")
In this article, we will present our COBOL parser. It is based on our Chisel methodology and our open-source library, Kolasu. The parser is commercially licensed, but we hope this article will be useful for anybody wanting to learn what a parser is for and how to use one.
If you want to know what a parser is, we will explain it.
We are going to show you an easy to understand example of the things you can build with one: a custom software to understand which external programs your code calls.
If you are looking to design your own parser, we will show you why you might want to follow our Chisel method to build one.
What is a Parser (And What is Not)
We work with parsers daily, so it is very clear to us what a parser is and what it can do. However, this might not always be the case for users. So, let’s spend a few words on this point.
Generally, a parser is software that can understand the syntax but not the semantics of some code.
Fundamentally, a parser is software that creates a model of the input source code so that data can be extracted from it.
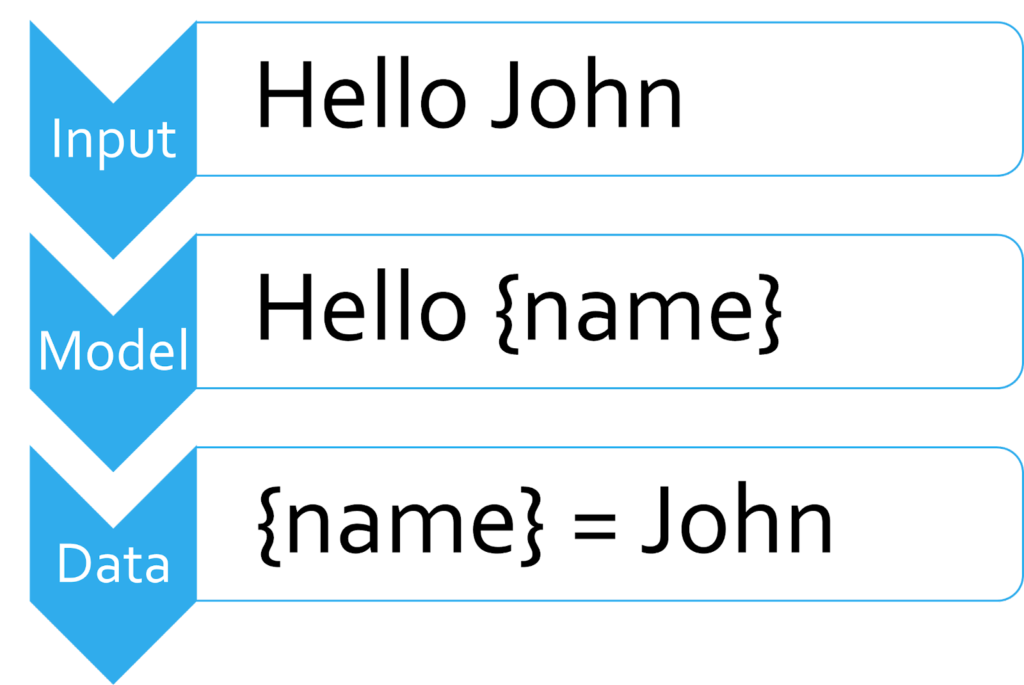
This model should be clear, useful, and easy to work with. The model that matches all these criteria is the Abstract Syntax Tree (AST). The practice of using an AST to represent code is an industry standard. Of course, how to design the AST for a particular language is open to debate.
A parser can read the code, but it cannot execute it. For example, a parser can recognize both a variable declaration and an expression.
