")
One of the most productive features of ANTLR is the support for easily processing the result of parsing. In this article, we are going to talk about the two ways to handle the result of parsing: listeners and visitors. We are going to see how they differ and what are the best use cases for each of them.
The examples in this article use Java. If you are still evaluating which tool to build your parser with, our guide on parsing in Java compares ANTLR with the other parser libraries and generators available on the platform.
Our Example Grammar
In this article, we are going to use this simple grammar as the basis of our examples.
grammar cookie;
cookie
: av_pairs*
;
name
: attr
;
av_pairs
: av_pair (';' av_pair)*
;
av_pair
: attr ('=' value)?
;
attr
: token
;
value
: word
;
word
: token
| quoted_string
;
token
: TOKEN
;
quoted_string
: STRING
;
STRING
: '"' (~ ('"' | '\n'))* '"'
;
TOKEN
: ('0' .. '9' | 'a' .. 'z' | 'A' .. 'Z' | '-' | ' ' | '/' | '_' | ':' | ',')+
;
DIGIT
: '0' .. '9'
;
WS
: [\t\r\n] -> skip
;
As we can see, this grammar parses a cookie that a browser could create.
Parsing Gets You a Parse Tree
The first point is understanding why we need a listener or a visitor. When you successfully parse something, you get a parse tree that represents its content. A tree is a common data structure that starts with a root node that can have multiple children. The root node has no parent node, while all other nodes have one and only one parent node.
Let’s start with an example cookie.
sessionToken=abc123; Expires=Wed, 09 Jun 2021 10:18:14 GMT
If we parse this example with our parser, we obtain the following parse tree.

This data structure is ideal because it is simple but also flexible enough to handle parsing any content. It is simple because a node can only have one parent, so you can easily traverse the tree without getting lost. It is also flexible: it can represent any kind of syntactic structure, like an addition, a series of operations, a list of strings, etc.
Traversing a Tree
In fact, it is easy to traverse any tree yourself:
- you start with the root node as your parent node
- if this node has no children, you go back to your parent node
- otherwise, you pick the first child node that you have not yet visited
- now, this node is your parent node and you repeat the cycle
This is called a depth-first search because you go lower before going sideways. In other words, you visit the children nodes before visiting the sibling nodes. The alternative approach would be a breadth-first search, which is less common and it is not really used in parsing.
This is a graphical representation of this process.
In this example you would start a depth-first search in this way:
- you start with the
cookieroot node - you visit the first child node that you have not yet visited, so
av_pairs(in this case, it is also the only first child node) av_pairsis now your parent node- so, you visit the
av_pairon the left - this
av_pairis now your parent node - so, you visit the
attrnode attris your parent node- you visit the
tokennode - the
tokennode corresponds to the valuesessionToken which has no children, so we go back to the parent node - …
The process is easy to understand and apply to any tree. It is so easy that you could do it yourself but, apart from some exceptional cases, you are not going to do that, because there are better ways to do it.
Similarities Between Listeners and Visitors
These better ways are listeners and visitors. ANTLR can generate a visitor or a listener for you. There are similarities and differences between them, that makes both good tools, but best suited for different situations.
Let’s start with the similarities:
- they both adopt a depth-first algorithm
- they are productivity boost that provide an easy and standard way to process a parse tree
The second point is important because by providing a standard way to access the tree, you do not have to come up with your own strategy. This facilitates the reusability of the grammar with different programs, even in different languages.
In fact, traditionally, people have put actions directly into the grammar because it was the easiest way to access the parse tree. This made the parser execute some code whenever it matched a specific parser rule. This had the drawback of tying a grammar to a code in a specific programming language and not being standardized. For example, somebody might execute code in a child node, while somebody else might prefer to execute similar code in the parent node.
Why You Should Use Them
The creation of listener and visitor leaves the grammar in pure ANTLR code. That means that you can use the same grammar to solve different problems. You can use the same grammar but then use different listeners and visitors to solve different problems. You can even write listeners and visitors in different languages.
This is one of the smart little things that end up saving you a lot of time. You are not force to use the, but they are so easy to use that you will use them unless you need to do something special. This means that most people use them and thus you have a standard way to work with parsing tree that you and everybody else understand how to use.
Of course they are not magic: they save you time, but you still need to do some work. They provide standard ways to execute code when there is a certain node in the parse tree. However, you need to write the code that will be actually executed.
To take our example, both a listener and a visitor allow you to easily execute some code when the parse tree contains an attr node, but you have to write that code that is going to be executed.
