
The article was written in April 2022 and was updated in July 2023.
The code for this article is on GitHub: getting-started-antlr-php
PHP had always been a popular language, but for a long time it had less than a stellar reputation. Well, all of that is in the past. And what better proof that PHP is again a serious language than ANTLR support?
In this article we are going to see how to use these tools togethers to create parsers for your PHP projects. The only prerequisite is a good knowledge of PHP and its current development practices.
How ANTLR Works
In case you are not familiar with ANTLR, here is the gist: ANTLR is a parser generator tool.
This means that you write one grammar to parse your language of interest. This one grammar can be used to generate parser in every language supported by ANTLR, be it PHP or C#.
There is one ANTLR tool, an executable, that is used to generate parsers in every target language, including PHP. The application that uses the parser must include a proper runtime library for the target language.
In our case, the runtime is the ANTLR PHP runtime library. The client application does not need to include the ANTLR tool that you use to generate the parser.
You can find more information on how to set up ANTLR in our mega tutorial.
In case you use VS Code and do not want to install ANTLR in your system, you can install the excellent VS Code extension: ANTLR4 grammar syntax support that comes with its own ANTLR tool.
Keep in mind that the extension comes with its own embedded version of the ANTLR command line tool. Which is good and bad: you do not need to have ANTLR installed on your system to use it. However, the embedded version might not be the latest one released of the ANTLR4 runtime, so this might lead to incompatibilities.
For example, at the time of writing of this article the latest runtime is on version 4.13, while the extension embeds version 4.9.
Alternatively, you can configure the extension to use an external ANTLR command line tool by tweaking its settings.
Setting Up ANTLR With the VSCode Extension
If you want to set up ANTLR for the whole system, read the mega tutorial. Instead, let’s see how it is possible to configure a Visual Studio Code extension to use it exclusively.
If you want to manage options and, for instance, to disable the visitor/listener generation, you can configure it in Visual Studio Code, like you would do for any other extension option.
These are the values you should set for this project in the settings.json file (or wherever you prefer to write your settings).
{
"antlr4.generation": {
"mode": "external",
"language": "PHP",
"listeners": false,
"visitors": true,
"package": "RomanParser",
"outputDir": "Generated"
}
}
You set the mode to external to use the extension to generate the grammar for the use for the whole project. The default is to use the internal value, in which the extension generates only the grammar for internal use (e.g., to generate the nice diagrams you can see in the extension).
We also disable the generation of the listener (which is true by default) and instead enable the generation of the visitor. The difference between a visitor and a listener is in the control you get for the process of traversal of the parse tree returned by the parser. By default, both a listener and a visitor traverse the parse tree depth-first. However, a visitor allows you to change this process the way you see fit. Instead a listener cannot do that. If you need a more in-depth comparison between the two, you can read a comparison article on Listeners and Visitors.
Finally, we make sure that the parser is created inside the namespace RomanParser and the directory Generated.
Notice that in the repository we set up the mode as internal, because we are using the latest ANTLR4 runtime.
If you choose this route, remember that you will have to manually generate the parser yourself, by calling the following command.
antlr4 -Dlanguage=PHP RomanNumerals.g4 -o Generated -package RomanParser -visitor -no-listener
You need to run this command every time you change the parser.
Where PHP and ANTLR Meet
PHP is a scripting language, so you could use it in place of Bash or PowerShell scripting. Actually, if you are more a developer rather than a system administrator, it would be easier and more readable. This is why you might see Python used in a similar role. However, PHP is mostly used in web development.
This means that the most common intersection between PHP and parsing uses are:
- handling data formats, like GEDCOM;
- as the backend of a simpler scripting language, like sieve;
- or for interpreting configuration files (e.g., Terraform).
Obviously, you could also do things like building a language server for an online code analysis tool or editor.
The ease with which you can find hosting for PHP projects on the web makes the couple PHP and ANTLR work well for all situations where deployment and management concerns are a crucial factor to consider. For a developer it is quite easy to just decide to create a new project in a new language, but for a small company to add a whole new stack to maintain can be incredibly cumbersome. No more need to support also a Java or C# stack, you could run your whole web application on PHP.