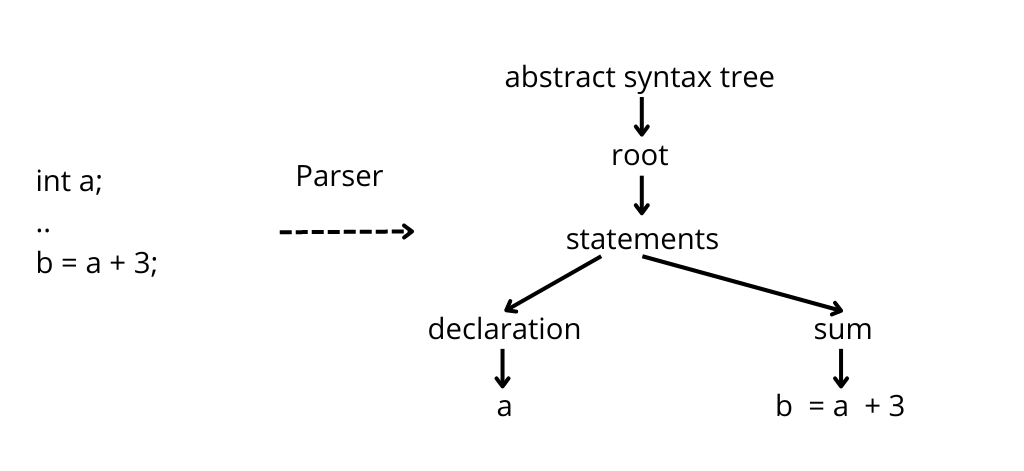
What it cannot do is link the two and understand where a variable used in an expression was declared. This feature is called symbol resolution and it is a functionality built on top of the parser.
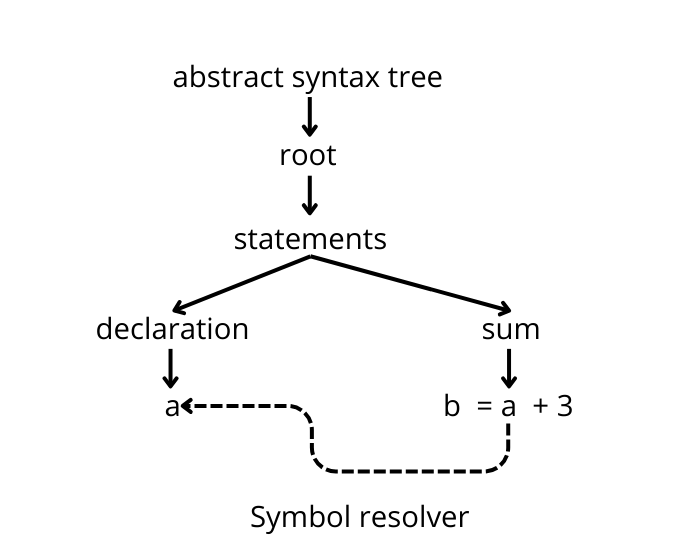
So, our COBOL parser does not implement symbol resolution functionality. That means, for example, that if you want to rename some variable you will have to build this functionality on top of the parser yourself. Or, you may hire us to implement it for you.
Play Around on the Playground
We have set up a platform to allow testing the COBOL parser online, without the need to install anything. You can see what an AST looks like. You can test our COBOL parser, or any of our other parsers for that matter, with some example files on our playground.
It is a great way to get a feel of how it works and whether it supports the features you care about. You can try it here: https://playground.strumenta.com. We are also available to test the parser on some examples you provide.
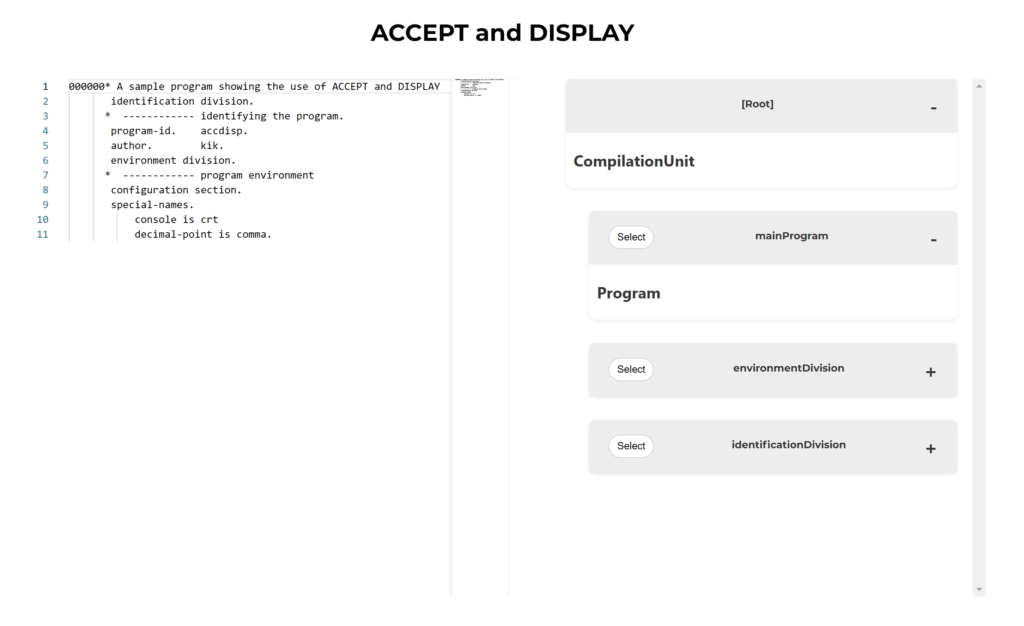
You can also read the documentation on the COBOL parser online.
