
There are many uses for Code Generation:
- We can generate repetitive code from schemas or sources of information we have. For example, we can generate Data Access Objects from database schema files
- We can generate code from wizards
- We can generate skeletons of applications from simple models. We wrote about an example here: Code Generation with Roslyn: a Skeleton Class from UML
- We can generate entire applications from high level DSLs
- We can generate code from information we obtained processing existing documents
- We can generate code from information we obtained by reverse-engineering code written using other languages or frameworks
- We can generate code, using programming languages with powerful metaprogramming features
- Some IDEs have the functionality to generate boilerplate code, like the equals or hashCode methods in Java
So Code Generation can be used for small portions of code or entire applications. It can be used with widely different programming languages and using different techniques.
In this article we explore all the possibilities provided by code generation to give you a complete overview on the subject.
Why to Use Code Generation
The reasons to use code generation are fundamentally four: productivity, simplification, portability, and consistency.
Productivity
With code generation you write the generator once and it can be reused as many times as you need. Providing the specific inputs to the generator and invoke it is significantly faster than writing the code manually, therefore code generation permits to save time.
Simplification
With code generation you generate your code from some abstract description. It means that your source of truth becomes that description, not the code. That description is typically easier to analyze and check compared with the whole generated code.
Portability
Once you have a process to generate code for a certain language or framework you can simply change the generator and target a different language or framework. You can also target multiple platforms at once. For example, with a parser generator you can get a parser in C#, Java and C++. Another example: you might write a UML diagram and use code generation to create both a skeleton class in C# and the SQL code to create a database for MySQL. So the same abstract description can be used to generate different kinds of artifacts.
Consistency
With code generation you always get the code you expect. The generated code is designed according to the same principles, the naming rule match, etc. The code always works the way you expect, of course except in the case of bugs in the generator. The quality of the code is consistent. With code written manually instead you can have different developers use different styles and occasionally introduce errors even in the most repetitive code.
Why Not to Use Code Generation
As all tools code generation is not perfect, it has mainly two issues: maintenance and complexity.
Maintenance
When you use a code generator tool your code becomes dependent on it. A code generator tool must be maintained. If you created it you have to keep updating it, if you are just using an existing one you have to hope that somebody keep maintaining it or you have to take over yourself. So the advantages of code generation are not free. This is especially risky if you do not have or cannot find the right competencies to work on the generator.
Complexity
Code generated automatically tends to be more complex than code written by hand. Sometimes it has to do with glue code, needed to link different parts together, or the fact that the generator supports more use cases than the one you need. In this second case the generated code can do more than what you want, but this is not necessarily an advantage. Generated code is also surely less optimized than the one you can write by hand. Sometimes the difference is small and not significant, but if your application needs to squeeze every bit of performance code generation might not be optimal for you.
How Can We Use Code Generation?
Depending on the context code generation can just be a useful productivity boost or a vital component of your development process. An example of an useful use is in many modern IDEs: they allow you to create a skeleton class to implement interfaces or similar things, with the click of a button. You could definitely write that code yourself, you would just waste some time performing a menial task.
There are many possible ways to design a code generation pipeline. Basically we need to define two elements:
- Input: where the information to be used in code generation comes from
- Output: how the generated code will be obtained
Optionally, you may have transformation steps in between the input and the output. They could be useful to simplify the output layer and to make the input and the output more independent.
Possible inputs:
- A DSL: for example, we can use ANTLR to describe the grammar of a language. From that we can generate a parser
- code in other formats: database schemas. From a database schema we can generate DAOs
- wizards: they permit to ask information to the user
- reverse engineering: the information can be obtained by processing complex code artifacts
- data sources like a DB, a CSV file or a spreadsheet
Possible outputs:
- template engine; most web programmers knows template engines, that are used to fill the HTML UI with data
- code building APIs: e.g., Javaparser can be used to create Java files programmatically
Let’s now examine some pipelines:
- parser generation; readers of this website will be surely familiar with ANTLR and other such tools to automatically generate parsers from a formal grammar. In this case the input is a DSL and the output is produced using a template engine
- model driven design; plugins for IDEs, or standalone IDEs, that allows to describe a model of an application, sometimes with a graphical interface, from which to generate an entire application or just its skeleton
- database-related code; this use can be considered the child of model driven design and templates engine. Usually the programmer defines a database schema from which entire CRUD apps or just the code to handle the database can be generated. There are also tools that perform the reverse process: from an existing database they create a database schema or code to handle it
- metaprogramming languages; the groups includes languages that allows near complete manipulation of the code of a program, the source code is just another data structure that can be manipulated
- ad hoc applications; this category includes everything: from tools designed to handle one thing to ad-hoc systems, used in an enterprise setting, that can generate entire applications from a formal custom description. These applications are generally part of a specific workflow. For example, the customer uses a graphical interface to describe an app and one ad-hoc system generates the database schema to support this app, another one generates a CRUD interface, etc.