The addition of ANTLR is quite valuable because you are not going to find many crossovers between parsing and PHP experts, so lowering the bar to create a parser in PHP can meaningfully increase productivity in some projects.
The one lingering issue is that parsing is used in background workloads, rather than foreground ones. You do not want to block the UI, while the parser is working. You do not want to risk spawning a lot of PHP parsing workers that could occupy your resources. Probably you also do not want to launch a parsing process from scratch each time, because that would needlessly waste startup time, which can be crucial in a web application.
These are standard web development concerns that PHP experts will be well aware of. However, parsing experts might never have thought about that so, in case you are coming from the ANTLR world to the PHP/web world, you would want to put some consideration into those aspects when designing your application.
Our PHP Example
This leaves us in a bit of a pickle. We are here to teach you how to use ANTLR in PHP, but we cannot design a proper web application. That is because then most of our code would be dedicated to boilerplate code and will be inaccessible to people that do not already know web development. So, we opted for creating a simple PHP application meant to be called from the command line. If you already know web development it will be trivial to adapt it to your web projects, if you do not, well you need to learn web development anyways.
We will make a proper PHP application, in the sense that we are going to use composer, but it will follow a simple structure.
The idea for this project is to create a parser that can find useful tidbits of data in some HTML document, identify them in some way and then pass along the modified HTML document.
So, for example, if you wanted to find dates in an HTML document you could create a parser that would find dates in the input HTML document, annotate it with all the dates and then output the new HTML document. You could also create a Roman numerals parser that will do the same thing for Roman numerals and so on… You would end up with a pipeline of parsers each doing its small part to find the information you need.
In our example we will create a Roman numeral parser that reads in input some text content and produces in output the content annotated with the Roman numerals highlighted.
An Helpful Composer
Let’s start by looking at our composer.json file to set up our application.
{
"name": "strumenta/php-roman-parser",
"minimum-stability": "dev",
"autoload": {
"psr-4": {
"antlr\\antlr4-php-runtime\\": "src/",
"RomanParser\\": [ "Generated/", "src/"]
}
},
"require": {
"antlr/antlr4-php-runtime": "^0.9.0"
}
}
The autoload section contains the setting to automatically load PHP libraries to make them available in our main code file.
The sub-section psr-4 is a standard one that is necessary to load the required libraries of any PHP application. In our case it loads the ANTLR PHP runtime, our sources and the files generated by ANTLR that we decided to put in a Generated directory.
Mind you that the ANTLR PHP Runtime seems to be frequently out-of-sync with the official tool. For example, right now the ANTLR Tool is at version 4.13.0, while the ANTLR PHP Runtime package is version 0.9.0 which corresponds to ANTLR 4.12.0. The versions should match, so you need to pay attention to them otherwise you will get an error like this one:
ANTLR Tool version 4.13.0 used for code generation does not match the current runtime version 4.12.0
We are using the psr-4 loader, but you may also want to use the classmap loader, rather than a more common namespace-based loader, if you decide to generate the parser outside a namespace.
Of course, remember to run:
composer install
The Grammar
To build a parser with ANTLR we need to design a grammar. For our example, we are going to take the grammar available in the antlr4 grammars repository and modify it for our needs.
Before looking at it, some notes on grammars. An ANTLR grammar will contain definitions both for the lexer and the proper parser. If you are unsure of how lexer and the parser works together you can read our article with the fundamentals on parsing.
The gist of it is that first the lexer looks up the single characters present in the input and groups them in tokens. Then the parser will look up the tokens and organize them according to the rules of the parser to create the final parsing tree.
You can recognize parser and lexer rules because parser rules start with a lowercase letter, while lexer rules start with an uppercase letter. By convention lexer rules are all uppercase, but this is not required.
Parsing Roman Numerals and Also Everything Else
This is just part of the complete grammar of our example, to look at the general structure.
grammar RomanNumerals; expression : words* (numeral words+)* EOF ; words : ANY+ | WS ; [..] WS : [ \r\n\t]+ ; ANY : ~[ \r\n\t] ;
We need to start with grammar and a name, in our case RomanNumerals. The name must be the same as the file in which the grammar is written, so our file must be called RomanNumerals.g4.