Chisel Methodology
The COBOL parser is based on the Chisel methodology. It is the missing link between source code and a convenient structure for its interpretation and manipulation: an AST. When building an interpreter, transpiler, compiler, editor, static analysis tool, etc., at Strumenta we always implement the software using a pipeline. A set of reusable components that can be shared for different projects.
For example, this is a pipeline for an RPG-to-Java transpiler.
The COBOL parser and the Semantic Enricher components can be re-used for, let’s say, building an interpreter. This approach increases productivity and improves the quality of the software. For instance, any improvement to a core component for one project gets automatically shared with others.
StarLasu is the collection of runtime libraries that implement this methodology to support it in Java, Kotlin, Python, Javascript, Typescript, and C#.
At its core, StarLasu permits the definition of ASTs, on which all other functionalities are built. You can navigate and transform ASTs to do everything from reading the original values to simplifying your code. With the features provided by the library, you can do anything from analyzing a codebase to building a transpiler.
Some core features shared by our StarLasu libraries are:
- Navigation: utility methods to traverse, search, and modify the AST
- Serialization: export and print the AST as XML, as JSON, as a parse tree
- EMF and Lionweb interoperability: ASTs and their metamodel can be exported to the EMF or Lionweb formats
Interoperability with EMF and Lionweb is important because these are standard formats used in language engineering so you can mix and match different software, even from different providers.
You can read more about our methodology in a dedicated article.
A Short History of COBOL
Compared to a historical rival, like RPG, COBOL has been used by larger companies. This has little to do with the technical quality of the two languages or even their age. They were born in the same year, 1959, and while COBOL was historically considered more versatile than RPG, the difference was not that significant.
COBOL saw more use than RPG in larger companies and governments because it cost more to use, that’s it. This had to do with the business choices of the companies implementing compilers and language tools of the two languages.
COBOL was not developed by one company but by a consortium of companies.
You may ask why you should care about this history. It has one important consequence: there are many variants of COBOL; Wikipedia lists 34 of them. The IBM COBOL variant was initially the predominant one, but that changed over the years. Your codebase could now even contain multiple COBOL variants from the same vendor. The language is 65 years old, so it has seen a lot of changes. So, you need more than a COBOL parser, you need a parser for the specific variant of COBOL you are using.
Why Use a Ready-to-go Parser?
COBOL is used for large, important, complicated software and there are many versions of COBOL. So, you need a parser that has been thoroughly tested, which is documented, and gives you someone to call in case you encounter any problems.
We are experts, and we have built tons of parsers for our clients. This means that we completely understand the importance of this component, and we have a solid methodology.
And we build parsers designed for what our users need. For example, our SAS parser is geared to support data lineage, because that is what the typical user needs.
Our COBOL Parser has also been built for the needs of our clients, so it is battle-tested by our clients and us. For instance, it supports COPY statements, including the content of a COPY statement inside a file. It also handles for you some quirks of this old language. A COBOL program can alter the syntax of the language itself, with the instruction DECIMAL-POINT IS COMMA.
