically applied for easy testing.
They are very easy to use and the autocompletion support make it as easy as writing C# code. Provided, of course, that you already have a clear of idea of what you want to do.
For example, let’s say that you like the aforementioned Avoid methods with too many parameters, but you want to exclude from the check constructors and initializers. You could modify directly the original rule, by just clicking on it and editing the CQLinq code.

In the image you can see that this rule match 11 methods.
That is probably the correct way if you are just changing a configuration parameter. In this case, the threshold for too many parameters is defined as 7 or more. So you could change it to 8 or 9. Since we want to change the meaning of the rule we opt for disabling the current one and creating a new one.
We called it Avoid methods with too many parameters unless they are constructors.
// <Name>Avoid methods with too many parameters unless they are constructors</Name>
warnif count > 0 from m in JustMyCode.Methods where
m.NbParameters >= 7 && (m.IsConstructor == false && m.SimpleName != "Init")
orderby m.NbParameters descending
select new {
m,
m.NbParameters,
Debt = m.NbParameters.Linear(7, 1, 40, 6).ToHours().ToDebt(),
// The annual interest varies linearly from interest for severity Minor for 7 parameters
// to interest for severity Critical for 40 parameters
AnnualInterest = m.NbParameters.Linear(7, Severity.Minor.AnnualInterestThreshold().Value.TotalMinutes,
40, Severity.Critical.AnnualInterestThreshold().Value.TotalMinutes).ToMinutes().ToAnnualInterest()
}
All that we have changed is on line 3: we added a further check to exclude constructors and functions with the name Init.
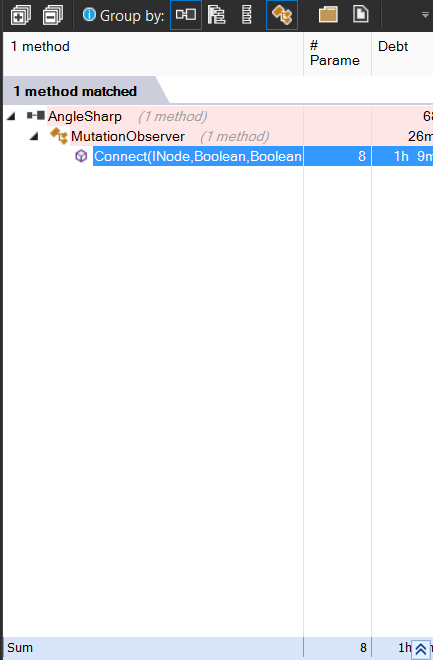
Now there is only one match.
CQLinq is powerful enough that you could make sophisticate checks. For example, at a first glance it seems that you could implement a check for something like the Law Of Demeter.
Visualizing Code
The metrics can also power useful visualization of the analyzed code.
Architectural Graphs
There are several of them related to graphs representing the structure of the code. The most used ones are probably dependency graphs, that show the relationship between assemblies. They are mostly relevant for understanding complex projects. That is because the contemporary infrastructure allows normal project (e.g., libraries) to be neatly and easily organized. For example this is a dependency graph for AngleSharp, a very successful HTML parsing library.

As you can see there are very little complications in the typical standalone library. Actually, if you try to analyze a few important C# project on GitHub you will be hard pressed to find something more complicated than this.
Of course there are a lot of complex applications out there, but it might be rare to have to deal with lot of them. At worst you are probably going to work with one big project. That is unless you are in a position to be responsible for many of such projects.
What you are going to use more frequently is the Internal Dependencies Graph, which can really help you to familiarize with how a class works.

As you can see the visualization is also interactive and can give you direct access to the information on the underlying analysis.
Dependency Structure Matrix
A Dependency Structure Matrix (DSM) is a textual representation of the same information displayed in the kind of graph that we have just seen. The two representations have different advantages:
- a graph is easier to understand, but is lighter on the details and does not scale well with many nodes and edges
- a matrix is harder to parse, but gives more data and it does it in a precise way

This (partial) matrix correspond to the first graph that we have shown in this paragraph. Context-sensitive information is available in case you need it. However the matrix is fairly simple to understand:
- the row indicates the assembly that is used
- the column indicates the assembly that is using it
- the number represents the members of the source assembly involved in the relationship
In short, the graph is useful to understand at-a-glance how things works, while the matrix is useful to detect patterns in code. If you have to do a manual analysis of the results, you are going to use the matrix. You might need to do that, for example, to understand how costly would be to replace a certain library.
A General Overview Of The Code
Another kind of visualization that NDepend can generate for you is a treemap. A treemap is a way to visualize a tree-structure by using nested rectangles. The tree represent the usual structure of a program: assemblies contain namespaces, namespaces contain classes, etc. The size of each rectangle is proportional to the LOCs of the corresponding element. A treemap can also use color to convey information.