Differences Between Listeners and Visitors
We have seen the similarities between listeners and visitors, now let’s see the differences.
The main difference is that with a listener, you cannot govern the process of traversing the tree. Your functions are just called when the walker of the tree meets a node of the corresponding type.
With the visitor, you can change how the tree is traversed; you can return values from each visitor function and even stop the visitor together.
You want to use the listener when you do not need to change the structure of the parse tree to accomplish your goals. This means that you want to use it when your output can be generated without altering the structure of the parse tree.
Instead you want to use a visitor when you need to return results from each node or you need to gather information from several nodes.
Using Examples to Compare Them
Let’s see a few examples to clarify.
Suppose you want to convert the cookie into a JSON object. You can do this with a listener because it is easy to convert an av_pair in a field of a json object. Taking our previous example:
sessionToken=abc123; Expires=Wed, 09 Jun 2021 10:18:14 GMT
You can easily transform the av_pair composed by attr sessionToken and value abc123 in a json field like:
“sessionToken”: “abc123”.
The structure of the JSON output is compatible with the original parse tree, so you can use a listener.
Suppose instead that you need to create one custom Cookie object out of your input, for your program. For example, something like the following.
Cookie(
Expiration: LocalDateTime
Secure: Boolean
SessionId: int
)
In such cases you would need a visitor, because the output of your parsing is an object with a specific structure.
Another common example in which you want to use visitor is with code generation.
For instance, if you are creating a skeleton class from a diagram.
When generating code, the information that is needed to create new source code may be spread around many parts. So, you need a visitor to collect all the information.
Creating a Listener
Now that what you should do is clear, let’s see how you should do it.
You can generate a listener using the standard ANTLR tool.
antlr4 cookie.g4 -listener
This will generate a parser and listener in Java. Of course, you can use the standard option to generate these classes in another language. It should also be noted that ANTLR generates a listener by default, so the previous command is equivalent to this one.
antlr4 cookie.g4
You have to explicitly use the option -no-listener to not generate a listener.
When you ask ANTLR to create a listener, it will generate two listener files.
The Listener Classes
The first is an interface CookieListener, that would start in this way.
public interface CookieListener extends ParseTreeListener {
/**
* Enter a parse tree produced by {@link CookieParser#cookie}.
* @param ctx the parse tree
*/
void enterCookie(CookieParser.CookieContext ctx);
/**
* Exit a parse tree produced by {@link CookieParser#cookie}.
* @param ctx the parse tree
*/
void exitCookie(CookieParser.CookieContext ctx);
/**
* Enter a parse tree produced by {@link CookieParser#name}.
* @param ctx the parse tree
*/
[..]
This is an interface that defines the methods necessary to implement a standard listener for the cookie parser. The other methods are omitted for brevity, but there are a pair of enter/exit methods for each parser rule.
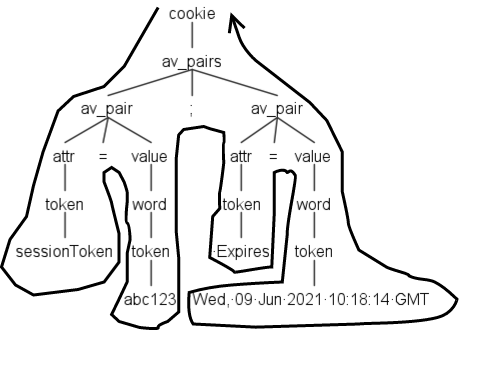
This is the first important thing to note: a listener includes an enter and exit methods that will be fired when the listener enter and exit a node respectively. These methods will accept as argument the same *Context object. For example, enterCookie and exitCookie both accepts a CookieContext object. This object contains all the data of the corresponding note, like the children av_pairs.
In the following image you can see an example of how the enter_Av_pairs() method will be fired when the listener enters the node. The corresponding exitAv_pairs() will be fired at the exit of the same node, after all the children of av_pairs have been visited.

Since CookieListener is just an interface, this would require you a lot of boilerplate code to implement it. Luckily the other generated file comes to the rescue: CookieBaseListener.
public class CookieBaseListener implements CookieListener {
/**
* {@inheritDoc}
*
* <p>The default implementation does nothing.</p>
*/
@Override public void enterCookie(CookieParser.CookieContext ctx) { }
/**
* {@inheritDoc}
*
* <p>The default implementation does nothing.</p>
*/
@Override public void exitCookie(CookieParser.CookieContext ctx) { }
[..]