Our starting rule is expression. This will be one we will call to parse a whole file. It is not required that it is the first rule, but it usually is the first one by convention.
This rule says that the whole file can be parsed by a series of words and numeral. The rule numeral will parse the actual Roman numerals, but we are going to see it later. Now, it is important to look at the overall organization of the grammar. The rule will parse the whole file because it ends with the token EOF. This is a default token that is included automatically in every ANTLR parser and matches the End of File.
If a rule does not end with the EOF token it might only partially match the file, since there is nothing wrong with a parser that just parses a part of the input. However, for our case we need to parse everything, so we need to make sure that this happens.
The expression rule can match any number of words and a series of a numeral and at least one words. The quantifier * indicates a match of zero or more occurences, while + indicates a match of one or more. They are common quantifiers that you will recognize from regular expressions.
Basically, expression can match any number of numerals in the input, as long as they are separated by a words (i.e., a space or another words). We do not want a sequence of Roman numerals all smashed together.
The rule words is our catchall rule that parses anything that we do not care about: words and spaces.
Lexer Rules Are More Complicated Than They Look
The rule ANY is simple, but the way it works is complicated and deserves some explanations.
It is a lexer rule, so it works on characters rather than tokens. It matches any single character that is not a newline, tab or space character. That is because it matches a character set (identified by []) but the character set is negated (the tilde ~).
Two things are important to notice: the position of the rule ANY and the way it is different from the WS one.
The rule ANY must be the last one, because the ordering of lexer rules matters. The ordering of lexer rules is meaningful in the sense that it can affect the results.
Fundamentally this is because the lexer is less smart than the parser. It can only look at the characters in sequence. So, to solve any ambiguity it just picks the first rule that can match the input. This means that if you put the rule ANY before another rule it will match almost anything and hide all other rules, so it must be the last one.
The second thing to notice is that it matches only a single character, while the rule WS matches a character or more (the set ends with a +). Why this maddening inconsistency?
We said that the order of lexer rules matter, but to be more precise: ANTLR picks the first defined token that matches the longest input. Basically, if two tokens can match the same text, ANTLR picks the first one. However, if a token that is defined later matches more text, it picks that one.
Since the ANY can match almost any character it would hide most of the characters used in roman numerals. You can clearly see that when looking at the lexer rules for Roman numerals.
M : 'M'; CD : 'CD'; D : 'D' ; CM : 'CM'; C : 'C'; CC : 'CC'; CCC : 'CCC' ; XL : 'XL' ; L : 'L' ; XC : 'XC' ; X : 'X' ; XX : 'XX' ; XXX : 'XXX' ; IV : 'IV' ; V : 'V' ; IX : 'IX' ; I : 'I' ; II : 'II' ; III : 'III' ; WS : [ \r\n\t]+ ; ANY : ~[ \r\n\t] ;
Understanding Roman Numerals
Parsing Roman numerals is quite simple, provided that you understand how they work. So, let’s start with that. They are different from the Arabic numerals you are familiar with in that they are not positional. A Roman digit value does not depend on its position, but it has an absolute value.
In most cases the value is added to the overall number, but in some cases it is subtracted from it. This depends on the relative position of the digit: they are usually in descending order, if two digits are reversed and in ascending order then the one of lower value is subtracted from the other.
Another oddity is that digits do not cover all the numbers, but only groups of three that are combined to represent all of them. For example, to represent 1 to 10, you have only specific numerals for 1, 5 and 10: they are I, V, X respectively. They are combined to represent all the intermediate numbers.
Numbers from one to three are represented with one to three I units:
- I
- II
- III
The number four is represented by combining I and V, but reversing them, so to subtract one from 5:
- IV
The numbers 5 to 8 are represented by combining V and I
- V
- VI
- VII
- VIII
And finally nine is represented by combining I and X, in the same way used for the number 4:
- IX
- X
The same rules apply true for numbers 10 to 100, that use digits X, L and C, to represent 10, 50 and 100. For numbers 100 to 1000, instead we use C, D and M, to represent 100, 500 and 1000.
There are some extensions to represent large numbers, like a  ̄ (horizontal line) on top of a number to multiply it by 1000. Although these were not standard. There were also rules to indicate fractions. We are going to ignore all of that.