- IDE generated code: many statically typed languages requires a lot of boilerplate code to be written and an IDE can typically generate some of it: classes with stubs for the methods to implement, standard equals, hashCode and toString methods, getters and setters for all existing properties
Code Generation Tools
After this short introduction to the subject, we can see a few code generation tools.
Template Engine
The template engine group is probably the most famous and used. A template engine is basically a mini-compiler that can understand a simple template language. A template file contains special notations that can be interpreted by the template engine. The simplest thing it can do is replacing this special notation with the proper data, given at runtime. Most template engines also support simple flow control commands (e.g., for-loops, if-else-statements) that allow the user to describe simple structures.
There are many examples, let’s see two that represent how most of them behave.
Jinja2
Jinja2 is a template engine written in pure Python. It provides a Django inspired non-XML syntax but supports inline expressions and an optional sandboxed environment.
Jinja2 is a widely-use template engine for Python. It can do what all template engines do: create unique documents based on the provided data. It supports modular templates, control flow, variables, etc. However, it has also powerful security measures: an HTML escaping system and a sandboxing environment that can control access to risky attributes.
That is how a Jinja2 template looks like.
<title>{% block title %}{% endblock %}</title>
<ul>
{% for user in users %}
<li><a href="{{ user.url }}">{{ user.username }}</a></li>
{% endfor %}
</ul>
Jinja2 has special support for producing HTML pages, and that is what is most used for. However, it could be used to create other kinds of files.
Pug
Pug is a high-performance template engine heavily influenced by Haml and implemented with JavaScript for Node.js and browsers
In many regards Pug is like many other template engines: it supports modular templates, control flow, etc. The difference is that Pug looks like DSL and it is only meant to work with HTML. The result is that a Pug template looks very clean and simple.
doctype html
html(lang="en")
head
title= pageTitle
script(type='text/javascript').
if (foo) bar(1 + 5)
body
h1 Pug - node template engine
#container.col
if youAreUsingPug
p You are amazing
else
p Get on it!
p.
Pug is a terse and simple templating language with a
strong focus on performance and powerful features.
Parser Generation
A parser generator is a tool to automatically and quickly create a parser for a language. They are very successful and productive because the problem of parsing a language has been extensively studied. So there are solutions that can guarantee to parse most languages that people need to parse.
ANTLR
ANTLR is probably the most used parser generator. That means that there are many examples out there. However, the real added value of a vast community is the large amount of grammars available.
ANTLR takes as input a grammar: a formal description of the language. The output of a parser is a parse tree: a structure that contains the source code transformed in a way that is easy to use for the rest of the program. ANTLR also provides two ways to walk the parse tree: visitors and listeners. The first one is suited when you have to manipulate or interact with the elements of the tree, while the second is useful when you just have to do something when a rule is matched.
The format of the grammar is clean and language independent.
grammar simple; basic : NAME ':' NAME ; NAME : [a-zA-Z]* ; COMMENT : '/*' .*? '*/' -> skip ;
If you are interested in learning how to use ANTLR, you can look into this giant ANTLR tutorial we have written. If you are ready to become a professional ANTLR developer, you can buy our video course to Build professional parsers and languages using ANTLR.
Model Driven Design
These are usually plugins for IDEs, or standalone IDEs, that allows to describe a model of an application, with a graphical interface, from which to generate the skeleton of an application. This can happen because the foundation of model driven design is an abstract model, either defined with UML diagrams or DSLs. Once the main features of a program can be described in relation with the model, then it is possible to automatically generate a representation of that program. This representation of the model in code will have the structure generated automatically, but usually the behavior will have to be implemented directly by the developer itself.
For example, with model driven design you can automatically generate a class, with a list of fields and the proper methods, but you cannot automatically implement the behavior of a method.