ENVIRONMENT DIVISION. CONFIGURATION SECTION. SPECIAL-NAMES. DECIMAL-POINT IS COMMA.
This changes the way the COBOL compiler understands decimal numbers. With this instruction, the decimal separator becomes the comma rather than the dot. Our parser can alter its behavior and automatically parse decimal numbers correctly.
Our parser was designed to support COBOL85. It now also partially supports Micro Focus Visual COBOL and Micro Focus ACUCOBOL-GT.
What Do You Need a COBOL Parser For?
Historically COBOL has been used on mainframe computers to build business applications. COBOL is rarely used to write new applications nowadays, but it still powers applications in crucial sectors like finance and government.
COBOL statements have a prose syntax, preferring words rather than symbols. This makes the language readable and self-documenting, but verbose.
Users have entire software stacks built with COBOL, to implement custom ERP software, software to manage financial transactions, etc. Users have clusters of internal applications built over the decades to handle all their needs.
The software is custom, so it is tailored to the needs of the companies. However, it has grown organically over the years, so the code is often poorly organized. It is not rare to have thousands of files without knowing which ones constitute a separate program. So one typical use case is to use a COBOL parser to perform analysis and understand which files constitute each program and how everything works together.
The language uses obsolete designs and practices. For example, programs were meant to be integrated into the specific system they were run on. Each program requires specific sections configuring the environment the program will run, data files used by the program, internal records used by the program, and so on…
For instance, the data definition and the database are effectively part of the program. This is a consequence of the system it was used in.
There Are Many Layers of Backward Compatibility
Having a long history implies that it is important to preserve backward compatibility. So, while COBOL itself is just a language, programs are often integrated with the systems they were designed for. This is simply how programs were developed back then. Given that there are many variants, even from the same vendor you might end up with a codebase mixing COBOL 85, Micro Focus Visual COBOL, and ACUCOBOL-GT, because of partial transitions done during the years. In this environment even just fixing a bug or improving a program becomes a risky endeavor, that could create a cascade of problems. Even just from a practical point of view: unless a developer has been with the company from the beginning they might be familiar with the latest variant of COBOL adopted. So, they have trouble when trying to work on older programs.
One way to handle that is to build software that automatically translates one variant of COBOL to another. This is technically a transpiler, although a relatively simple one that just needs to transform some statements into others.
When the challenges outweigh the benefits of COBOL, you want to build a full transpiler, to translate COBOL, to, for example, Java. Rewriting all the code from scratch is risky and costly. Throwing all the custom code away results in less productivity, given that the software was designed for the company. So you want to migrate the code from COBOL and do it automatically. The way to do that is with a transpiler. And for building that you first need a parser to understand the code.
How to Set Up the Parser
The only required library you need to use the parser is the cobol-parser package. For example, for Java Maven, you would write something like this.
<dependencies>
<dependency>
<groupId>com.strumenta.langmodules.cobol-parser</groupId>
<artifactId>ast</artifactId>
<version>1.1.6</version>
</dependency>
</dependencies>
This would use the cobol-parser and automatically add its dependencies, like kolasu.
You can easily adapt this for another build system like Gradle.
dependencies {
implementation "com.strumenta.langmodules.cobol-parser:ast:1.1.6"
}
That is all you need to be able to use the parser in your code just as easily as any other library. We also offer the possibility of using a fat jar with all the dependencies included.
How to Use the Parser
Using the COBOL parser requires you to indicate the file you need to parse and the location of the files that can be the target of a COPY statement.
For instance, imagine that a COBOL file contains the following section of code.
WORKING-STORAGE SECTION.
*
77 WS-NAME-ERROR-FLAG PIC 9(01) COMP VALUE 0.
77 WS-NAME PIC X(30) VALUE SPACES.
*
COPY NAMEW.
We will need to find and include the text of NAMEW into the original code, in order to be able to parse correctly the original file. The file NAMEW starts this way, so it is not a standalone COBOL file and cannot be parsed on its own.