Parsing Roman Numerals
We can finally look at the rules for parsing numerals themselves.
numeral : thous_part hundreds | thous_part | hundreds ; thous_part : thous_part M | M ; hundreds : hun_part tens | hun_part | tens ; hun_part : CM | CD | D hun_rep | D | hun_rep ; hun_rep : C | CC | CCC ; tens : tens_part ones | tens_part | ones ; tens_part : XC | XL | L tens_rep | L | tens_rep ; tens_rep : X | XX | XXX ; ones : ones_rep | IV | V ones_rep | V | IX ; ones_rep : I | II | III ;
Now that you know how Roman numerals work, the overall functioning of the grammar should be quite clear and simple.
For instance, looking at the rules for dealing with hundreds.
The first rule, hundreds handle the structure: we consider the case for both an hundreds and a tens part (e.g. DX), one where there is only a hundreds part (e.g. D) and one where there are no hundreds, but only tens (e.g. X).
Then the pair hun_part and hun_rep deal with parsing the basic cases, as we explained in the previous section: parsing single digits (e.g. C) or all the combinations thereof (e.g., CM).
The Main Program
The main source file, excluding all the boilerplate, is fairly short.
$input = InputStream::fromPath($argv[1]);
$lexer = new RomanNumeralsLexer($input);
$tokens = new CommonTokenStream($lexer);
$parser = new RomanNumeralsParser($tokens);
$errlis = new LogErrorListener();
$parser->addErrorListener($errlis);
$tree = $parser->expression();
$visitor = new RomanNumeralsTranslateVisitor();
$visitor->visit($tree);
file_put_contents("./output/output.html", $visitor->text);
We read the input file, we parse it, we visit the parse tree and then we output the results.
The first four lines are standard ANTLR code, that you will grow accustomed to. You start by creating an InputStream from a file or a string. We do this on line 1. This will allow ANTLR to handle the source in a way suited to its needs: to move forward or backward, to keep track of the positions of the characters, etc.
We then feed the input to the lexer and obtain the tokens created by the lexer on lines 2-3. We finally feed the tokens to the parser, so it can do its magic.
In the subsequent lines we create a LogErrorListener and add it to the parser, so that the parser can use it to report any parsing error to us. We could also add it to the lexer, if we so wished.
The LogErrorListener is a custom ErrorListener class that we created. Long-time users of ANTLR will wonder why we did not use one of the standard ConsoleErrorListener or DiagnosticErrorListener classes that come with ANTLR. These are available in the PHP runtime, but given the PHP run environment we believe that most users will want to use a custom error listener in order to log all errors into their usual logging pipeline. This is because often you have no precise control over where or how your PHP script will be run on a third-party platform.
On line 9 this is where the parsing actually takes place. We ask the parser to find a match for an expression rule. As we said, the expression rule has no special meaning. We could as easily ask for a words match. The parser will find any match for the rule and return the corresponding parse tree.
The parse tree is nothing else than a tree representing the original input with the structure defined in our grammar. In our case we will get a root node of type expression with a long sequence of words and numeral nodes. Each of these children will contain its own children and so on…
A notice about something that should not surprise you but it might: asking to parse something it is not idempotent. Calling $parser->expression() will advance the input, so calling it twice will not give the same result. You can reset the input, if you need it.
On lines 11-12 we setup our visitor and then feed the parse tree to our visitor. The visitor will traverse the parse tree and annotate it.
Hide Your Errors
Let’s see the LogErrorListener.
<?php
namespace RomanParser;
use Antlr\Antlr4\Runtime\Error\Exceptions\RecognitionException;
use Antlr\Antlr4\Runtime\Recognizer;
use Antlr\Antlr4\Runtime\Error\Listeners\BaseErrorListener;
final class LogErrorListener extends BaseErrorListener
{
public function __construct()
{
$this->errors = array();
}
public function syntaxError(
Recognizer $recognizer,
?object $offendingSymbol,
int $line,
int $charPositionInLine,
string $msg,
?RecognitionException $e
) : void {
$this->errors[] = "Error at {$line}:{$charPositionInLine} {$msg}";
}
}
Our error listener will be notified of any error and the syntaxError method will be called. We will receive errors and then we will do absolutely nothing with it, because we want to hide them to avoid embarrassment. In this example we store them in an array, that we will use for testing later. But the real takeaway is the signature of the syntaxError method. You can use it to take advantage of your logging facilities.