Acceleo
Acceleo 3 is a code generator implementing the OMG’s Model-to-text specification. It supports the developer with most of the features that can be expected from a top quality code generator IDE: simple syntax, efficient code generation, advanced tooling, and features on par with the JDT. Acceleo helps the developer to handle the lifecycle of its code generators. Thanks to a prototype based approach, you can quickly and easily create your first generator from the source code of an existing prototype, then with all the features of the Acceleo tooling like the refactoring tools you will easily improve your generator to realize a full fledged code generator.
This is a quote from the Acceleo website that describes quite well what Acceleo does: implementing the principles of model-driven design. What it lacks is a description of the experience of working with Acceleo. It is basically an Eclipse plugin that gives you a tool to create Java code starting from a EMF Model, according to a template you specify. The EMF model can be defined in different ways: with an UML diagram or a custom DSL.
This image shows the workflow of an Acceleo project.

Umple
Umple is a modeling tool and programming language family to enable what the authors call Model-Oriented Programming. It adds abstractions such as Associations, Attributes and State Machines derived from UML to object-oriented programming languages such as Java, C++, PHP and Ruby. Umple can also be used to create UML class and state diagrams textually.
Umple is an example of a tool that combines UML modes with traditional programming language in a structured way. It was born to simplify the process of model-driven development, which traditionally requires specific and complex tools. It is essentially a programming language that supports features of UML (class and state) diagrams to define models. Then the Umple code is transformed by its compiler in a traditional language like Java or PHP.
Umple can be used in more than one way:
- it can be used to describe UML diagrams in a textual manner
- it can be used, in combination with a traditional language, as a preprocessor or an extension for that target language. The Umple compiler transform the Umple code in the target language and leaves the existing target language unchanged
- given its large support for UML state machine, it can work as a state machine generator; from a Umple description of a state machine an implementation can be generated in many target languages
The following Umple code is equivalent to the next UML diagram.
class Student {}
class CourseSection {}
class Registration
{
String grade;
* -- 1 Student;
* -- 1 CourseSection;
}

Instead the following Umple code describes a state machine.
class GarageDoor
{
status {
Open { buttonOrObstacle -> Closing; }
Closing {
buttonOrObstacle -> Opening;
reachBottom -> Closed;
}
Closed { buttonOrObstacle -> Opening; }
Opening {
buttonOrObstacle -> HalfOpen;
reachTop -> Open;
}
HalfOpen { buttonOrObstacle -> Opening; }
}
}
Telosys
The simplest and lightest code generator
Telosys is designed to generate all the plumbing and repetitive code. It does not require the use of UML, but allows users to generate a model from a starting database or using their DSL. It is an interesting and easy to use solution that also comes with IDE support in the form of an Eclipse plugin.
If you want to know more, we interviewed its author Laurent Guerin.
Database-related Code
It all revolves around a database schema, from which code is generated or from a database, from which a schema is generated. These kinds of generators are possible because of two reasons:
- relational databases support a standard language to interact with them (SQL)
- in programming languages there are widespread patterns and libraries to interact with databases
These two reasons guarantee that it is possible to create standard glue code between a programming language and a database containing the data the program needs. In practice, the database schema works as a simple model that can be used to generate code.
Many frameworks or IDEs contain basic tools to generate a database schema from a class or, vice versa, generate a class to interact with a table in a database. In this section we see an example of a tool that can do something more.
Celerio
Celerio is a code generator tool for data-oriented applications.
Celerio is a Java tool that includes a database extractor, to get a database schema from an existing database. Then it couples this generated schema with configuration files and then launches a template engine in order to create a whole application. The extracted database schema is in XML format.
For instance, there is an example application that generates an Angular + Spring application from a database schema.

Domain Specific Language
DSLs are a great way to capture the business logic in a formalized way. After that, this needs to be executed somehow. While sometimes interpreters and compilers are built to execute DSLs, very frequently code generators are used instead. In this way the DSL can be translated to a language for which a compiler already exist, like Java or C#.
Nowadays DSLs can be built using language workbenches, which are specific IDEs created to design and implement DSLs. Language Workbenches are useful because they also make possible to define editors and other supporting tools for the DSL at a reduced cost. This is very important because DSLs can be used by non-developers, who need custom editors to take advantage of the features of the language or simply are not able to use a common textual editor. Among other features language workbenches typically are integrated with code generation facilities. Let’s see a couple of examples.