01 NAME-WORK-AREA. 03 NAW-NAME-WORK PIC X(34). [..]
Assuming all the files are in the directory examples1 we can do that very easily.
val parsingResult = CobolKolasuParser(
copyResolverUsingDirectory(File("examples1"), "COB")
).parse(File("examples1/NAME.cob"))
We initialize the CobolKolasuParser class passing as the first argument the copyResolverUsingDirectory method that, unsurprisingly, will resolve all COPY statements by looking for files with the specified extension in the specified directory. Then we pass the location of the main file as an argument to the parse method.
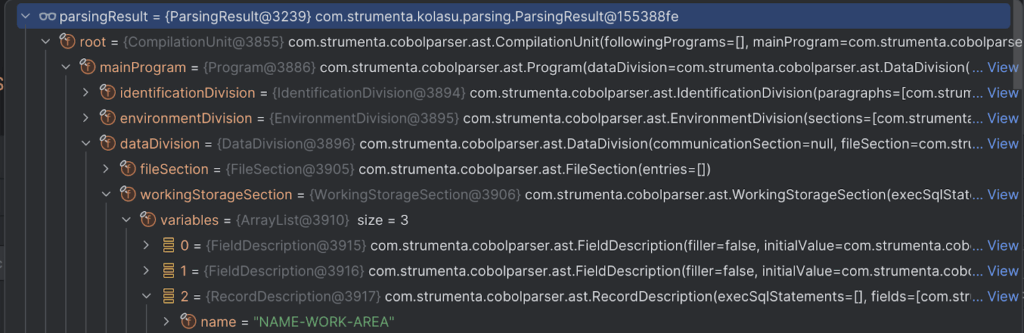
When can then check whether the parsing was successful, by looking at the property correct of parsingResult.
if(parsingResult.correct)
println("Success")
If we explore the root property of parsingResult, we can see the right RecordDescription in the AST: NAME-WORK-AREA appears as the last variable in workingStorageSection.
How to Collect All Files Needed by the Code
COBOL was designed before the practice of a neat separation between code and data. So you get things like the INPUT-OUTPUT section and FILE-CONTROL. The FILE-CONTROL paragraph names each file that will be worked on by the COBOL code. Some languages require to define variables, in COBOL you also need to declare files. One positive consequence is that you can have a neat list of the files you need to work with.
Imagine you want to move on from COBOL to a more productive language like Kotlin. You probably want also to update how you use these files.
The next step would be to transform the action of outputting data to a file to save data in the database. You can also format the files, so they can be used to present the information. So, maybe you want to transform some of these files into an HTML page that can be seen with a browser.
This is an example of how moving from an old language to a newer one often requires you more than just translating the code, you need to adapt the things surrounding the code, like data structures, to update them to the newer practices.
Whatever you plan to do with the files, you need to collect them first. All you have to do is to parse the file.
INPUT-OUTPUT SECTION. FILE-CONTROL. SELECT Student-Payment-File ASSIGN TO "STUDPAY.DAT" ORGANIZATION IS LINE SEQUENTIAL. SELECT Print-File ASSIGN TO "FEES.RPT". SELECT Student-Master-File ASSIGN TO "STUDMAST.DAT" ORGANIZATION IS INDEXED ACCESS MODE IS DYNAMIC RECORD KEY IS SM-Student-Number ALTERNATE RECORD KEY IS SM-Student-Name WITH DUPLICATES FILE STATUS IS SM-File-Status.
This will transform a section of code like the previous one into an easily accessible AST.
(parsingResult.root!!.mainProgram.environmentDivision?.sections
?.first { it is InputOutputSection } as InputOutputSection).fileControl?.paragraphs?.forEach {
println(it.fileName)
}
The previous code will output this.
Student-Payment-File Print-File Student-Master-File
Summary
We hope you have seen how easy it is to use and be productive with our COBOL parser. It has been battle-tested and is used in production by various companies.
We have distilled our knowledge about parsing into this software, to make the most productive COBOL parser out there. Built using a solid methodology, that is open to all and can be applied to build your software.
We have seen how to use the parser and to identify the external components of a program, like the files referenced in the code.
You can start playing with the parser on the Strumenta Playground.