This file implements a listener with all the methods that do nothing. All that is left to you is to create a derived class which contains the method that you want to override.
Implementing a Listener
For example, we implement a TalkingListener that simply prints the name of the current method and text of the node visited, like in this following excerpt:
public class TalkingListener extends CookieBaseListener implements ParseTreeListener
{
@Override
public void enterCookie(com.strumenta.examples.ListenerVisitor.CookieParser.CookieContext ctx)
{
System.out.println("enterCookie: " + ctx.getText());
}
@Override
public void exitCookie(com.strumenta.examples.ListenerVisitor.CookieParser.CookieContext ctx)
{
System.out.println("exitCookie: " + ctx.getText());
}
[..]
The class continues implementing every method, so when executed it prints something like this.
enterCookie: sessionToken=abc123; Expires=Wed, 09 Jun 2021 10:18:14 GMT enterAv_pairs: sessionToken=abc123; Expires=Wed, 09 Jun 2021 10:18:14 GMT enterAv_pair: sessionToken=abc123 enterAttr: sessionToken enterToken: sessionToken exitToken: sessionToken exitAttr: sessionToken enterValue: abc123 enterWord: abc123 enterToken: abc123 exitToken: abc123 exitWord: abc123 exitValue: abc123 exitAv_pair: sessionToken=abc123 enterAv_pair: Expires=Wed, 09 Jun 2021 10:18:14 GMT enterAttr: Expires enterToken: Expires exitToken: Expires exitAttr: Expires enterValue: Wed, 09 Jun 2021 10:18:14 GMT enterWord: Wed, 09 Jun 2021 10:18:14 GMT enterToken: Wed, 09 Jun 2021 10:18:14 GMT exitToken: Wed, 09 Jun 2021 10:18:14 GMT exitWord: Wed, 09 Jun 2021 10:18:14 GMT exitValue: Wed, 09 Jun 2021 10:18:14 GMT exitAv_pair: Expires=Wed, 09 Jun 2021 10:18:14 GMT exitAv_pairs: sessionToken=abc123; Expires=Wed, 09 Jun 2021 10:18:14 GMT exitCookie: sessionToken=abc123; Expires=Wed, 09 Jun 2021 10:18:14 GMT
A Listener interface also includes a few generic methods that will always be included whatever grammar you are using.
/**
* {@inheritDoc}
*
* <p>The default implementation does nothing.</p>
*/
@Override public void enterEveryRule(ParserRuleContext ctx) { }
/**
* {@inheritDoc}
*
* <p>The default implementation does nothing.</p>
*/
@Override public void exitEveryRule(ParserRuleContext ctx) { }
/**
* {@inheritDoc}
*
* <p>The default implementation does nothing.</p>
*/
@Override public void visitTerminal(TerminalNode node) { }
/**
* {@inheritDoc}
*
* <p>The default implementation does nothing.</p>
*/
@Override public void visitErrorNode(ErrorNode node) { }
These are methods like enterEveryRule or visitTerminal. The first one is called at the entry of every node, while the second one is called when a terminal node (i.e., a Token) is found.
We keep talking about how such and such method is called whenever is called at the right moment, but what exactly is doing the calling?
public static void main(String[] args)
{
CharStream inputStream = CharStreams.fromString("sessionToken=abc123; Expires=Wed, 09 Jun 2021 10:18:14 GMT");
CookieLexer cookieLexer = new CookieLexer(inputStream);
CommonTokenStream commonTokenStream = new CommonTokenStream(cookieLexer);
CookieParser cookieParser = new CookieParser(commonTokenStream);
CookieContext cookieContext = cookieParser.cookie();
TalkingListener listener = new TalkingListener();
ParseTreeWalker.DEFAULT.walk(listener, cookieContext);
}
You can see in the last statement of this example: the default walker. This is a method part of the ANTLR runtime that, given a parse tree and a listener object, calls the right listener method when performing a depth-first search.
A Listener Without a Parse Tree
A listener also has the unique ability to be used during parsing. You can create the parser and then use the method addParseListener with your listener.
parser.addParseListener(listener);
You could also disable the creation of the parse tree.
parser.setBuildParseTree(false);
This opens an interesting opportunity to improve performance, by performing some operations on the results of parsing without creating a parse tree.
The drawback of this approach is that the parser usually deals with parsing errors by throwing exceptions. For small errors, it can also recover and keep parsing. This is neat, but it risks making problems for the code in your listener, that could see malformed or unexpected code.