The other parameters of the method are less important than the error message ($msg) or the position of the error ($line, $charPositionInLine). The argument $offendingSymbol will contain information about the token generating the error, while $recognizer will be the parser or lexer that found the error.
Translating Roman Numerals
Now we can actually see the visitor that will transform our Roman numerals in Arabic numbers.
class RomanNumeralsTranslateVisitor extends RomanNumeralsBaseVisitor {
public function __construct() {
$this->text = "";
}
public function visitWords(WordsContext $context) : void {
$this->text .= $context->getText();
}
We want to use a string ($text) to store all the text the input plus the annotations we are going to add. This way at the end of the visitor we can simply take the string and use it for our output.
public function visitNumeral(NumeralContext $context) : void {
$this->value = 0;
$this->visitChildren($context);
$this->text .= "<abbr title='$this->value}'>{$context->getText()}</abbr>";
}
public function visitThous_part(Thous_partContext $context) : void {
$this->value += 1000;
$this->visitChildren($context);
}
public function visitHun_part(Hun_partContext $context) : void {
if($context->CD() != null )
$this->value += 400;
if($context->CM() != null )
$this->value += 900;
if($context->D() != null )
$this->value += 500;
if ($context->hun_rep())
$this->visitHun_rep($context->hun_rep());
}
[..]
We are going to see only parts of the class because once you get the hang of it, the mechanism repeats itself.
Once visitNumeral is called the process of conversion begins. A visitor method accepts a *Context object corresponding to the type of the node that the method is designed for. In the case of visitNumeral is NumeralContext object, for visitThous_part is a Thous_partContext, etc.
In this method we reset the current value to 0, visit the children nodes and then collect the result to output the corresponding value.
The method visitChildren is a standard method available in ANTLR visitors that will traverse the tree and call the corresponding visit methods. We are also using the standard getText on a context object that will return the input text for the node. To create the final output we wrap the original text in an abbr tag, with the corresponding value in Arabic digits. This is an improper use of the tag abbr, but it works for our use case and avoids the need for JavaScript, so it is good enough for an example.
In visitThous_part and visitHun_part we add the values for the terminal nodes, like M, and visit the remaining children to add the remaining value. And that is pretty much it.
Notice that we are missing a few methods like visitHundreds or visitExpression. We can do that because our visitor inherits from RomanNumeralsBaseVisitor, which contains a basic implementation of a visitor in which all methods simply visit the children nodes. This allows us to skip the need to define the methods that do not really do anything except going deeper into the tree. The base class is automatically generated by ANTLR when you choose to generate the visitor.
The Results
Now that everything is clear, we can finally see the results.
You may want to update the autoload class first, though, with:
composer dump-autoload -o
Once you do that you can run the PHP script:
php src/index.php example_data/index.html
The file index.html is an example file in our repository. You can see the result in the output directory. It should look somethings like this:

Astute observers will have noticed a small problem. If your input contains English language, you will have a lot of false positives, because the number 1 in Roman numerals and the pronoun I use the same character. Obviously this is all English fault, since Roman numerals existed before English. The solution is therefore to abandon the use of English.
However, this might be a slight issue in a real-world case.
This is actually a nice chance to talk about what to do with broken or erroneous input. In our example the input is not actually broken, but it is rather our format that has a problem. This is called a semantic error: the input is syntactically correct, but its meaning is wrong. It follows the rules of our grammar, but the use does not make sense in the overall context.
A common example is using a variable in an expression, without defining the variable anywhere. The compiler cannot know what the variable actually means.
In user-generated input from the web, both syntax and semantic errors are a common occurrence. The HTML parser in your browser will deal with a lot of broken HTML, so it is reasonable to assume that many parsers that you will build in PHP will have to handle similar problems, too.
This is a problematic requirement, because a parser expects correct input. Although ANTLR is actually better than most, since it can deal with minor typos and slight errors in the input.