In the HTML report, by default, this information is the percentage of code coverage of the visualized element. The alternative is cyclomatic complexity, if code coverage information is absent. In the NDepend plugin this can customized to a few different values.
This visualization is called Treemap metric view in the HTML report, but Code Metrics View in the interactive representation accessible through the plugin.
If you keep all the generated treemap images versions you can see the evolution of the code coverage and the size of each section of the code. Coupled with the information obtained with other tools, you can get a better sense of how to attack a particular issue and how the solution is developing.
For example, imagine that you are tasked with adding unit testing to an old project with zero code coverage and you want to have the most impact. If you were starting without any tool you would probably start with the most important (i.e., largest section of the code). But using the DSM you discover that a certain small namespace actually contains a good part of the foundation of the library. So you start from there.
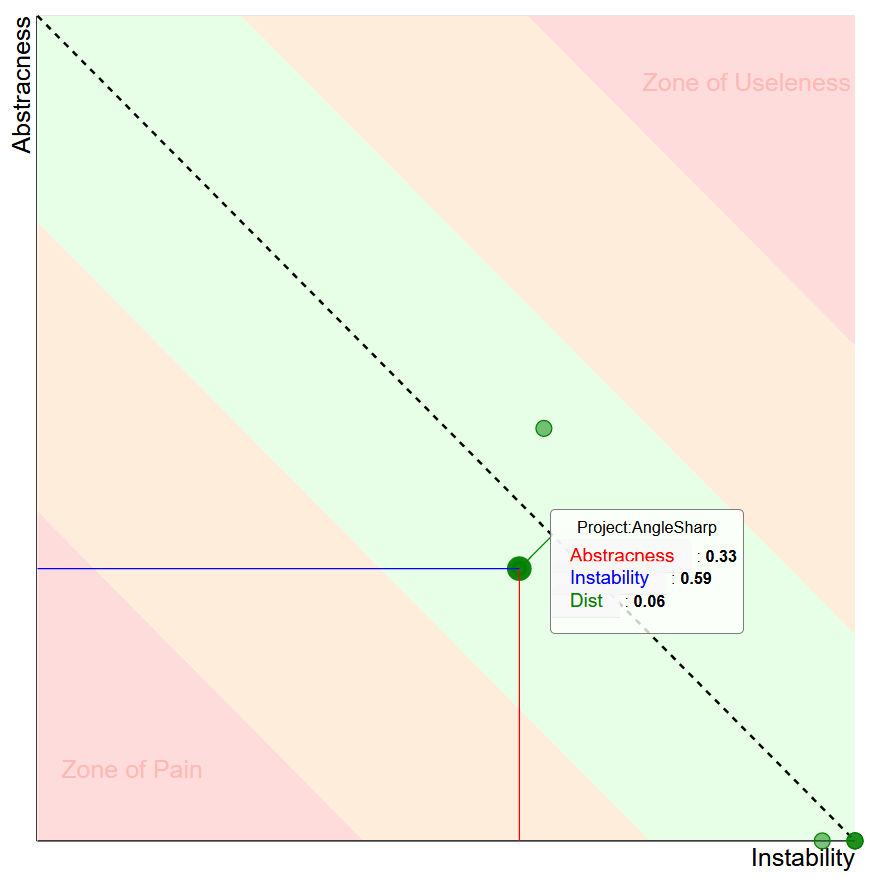 NDepend can also create a nice visualization of Abstractness vs. Instability properties, which is helpful to identify long term problems in the relationship between assemblies.
NDepend can also create a nice visualization of Abstractness vs. Instability properties, which is helpful to identify long term problems in the relationship between assemblies.
Reports
We have already mentioned the fact that NDepend can generate HTML reports. These have the advantage of being more accessible to anybody. Both because they do not require Visual Studio and also because they are simplified representations of the static analysis results.
The most important drawback is that you miss the interactive component and the connection to the source code. That is to say, usually with NDepend clicking on something might give you the chance to directly go to the corresponding source code for further analysis. You obviously cannot do that with the report.
You cannot customize it interactively, but you can use XSL styles to do it before it is generated.
Miscellany Features
There are two miscellaneous feature that are included with NDepend that can be very useful to get a grip on a project: code diff and advanced search features.
The first one is in part a legacy of the long story of NDepend, when there were not good diff tools for Visual Studio. But it is nonetheless still quite useful in the context of analyzing issues. For example, it can show the differences between different assemblies, by relying on the .NET Reflector decompiler. It can also be combined with powerful CQLinq queries to find, for example, the method changed since the last baseline code.
In a similar fashion, you can use complex search queries based on the value of rules like efferent or afferent coupling, type or method rank, etc. Basically you can leverage the code metrics to find all the code relevant to an issue or a design problem.
There is a third feature that could be very important: NDepend API. This makes possible to integrate the tool with whatever you are using, including custom software. For example, you could use the information provided by the more simple rules of NDepend to do some quick automatic refactoring.
NDepend And Your Business
There are a few tasks for which static analysis is indispensable, for example when a software architect have to review the code of an outsourced project or judge the status of an old one. You cannot easily walk through ten of thousands of lines of code manually.
More importantly, it is harder to point clearly at problems and potential solutions without a precise tool. You just cannot say that a lot of functions are really complicated, it is not easily actionable. But you can say that 53 functions have an high cyclomatic complexity, and this must be fixed, and then you can also suggest where to alter the design.
NDepend can do that, but can also do something different. If traditional static analysis tools can help you to enforce style and prevent bugs, NDepend can help you with maintaining education and simplify maintenance of software. NDepend can certainly be used to help directly a developer, but is a tool best used by whoever design software in your organization.