JetBrains MPS
JetBrains MPS is a language workbench based on a projectional editor. You can use it to create one or more DSLs. It can also be used to extend an existing language. For example, mbeddr is an extension for C to improve embedded programming and it is based on JetBrains MPS.
The term projectional editor means that MPS preserves the underlying structure of your data and shows it to you in an easily editable form. The concept might be a bit hard to wrap your head around. Think about the traditional programming: you write the source code, then the compiler transforms the source code in its logical representation, the parse tree. The compiler uses this representation to perform several things, like optimization or to transform it in the machine code to be executed. With a projectional editor you are directly working with the logical representation: the parse tree. However, you can only modify it in the way that the editor (MPS) allows you.
The main consequence is that when creating a DSL with JetBrains MPS you need the whole IDE, with all its power and heaviness. You can get syntax highlighting, code completion, project management, etc.
The drawback of this approach is that you can modify the code only in certain ways. So, for example, normally you cannot do things like copy and paste some code into your program, what you see in your editor is just a representation of the code, not the real code (i.e., the parse tree).
However, the advantage of this approach is that you can create a DSL that uses any form of input to modify the code, so you can create a graphical editor, a tabular input or even normal text. This advantage makes it particularly useful to create DSL, that can be used also by non-programmers.
This video shows an overview of JetBrains MPS.
Generating Code with JetBrains MPS
The workflow of working with JetBrains MPS is done mostly inside this software itself: you manipulate all aspects of your language in there. Once you have done all of this, you may want to execute your code. The most common way to do this it is to translate it to a language for which you have a compiler. Here comes in play code generation.
This requires to do two things:
- Translating high level concepts to lower level concepts (essentially a model to model transformation)
- Have a text generator that takes the lower level concepts and map them directly to text
Obviously here we cannot go into many details, but we can show you an example of a template used for model to model transformations. In the following example we want to map a concept named Document to the corresponding Java code. You will see that we have basically a Java class with a main method. Inside that class some elements are fixed while others depends on the values of Document (i.e. the name of the class and the content of the container)
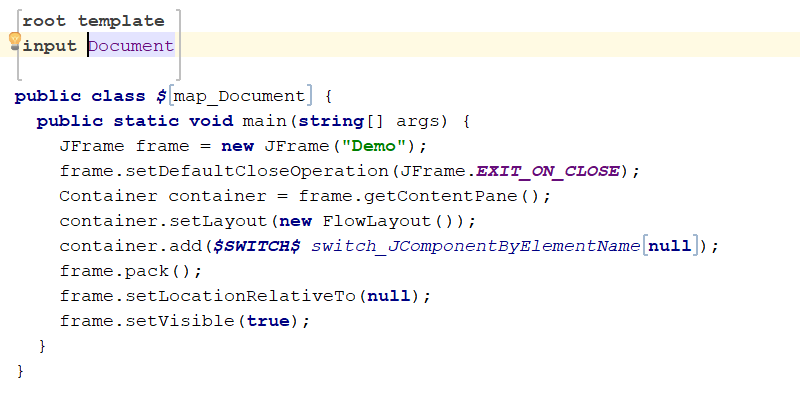
We have said that this is model to model transformation, because this template will generate a Java model. However MPS comes also with a text generator that can translate a Java model into code so at the end you will get a Java file like this one:
package jetbrains.mps.samples.generator_demo.test_models.test1;
/*Generated by MPS */
import javax.swing.JFrame;
import java.awt.Container;
import java.awt.FlowLayout;
import javax.swing.JButton;
public class Button {
public static void main(String[] args) {
JFrame frame = new JFrame("Demo");
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
Container container = frame.getContentPane();
container.setLayout(new FlowLayout());
container.add(new JButton());
frame.pack();
frame.setLocationRelativeTo(null);
frame.setVisible(true);
}
}
This is the easiest way to generate code using the facilities provided by the MPS platform. However, nothing forbids you to generate the code yourself. Since you can use this language also to define the behavior of the components, you could use it to interact with the filesystem directly and write the code yourself. For example, you could write C#, Python or any other language into a file manually.
Basically, you could create a new file and add content to it, like this print("Python code here"). Of course it would be cumbersome, since you would basically write long strings of text in a file. So, this approach is useful only for writing configuration files or data formats, not code in a programming language.