The reality is that there is not a definitive solution. The right approach will vary on a case-by-case basis. For example, if you were using this parser to record numbers for a search engine, you might simply ignore every result where there is only the numeral I. That is because it would probably be the pronoun rather than the Roman numeral.
In other cases, you might simply disable the translation at the beginning of a sentence, with something like this.
public function visitWords(WordsContext $context) : void {
// we disable the translation after a full stop
// the sentence is starting and it is more likely to find the pronoun I
if($context->getText() == '.') {
$this->active = false;
} else if($context->getText() != ' ' && $this->active == false) {
$this->active = true;
}
$this->text .= $context->getText();
}
The important point about this is that semantic errors are not a concern of the parser. You should not try to solve them in the parser, but in later code. The job of the parser should only be to correctly capture the syntax of your format. This is the right approach because the parser simply does not have the right contextual information to make a correct decision about semantics.
Why Testing Your Code
It is time to test our code. Testing is important for every software, but it is absolutely crucial for a parser. That is because a parser is not used standalone, it is the foundation of other software. A bug in the parser might propagate to a later stage and this will make it much harder to find it and solve it. If you have ever had the luck of finding a bug in a compiler you know how that feels.
You need to test your parser, you owe it to your users and you need to do it for your own sanity.
We are going to use PHPUnit for testing our code. You can install it with composer.
composer require --dev phpunit/phpunit
Then we need to create a folder tests in which to put our testing code.
Let’s Think About What We Need to Test
We are now ready to test our code, but we need to think about what we need to test. We obviously need to test that the parser can actually parse all kinds of correct input. Specifically we need to test both that the main rule can deal with anything we throw at it and that specific rules work as expected.
We also need to check that the parser reacts as expected to errors. At minimum we need the parser to detect the syntax error. You may also want to test that the parser generates some kind of additional appropriate response for your use case. This depends on what you need. For example, you may want the parser to automatically correct common minor typos.
In this particular case we also want to check something else, that the parser can handle an input without any Roman numeral. Technically, it is always the same case of checking that the main rule works as expected, only for the special case of no Roman numeral. However, semantically this is different, so we want to make sure that we handle this correctly.
That is because, in our experience, it is easy to mess up dealing with corner cases and unexpected input. We are building a parser for Roman numerals, so it is easy to think there will always be Roman numerals. But what if this does not happen? We do not want our parser to just blow up in despair, so we need to check for that.
Of course, we also need to check that the parser does detect and fail gracefully in case of errors.
In a real-world scenario, in addition to these basic tests, we would also gather a great number of representative examples and tests that the parser works on real code. For many enterprise languages you can find standard test suites that can provide a great collection to use for this scope.
In summary, we need to perform tests to check that:
- the main rule parses correct input
- the individual rules works correctly
- any corner case works as expected
- our parser detect and handle errors
- our parser can handle a representative sample of examples files
Testing Correct Input
Our first test class includes tests for the parser itself: RomanParserTest.php.
use PHPUnit\Framework\TestCase;
final class RomanParserTest extends TestCase
{
private function setupParser(string $text): RomanNumeralsParser
{
$input = InputStream::fromString($text);
$lexer = new RomanNumeralsLexer($input);
$tokens = new CommonTokenStream($lexer);
$parser = new RomanNumeralsParser($tokens);
return $parser;
}
public function testCanParseRomanNumeralWithoutErrors(): void
{
$parser = $this->setupParser("XII");
$parser->numeral();
$this->assertEquals(
0,
$parser->getNumberOfSyntaxErrors()
);
}
We create a setupParser method to contain all the boilerplate code to setup the parser; this is a typical pattern.
We use this method to test that the parser can parse a Roman numeral. We check that the parser did not find any syntax errors, by looking at the value returned by the standard method getNumberOfSyntaxErrors.
Checking that the main rule can parse a correct input is one of the four kinds of tests that we want to make. Let’s see another one.