Conversely, your listener code can create problems for the parser, if it throws an exception. That is because the parser expects to deal with its own exceptions, but cannot handle your custom ones. A solution to this issue is overriding the parser method triggerExitRuleEvent(), with something like this code (example taken from the ANTLR documentation).
protected boolean listenerExceptionOccurred = false;
/**
* Notify any parse listeners of an exit rule event.
*
* @see #addParseListener
*/
@override
protected void triggerExitRuleEvent() {
if ( listenerExceptionOccurred ) return;
try {
// reverse order walk of listeners
for (int i = _parseListeners.size() - 1; i >= 0; i--) {
ParseTreeListener listener = _parseListeners.get(i);
_ctx.exitRule(listener);
listener.exitEveryRule(_ctx);
}
}
catch (Throwable e) {
// If an exception is thrown in the user's listener code, we need to bail out
// completely out of the parser, without executing anymore user code. We
// must also stop the parse otherwise other listener actions will attempt to execute
// almost certainly with invalid results. So, record the fact an exception occurred
listenerExceptionOccurred = true;
throw e;
}
}
This code would stop parsing if it encounters an exception thrown by your listener. Obviously, you could modify this code to keep parsing if you can handle the exception in a proper way.
In our professional parsers it is rare that we want to use this approach, since a listener is rarely sufficient for complex operations. Therefore we always need the parse tree, which limits the usefulness of this approach. However, it is an interesting possibility for well-defined tasks that require parsing something, such as creating diagrams or collecting statistics about some code. Taking a grammar and pairing with a proper listener you can accomplish your task pretty quickly with this method.
Creating a Visitor
You can generate a visitor using the standard ANTLR tool.
antlr4 Cookie.g4 -visitor
This will generate a parser and visitor in Java. Remember that by default the ANTLR command line tool generates a listener. So, if you want to avoid generating a listener, you need to use the option -no-listener.
antlr4 Cookie.g4 -visitor -no-listener
In any case, this will generate two visitor files.
The Visitor Classes
The first is an interface CookieVisitor<T>, that would start in this way.
public interface CookieVisitor<T> extends ParseTreeVisitor<T> {
/**
* Visit a parse tree produced by {@link CookieParser#cookie}.
* @param ctx the parse tree
* @return the visitor result
*/
T visitCookie(CookieParser.CookieContext ctx);
/**
* Visit a parse tree produced by {@link CookieParser#name}.
* @param ctx the parse tree
* @return the visitor result
*/
T visitName(CookieParser.NameContext ctx);
/**
* Visit a parse tree produced by {@link CookieParser#av_pairs}.
* @param ctx the parse tree
* @return the visitor result
*/
[..]
Apart from the obvious differences, this is very similar to the corresponding listener interface. The first difference is that there is only one visit method for each node. The second one is that it is a generic interface with a parameter T that determines the type of the value returned by each visitor method. For example, when implementing a CookieVisitor<int>, visitName will return an int value.
This approach allows a visitor to function like an interpreter. A typical example would be to use it to calculate and pass around the results of subexpression for creating a calculator.
Just like for a listener, this is an interface that defines the methods necessary to implement a standard visitor for the cookie parser. The other methods are omitted for brevity, but there is a visit method for each parser rule.
In the following image you can see an example of how the visit_Avpairs() method will be fired when the visitor enters the node.
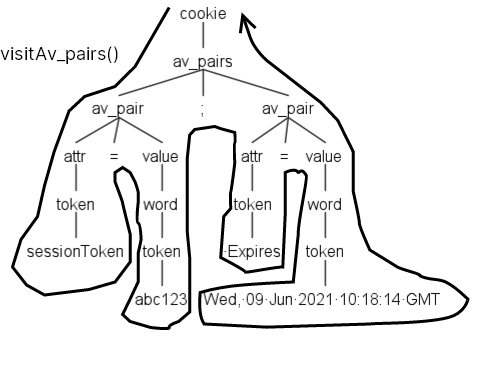
This particular behavior is implemented by the second class, CookieBaseVisitor. This is the class that saves you from boilerplate code by implementing the interface.
public class CookieBaseVisitor<T> extends AbstractParseTreeVisitor<T> implements CookieVisitor<T> {
/**
* {@inheritDoc}
*
* <p>The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.</p>
*/
@Override public T visitCookie(CookieParser.CookieContext ctx) { return visitChildren(ctx); }
/**
* {@inheritDoc}
*
* <p>The default implementation returns the result of calling
* {@link #visitChildren} on {@code ctx}.</p>
*/
@Override public T visitName(CookieParser.NameContext ctx) { return visitChildren(ctx); }
[..]