The following video shows how to create a simple language with JetBrains MPS. Notice that this is an old video, so details will have changed. However, it is still useful to give you an idea of how it is working with JetBrains MPS.
Xtext
Xtext is a language workbench, built on top of Eclipse and the Eclipse Modeling Framework. It can be used to design textual DSLs and obtain editors for them. Functionally Xtext is a combination of different tools (e.g., ANTLR to parse, Eclipse for the UI, etc.) assembled to generate DSLs.
For instance you are going to define a grammar for your DSL using the ANTLR format, like in this example.
grammar org.example.domainmodel.Domainmodel with
org.eclipse.xtext.common.Terminals
generate domainmodel "http://www.example.org/domainmodel/Domainmodel"
Domainmodel :
(elements+=Type)*;
Type:
DataType | Entity;
DataType:
'datatype' name=ID;
Entity:
'entity' name=ID ('extends' superType=[Entity])? '{'
(features+=Feature)*
'}';
Feature:
(many?='many')? name=ID ':' type=[Type];
Xtext itself will generate a parser that will recognize the code of your language and give you an EMF model. At that point you could use different systems to perform model-to-model transformations or code generation on the model.
Model-to-model transformation means that you can transform your model created with Xtext into another model. This could be an intermediate step on your way to generate code or the end product of your project. That is because Xtext takes advantage of already available tools, so you could use your EMF model with other tools from the EMF platform. This is one of the great advantages of using a platform like Xtext: it can be used as a piece of a larger toolchain.
Code Generation with Xtext
There is also flexibility in generating the code for your language. Compared to the monolith that is JetBrains MPS it has both advantages and disadvantages. One important advantage is the fact that the generation process is simpler.
Essentially Xtext gives you a language (Xtend) that is a more powerful dialect of Java, with things like support for macro. However it does not provide special powers to generate code.
This is an example of a file that governs code generation.
class StatemachineGenerator implements IGenerator {
override void doGenerate(Resource resource, IFileSystemAccess fsa) {
fsa.generateFile(resource.className+".java", toJavaCode(resource.contents.head as Statemachine))
}
[..]
def generateCode(State state) '''
if (currentState.equals("«state.name»")) {
if (executeActions) {
«FOR c : state.actions»
do«c.name.toFirstUpper»();
«ENDFOR»
executeActions = false;
}
System.out.println("Your are now in state '«state.name»'. Possible events are [«
state.transitions.map(t | t.event.name).join(', ')»].");
lastEvent = receiveEvent();
«FOR t : state.transitions»
if ("«t.event.name»".equals(lastEvent)) {
currentState = "«t.state.name»";
executeActions = true;
}
«ENDFOR»
}
'''
}
As you can see, while you are note exactly writing long strings of code, you are quite close: it is somewhat in between writing code and writing pure text. The support for macros reduces repetitions, but it is not a smooth experience.
This code in Xtend language is then automatically transformed into Java code, where it is very evident how manual the process is.
[..]
public CharSequence generateCode(final State state) {
StringConcatenation _builder = new StringConcatenation();
_builder.append("if (currentState.equals("");
String _name = state.getName();
_builder.append(_name);
_builder.append("")) {");
_builder.newLineIfNotEmpty();
_builder.append("t");
_builder.append("if (executeActions) {");
_builder.newLine();
{
EList<Command> _actions = state.getActions();
for(final Command c : _actions) {
_builder.append("tt");
_builder.append("do");
String _firstUpper = StringExtensions.toFirstUpper(c.getName());
_builder.append(_firstUpper, "tt");
_builder.append("();");
_builder.newLineIfNotEmpty();
}
}
_builder.append("tt");
[..]
return _builder;
}
It looks very much as if you had built the generator by hand.
In any case, this also shows an advantage of the ad-hoc nature of Xtext. This is just Java code that you can execute and work with however you want it.
JetBrains MPS and Xtext are very different: they have their strong points and weaknesses. One is all integrated, which makes easier to create standalone DSLs, the other is a combination of tools, which makes easier to integrate your DSLs with an existing codebase or infrastructure.
This presentation explains how to develop DSLs with Xtext.
DSL Development with Xtext – Sven Efftinge from JavaZone on Vimeo.