Testing Individual Rules
We are going to test a few individual rules.
public function testCanParseThousPart(): void
{
$parser = $this->setupParser("MM");
$parser->thous_part();
$this->assertEquals(
0,
$parser->getNumberOfSyntaxErrors()
);
}
public function testCanParseHundreds(): void
{
$parser = $this->setupParser("X");
$parser->hundreds();
$this->assertEquals(
0,
$parser->getNumberOfSyntaxErrors()
);
}
As you can see, there is nothing surprising about these tests. You just need to remember to write them.
public function testDoesNotThrowErrorIfItDoesNotFindAnyRomanNumeral(): void
{
$parser = $this->setupParser("There is nothing Roman here.");
$parser->expression();
$this->assertEquals(
0,
$parser->getNumberOfSyntaxErrors()
);
}
Also checking for the special case of no Roman numeral is as trivial as it sounds.
It Is Not a Bug If We Know It Is Wrong
All that remains is testing that errors are correctly caught by our parsers.
public function testCanFindErrorsInMalformedNumeral(): void
{
$parser = $this->setupParser("Look at CCM, it is clearly a mistake");
$errlis = new LogErrorListener();
$parser->addErrorListener($errlis);
$parser->expression();
$this->assertEquals(
1,
count($errlis->errors)
);
$this->assertEquals(
"Error at 1:10 extraneous input 'M' expecting {WS, ANY}",
$errlis->errors[0]
);
}
public function testHundredsCannotParseThousands(): void
{
$parser = $this->setupParser("M");
$errlis = new LogErrorListener();
$parser->addErrorListener($errlis);
$parser->hundreds();
$this->assertEquals(
1,
count($errlis->errors)
);
$this->assertEquals(
"Error at 1:0 mismatched input 'M' expecting {'CD', 'D', 'CM', 'C', 'CC', 'CCC', 'XL', 'L', 'XC', 'X', 'XX', 'XXX', 'IV', 'V', 'IX', 'I', 'II', 'III'}",
$errlis->errors[0]
);
}
We are actually checking two kinds of errors: a Roman numeral with the wrong syntax and an attempt to parse a correct numeral with the wrong rule.
This second check might seem superfluous since the users of the parser mostly use one main rule rather than picking a rule. However, this ensures that we wrote a rule correctly.
That is useful because the user will perform some actions depending on the node of the parse tree, so if the parsers assign the wrong kind of node to an input it is going to cause trouble.
Testing The Visitor
All that remains is testing the visitor.
We create a new file RomanVisitorTest.php to contain the tests for that. The visitor effectively represents the user code, i.e., the code that the user of the parser will create. Therefore there is not a standard set of tests to make. It all depends on the specific case.
final class RomanVisitorTest extends TestCase
{
private function setupVisitor(string $text): RomanNumeralsTranslateVisitor
{
$input = InputStream::fromString($text);
$lexer = new RomanNumeralsLexer($input);
$tokens = new CommonTokenStream($lexer);
$parser = new RomanNumeralsParser($tokens);
$tree = $parser->expression();
$visitor = new RomanNumeralsTranslateVisitor();
$visitor->visit($tree);
return $visitor;
}
public function testCanCalculateXii(): void
{
$visitor = $this->setupVisitor("XII");
$this->assertEquals(
12,
$visitor->value,
);
}
[..]
public function testCanTranslateMmcdii(): void
{
$visitor = $this->setupVisitor("MMCDII");
$this->assertEquals(
"<abbr title=\"2402\">MMCDII</abbr>",
$visitor->text,
);
}
}
In our example, we just need to test that the value is translated correctly and that the output of the translation is output in the way we expect.
Now that we have written all the tests we can check that they pass.
./vendor/bin/phpunit --testdox tests
The option --testdox transforms the name of each method into a readable name in the terminal.