This file implements a visitor with all the methods that implement the default behavior of a visitor. Notice that there is a big difference between a default implementation for a listener and for a visitor. The methods of a default listener do nothing, while the methods of a default visitor do something very important.
They call the default method visitChildren. This method will perform a depth-first search and call the corresponding visit method during this search. For example, for an av_pairs node it will call visitAv_pair for each av_pair node that is in the current node.
This is what creates the default behavior of a visitor. And, if you want to change this default behavior, all that you have to do is implement a visit method in your visitor that does something different.
This is the big difference between a listener and a visitor: you can change the behavior of a visitor.
Implementing a Visitor
For example, we implement a CountVisitor that counts the number of nodes inside the parse tree. However, we are going to count nodes only down to the level of attr and value. And we can do that simply by overriding the proper methods and avoid calling visitChildren inside of them.
So, looking back at our example parse tree, we are going to avoid counting nodes of type token and word because we are bad at math for the sake of simplicity.
public class CountVisitor extends CookieBaseVisitor<Integer> implements CookieVisitor<Integer>
{
@Override
public Integer visitAv_pair(com.strumenta.examples.ListenerVisitor.CookieParser.Av_pairContext ctx)
{
if(ctx.value() != null)
return visitAttr(ctx.attr()) + visitValue(ctx.value());
else
return visitAttr(ctx.attr());
}
@Override
public Integer visitAttr(com.strumenta.examples.ListenerVisitor.CookieParser.AttrContext ctx)
{
return 1;
}
@Override
public Integer visitValue(com.strumenta.examples.ListenerVisitor.CookieParser.ValueContext ctx)
{
return 1;
}
protected Integer aggregateResult(Integer aggregate, Integer nextResult) {
return Integer.sum(aggregate, nextResult);
}
protected Integer defaultResult() {
return 0;
}
}
There are a couple of ways to approach the problem. For the sake of the example we use a mix of two, but obviously you would pick just one in a real-case scenario.
The first approach is shown in visitAv_pair. Here, we manually visit the nodes and sum the results. Since in av_pair a value is optional, we make sure to manually handle both cases, with and without the presence of a value.
The second approach is shown at the end of the visitor and relies on visitChildren. This is the default implementation of the method.
@Override
public T visitChildren(RuleNode node) {
T result = defaultResult();
int n = node.getChildCount();
for (int i=0; i<n; i++) {
if (!shouldVisitNextChild(node, result)) {
break;
}
ParseTree c = node.getChild(i);
T childResult = c.accept(this);
result = aggregateResult(result, childResult);
}
return result;
}
As you can see, it does not simply visit all the children, but uses two methods, aggregateResult and defaulResult to aggregate the result of the single call to the visit methods. This is half-way through the implementation of a correct sum of the children.
It is half-way because the implementation of the two aforementioned methods is not meaningful.
protected T defaultResult() {
return null;
}
protected T aggregateResult(T aggregate, T nextResult) {
return nextResult;
}
In fact defaultResult returns null and aggregateResult returns nextResult. However, we cannot fault ANTLR for that, because there is no meaningful way to create a default aggregation algorithm for any possible type of node. How do you aggregate custom classes? It depends.
We just need to implement these methods in a way that makes sense for our integer-based visitor.
This is what we do when we override those visitor methods.
protected Integer aggregateResult(Integer aggregate, Integer nextResult) {
return Integer.sum(aggregate, nextResult);
}
protected Integer defaultResult() {
return 0;
}
In aggregateResult, we use a standard sum method to aggregate the results of integers. In defaultResult we return 0, which is obviously the additive identity in a sum.
Once we do this, we can use our visitor.
public static void main(String[] args)
{
CharStream inputStream = CharStreams.fromString("sessionToken=abc123; Expires=Wed, 09 Jun 2021 10:18:14 GMT");
CookieLexer cookieLexer = new CookieLexer(inputStream);
CommonTokenStream commonTokenStream = new CommonTokenStream(cookieLexer);
CookieParser cookieParser = new CookieParser(commonTokenStream);
CookieContext cookieContext = cookieParser.cookie();
TalkingListener listener = new TalkingListener();
CountVisitor visitor = new CountVisitor();
System.out.println("Number of nodes: " + visitor.visitCookie(cookieContext));
}
This will print this result:
Number of nodes: 4
Notice that we did not need a walker. We can just call the visitCookie method of our visitor.