Metaprogramming Languages
Most languages have basic metaprogramming features and support reflection to let you analyze existing code or make decisions depending on what happens at runtime. For instance, with most programming languages you can use such features to automatically load plugins that are located in a specific directory in an existing application. Some languages, like C#, also have platforms that support the access to the compiler itself (i.e., Roslyn) to easily modify source code files.
However, it is hard to create whole new source code files or make complicated changes to them. That is because the language is designed to consider source code as pure text. It is the compiler that performs the magic transformation from text to code (i.e., parse tree).
There are few languages that take another approach: for them source code is just another data structure of the language itself. Lisp is probably the oldest language that adopts this approach: the whole language is built around the concept. The code is written using S-expressions, there is no distinction between code and data. Basically, a block of code is an expression in the language.
(if nil
(list 1 2 "foo")
(list 3 4 "bar"))
; if-else using an S-expression syntax: the first expression (list 1 2) is chosen
; if the condition (nil) is true, the second one otherwise
This makes not just possible, but easy to do things that you cannot do in other programming languages: this is why the language is loved by many and looks completely foreign to others. This is also why it is so hard to understand how to use the language, particularly macros that are what can manipulate the source code itself. So, we cannot hope to fully explain how to use them in a few paragraphs. However, we can explain the reason for their power and what you can do with them.
The gist of their power is that macros can manipulate code before the execution. This is the core difference between standard metaprogramming that can analyze code (e.g., reflection) only during execution and the advanced metaprogramming that allows to define whole new languages or features (i.e., adding multiple inheritance) after parsing, but before execution.
Julia
Let’s see an example of a macro in Julia, a language inspired by Lisp, that has a more accessible syntax.
julia> macro twostep(arg)
println("I execute at parse time. The argument is: ", arg)
return :(println("I execute at runtime. The argument is: ", $arg))
end
@twostep (macro with 1 method)
julia> ex = macroexpand( :(@twostep :(1, 2, 3)) );
julia> ex # the macro itself
:((println)("I execute at runtime. The argument is: ", $(Expr(:copyast, :($(QuoteNode(:((1, 2, 3)))))))))
julia> eval(ex) # execution of the macro
I execute at runtime. The argument is: (1, 2, 3)
As you can see, executing a macro and executing the expression returned by the macro are two different things.
This very powerful feature can be used for code generation: you do not need external tools to create boilerplate code, you can do it from the inside. In the following example, taken from the Julia documentation, you can see how it can define a series of new ternary operators.
for op = (:+, :*, :&, :|, :$)
eval(:(($op)(a,b,c) = ($op)(($op)(a,b),c)))
end
The code defines these new ternary operators taking advantage of the already defined binary operators:
- it applies the basic binary operation between the first two elements
- then it applies the operation again between the result of the first operation and the third element
Notice that the standard syntax of Julia is like that of a traditional language: no parentheses in weird places, normal expressions, etc. However when you use the metaprogramming features you work with the internal Lisp-like syntax.
This is just the tip of the iceberg, you can learn more about this power of metaprogramming by looking the at Julia manual.
Racket
If you want to do even more with metaprogramming you can use Racket, a language inspired by Lisp and Scheme (another language influenced by Lisp).
Racket is a language and a platform at the same time, it is designed to be a language that can define other languages. So, it can even use more powerful metaprogramming features than macros. Racket allows to define whole new languages that change the syntax of the basic language. It can do that basically because it allows you to change parsing itself.
The traditional syntax of Racket is Lisp-like.
(define (four p) (define two-p (hc-append p p)) (vc-append two-p two-p))
You can change it, for instance, you can create a language to define documents: Scribble.
#lang scribble/base
@title{On the Cookie-Eating Habits of Mice}
If you give a mouse a cookie, he's going to ask for a
glass of milk.
The language allows you to create HTML, PDF, etc. You define the structure in the language and then you can generate whatever output you need.
This is a whole new level that matches metaprogramming and DSLs: you can easily create custom generators with an easy-to-use DSL-like interface. This approach can be taken when the target audience is other developers. That is because you get a powerful language, but it is just that: a language. Using Language Workbenches instead, you can have a whole set of powerful editing tools to help the average user get around the language.
We wrote an article looking a bit more in-depth into this interesting language.