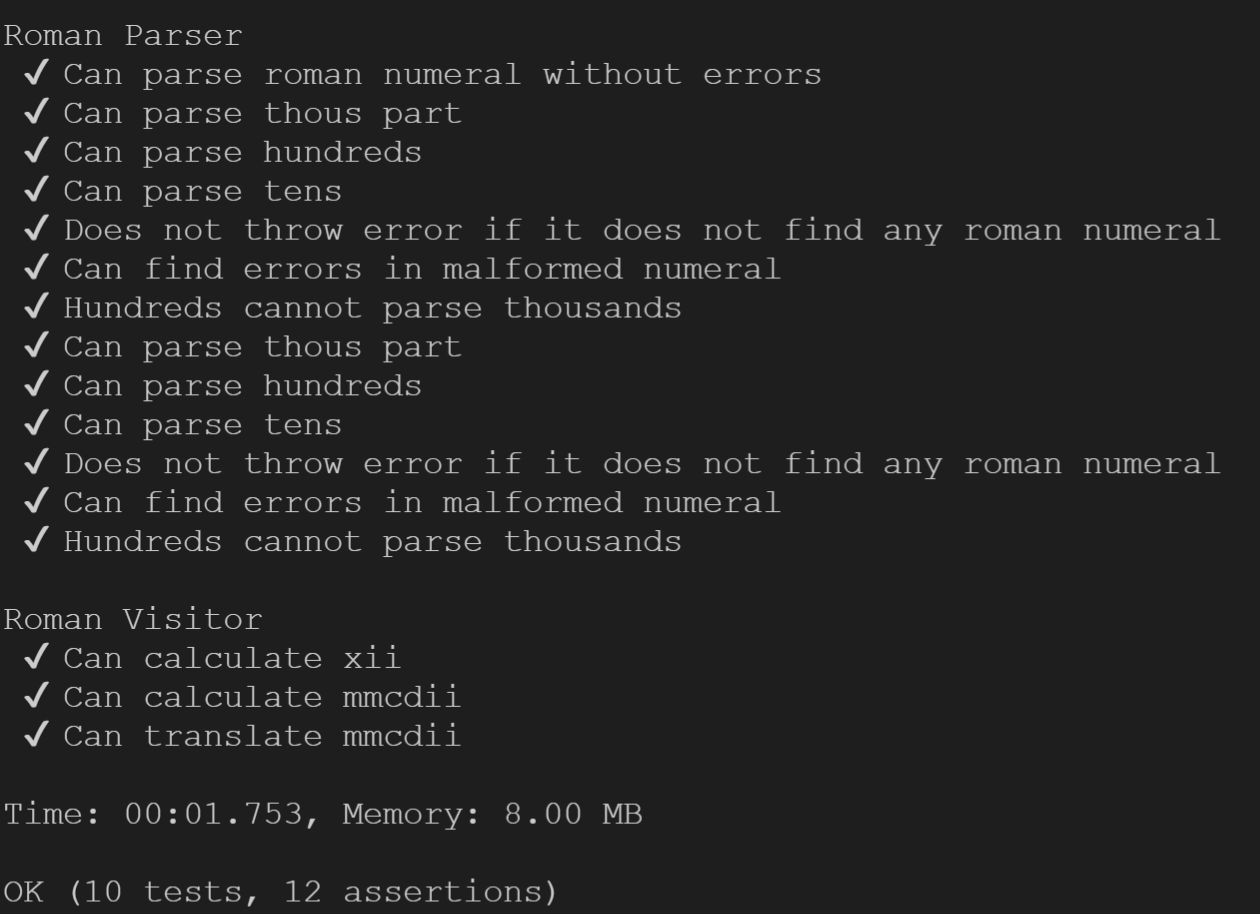
There are a few more tests in the repository. They are very similar to the one we have seen, so you can look them up on your own.
Summary
We have seen how to use ANTLR in PHP. And we have shown you how to write ANTLR parsers: from designing the grammar to organize your testing regime for a parser. We have also talked about a few caveats and tips specifically for PHP/web software that we hope could be helpful.
You can get the code for this article on GitHub: getting-started-antlr-php
If you need a more detailed explanation of all that ANTLR has to offer you can read our ANTLR Mega Tutorial. If you want to understand more about parsing in general, you can read the Guide to Parsing Algorithms and Terminology. If you are interested in a more specific guide on designing the grammar you could take a look at EBNF: How to Describe the Grammar of a Language.
Read more:
If you want to understand how to use ANTLR you can read our article The ANTLR Mega Tutorial.
Do you like to discover more about Language Engineering?
We have a very interesting newsletter, we share all our knowledge, tips and everything useful and interesting about Language Engineering.
You can subscribe here.

")