Note though that we said maintaining education, not actually educate developers. That is because you can simply force developer to avoid null problems, but you cannot block builds for design problems without explaining them first. You will look like a vengeful god that speak harsh judgements. More prosaically, some of your developers might not know how to avoid design problems found by NDepend. After all, that is why you need a software architect to begin with.
Using Technical Debt To Drive Business Decisions
It is obviously a bad practice to use just one metric to measure the quality of the work of someone. Steve Ballmer famously criticized IBM for trying to link KLOCs (thousands of lines of code) to value contributions to software. And he was right.
On the other hand, sometimes the benefits of having one definitive measure outweigh the drawbacks linked to that simplification. In this case, the measure can be technical debt, which is well defined by standard rules. If this measurement is used with a grain of salt and built correctly, it can be of great value.
It can be particularly useful because it can be understood by many parties, such as developers and management. In this case, the hard work is done by the creator of the rules, that must have the necessary expertise to calculate a correct technical debt and annual interest.
Depending on what you want to do, even an approximate measure can be useful. For instance, it can certainly help prioritizing the fixing of bugs to maximize business value. In other words, the breaking point can be used to calculate the ROI of fixing issues. For most small things there is really not an objective way to estimate it manually. So, as long as it is broadly correct, small problems can be solved in the optimal order to save some days of work in a year, which can lead to meaningful savings.
It is a risky measure to adopt in a somewhat adversarial relationship. For example it is probably a bad idea to link a low technical debt to a performance bonus with an outsourcing party. That is because it can try to just making the number go down, without fixing the real issues.
NDepend For Consultants
When we interviewed Erik Dietrich he said that static analysis can be helpful in analyzing open source projects. It can help limiting the problems due to the lack of documentation. You ran an analysis and can get an overview of how the code works. This can be particularly useful if you just need to patch a bug in a library, but the fix requires you to understand the inner relationships of the software.
Sometimes you are hired to analyze a codebase and write a report about it. You will have to keep writing the report by hand yourself, but the reporting features of NDepend can help you augment that report with nice and useful visualizations. Furthermore, you can synthesize your expertise in a bag of custom rules that can simplify your work. In theory, you can create a custom visualization that, in addition to your custom rules, can create a list of actionable and precise actions that your client can take.
NDepend cannot become your only static analysis tool, because it does not spot simple errors in the code. For example, there was a codebase full of declaration of a variable which was immediately followed by an initialization of said variable. NDepend cannot detect that and certainly cannot help in automatically refactoring the code.
Summary
NDepend it is a tool that can be really helpful to software architects in the course of their job. It can help in tasks such as reviewing the code of others and keeping the quality of your project high.
It can be less useful to individual developers. That is mostly because they are probably working on a few projects that they already know very well. Thus they can develop design insight by themselves. Though even in that case it might help you dealing with management, because it gives you numbers that the business can understand.
Note: A license has been given to us free of charge, however this had no influence on our opinion.