Ad-Hoc Applications
This category includes everything: from tools designed to handle one thing to ad-hoc systems, used in an enterprise setting, that can generate entire applications from a formal custom description. These applications are generally part of a specific workflow. For example, the customer uses a graphical interface to describe an app and one ad-hoc system generates the database schema to support this app, another one generates a CRUD interface, etc.
This is not a proper defined category, but a catchall one that includes everything that does not belong to a specific group. This means that there is no standard structure for this group of programs. It is also a testament of the versatility of code generation: if you can create a model or description of the problem, then you can solve it with code generation. Of course, you still have to understand if it makes sense to solve the general problem and to create a code generation tool, or it is better to simply solve your problem directly.
In this section we talk about two tools: CMake, a development tool, and Yeoman, a scaffolding tool. The first one essentially produces configuration files: software that feeds other software. The second one simplifies the life of developers, by providing a way to create a ready-to-use project optimized for a particular software platform, library or need.
CMake
CMake is an open-source, cross-platform family of tools designed to build, test and package software.
CMake includes three development tools created to help developing with C and C++. The main tool is designed to generate build files (i.e., makefile(s) and project files) for different platforms and toolchains. For instance, it can generate makefiles for Linux and Visual Studio project files.
CMake is not a compiler. The user defines the structure of the project in the CMake format, then the tool generates the normal build files that are used in the traditional building process.
A CMake file looks like a series of commands/macro that set options/flags for the compiler, link libraries, execute custom commands, etc.
cmake_minimum_required(VERSION 2.8)
project("Antlr-cpp-tutorial")
[..]
if (NOT WIN32)
set(CMAKE_CXX_FLAGS "-Wdeprecated -Wno-attributes" )
endif()
[..]
if(APPLE)
add_custom_command(TARGET antlr4-tutorial POST_BUILD
COMMAND ${CMAKE_COMMAND} -E copy_if_different
"${PROJECT_SOURCE_DIR}/libs/antlr4-runtime.dylib"
$<TARGET_FILE_DIR:antlr4-tutorial>)
endif()
Yeoman
Yeoman is a generic scaffolding system allowing the creation of any kind of app.
Nowadays being a good programmer means much more than just knowing how to code. You need to know the best practices for every tool you use and remember to implement them each time. And that is hard enough when writing the code itself, but it is even more work when you need to correctly write the configuration files and use the right project structure. That is where a tool like Yeoman comes in: it is a scaffolding tool that generates with one command a new project which implements all the best practices instantly.
The core of Yeoman is a generator ecosystem, on top of which developers build their own templates. The tool is so popular that there are already thousands of templates available.
Yeoman is a JavaScript app, so writing a generator requires simply writing JavaScript code and using the provided API. The workflow is quite simple, too: you ask the user information about the project (e.g., its name), gather configuration information and then generate the project.
The following code shows part of an example generator to create a Yeoman template.
function makeGeneratorName(name) {
name = _.kebabCase(name);
name = name.indexOf('generator-') === 0 ? name : 'generator-' + name;
return name;
}
module.exports = class extends Generator {
initializing() {
this.props = {};
}
prompting() {
return askName(
{
name: 'name',
message: 'Your generator name',
default: makeGeneratorName(path.basename(process.cwd())),
filter: makeGeneratorName,
validate: str => {
return str.length > 'generator-'.length;
}
},
this
).then(props => {
this.props.name = props.name;
});
}
[..]
writing() {
const pkg = this.fs.readJSON(this.destinationPath('package.json'), {});
const generatorGeneratorPkg = require('../package.json');
[..]
this.fs.writeJSON(this.destinationPath('package.json'), pkg);
}
conflicts() {
this.fs.append(this.destinationPath('.eslintignore'), '**/templatesn');
}
install() {
this.installDependencies({ bower: false });
}
};
Conclusions
In this article we have seen a glimpse of the vast world of code generation. We have seen the main categories of generators and a few examples of specific generators. Some of these categories would be familiar to most developers, some will be new to most. All of them can be used to increase productivity, provided that you use them right.
There is much more to say about each specific categories, in fact we wrote a few articles on parsing generators for different languages: Java, C#, Python and JavaScript. However we wanted to create an introductory article to introduce to this world without overwhelming the reader with information. And you, how do you plan to take advantage of code generation?
Thanks to the /u/defunkydrummer for having suggested to add the metaprogramming languages section
Read more:
If you want to understand how to use ANTLR you can read our article The ANTLR Mega Tutorial.