You Control the Visitor
The most important thing about the visitor is that it puts you in control of the process. There is a standard implementation that defaults to a depth-first approach, but you can easily change that. The default implementation is a convenience, not a constraint.
You can do whatever you want, you can even mix and match: you can perform a depth-first search for most of the nodes and use a custom strategy for some nodes.
Another peculiar advantage of the visitor is what it saves you from doing. When using a listener many complex operations involving multiple layers require you to keep a stack. For example, if you need to keep track of the scope in which you are in, you need to do something like this.
enterBlock(block):
scopes.push(block)
[..]
enterAnotherLevel(level):
scopes.push(level)
[..]
exitAnotherLevel(level):
scopes.pop()
[..]
exitBlock(block):
scopes.pop()
This is necessary because of the series of listener methods calls. However, you do not need to do that for a visitor. You can usually come up with something simpler.
visitBlock(block):
prev_scope = scope
scope = block
When to Use Neither a Listener Nor a Visitor
We have seen the advantages and disadvantages of listeners and visitors. If nothing fits your needs, there is always the case of manually traversing the parse tree. It is actually rare that you need to do that in normal circumstances, given that the visitor is quite flexible.
However, it happens that you want to use the visitor pattern, without using the default visitor implementation. We did that on some occasions, for example because we did not always want to return the same type from a visitor method.
If you think about it, the visitor pattern in itself is nothing else than a way to implement a depth-first search. So, you can apply it yourself any time you need to perform a depth-first search. You just need to call the proper visit method on the child nodes and this will create a cascade of calls from the root to the last leaves.
We did implement basic transpilers using nothing else than visitors and listeners. So, they are flexible and effective.
Our kolasu library is an example of a case when you need to do something else. Essentially this is a library to transform a Parse Tree created by ANTLR into an Abstract Syntax Tree best suited for a specific application. In that case, we traverse the tree manually because we want to transform each node in the parse tree into something else. We also add other features to simplify navigating the tree, so essentially this requires us to recreate a new tree. This is something that requires us to completely govern the process of navigation manually.
Do You Ever Need to Use a Breadth-First Search?
In theory you may also want to navigate the parse tree in a breadth-first manner: traversing all the sibling nodes before the children nodes. This is rare in a parsing scenario. I say rare, but I actually never encountered the need. That is because to get a fully meaningful representation of the content of a tree you need to get to the leaves of the tree.
For example, think about an addition. From the root of the tree you see a node representing an addition of two expressions: a left and right one. But to actually obtain the result of the addition you need to know the result of the two expressions. You need to know if left is 5 and right is 3, or left is 5 * 2, etc.
Generally speaking, a breadth-first search can be applied to explore a (potentially) infinite tree. In such cases you cannot fully explore the tree, therefore you need an alternative approach. You create some heuristic to evaluate each sibling node and then you explore further the most promising node.
In parsing it is rare that you want or need to do that. Strictly speaking, you cannot do that on the parse tree, because you cannot generate an infinite parse tree. However you may want to simulate this approach, for example with progressive parsing.
Progressive Parsing
Imagine you need to parse a language with an embedded language. Let’s say a language that embeds SQL in specially delimited strings. To save some time, you just identify the SQL string, but decide not to parse SQL. You call a second SQL parser on this string, only if the user of your application requires you to analyze SQL. In such cases you effectively perform a mix of depth-first and breadth-first parsing.
Another case in which you want to use this approach is when you need to perform expensive operations on the parse tree. Imagine, for example, that you want to interactively generate a diagram for a very large parse tree.
Creating a full diagram is expensive, this can be because creating a diagram for the whole tree is expensive or simply because drawing all the elements occupies a lot of memory and takes a lot of time. So, you start just by generating a representation of the root node and its children. Then, when the user clicks on a node, you expand the node and generate the right representation on-the-fly. You are effectively implementing a breadth-first search of the parse tree.
As you can see, it is rare that you want to do that in parsing. If it happens it is mostly because of an odd language or an application with an odd requirement.
Summary
In this article we have analyzed in depth listeners and visitors. We have seen how they are similar and how they differ and the use cases that best fit them.
They are powerful tools that are useful both as productivity boosts and because they offer a standard way to handle the result of parsing.
You should now be able to effectively take advantage of these useful tools that come free with your ANTLR parser.
Resources
If you are looking to learn more about ANTLR, you can find interesting our video course “Using ANTLR like a Professional”.
We also have a ANTLR tutorial.
And, an ANTLR FAQ and Cheatsheet.

")