")
Migrating your code from one programming language to another is no joke. The stakes are significant, and the challenges are pretty daunting. So common sense suggests being well prepared before starting. The way we get prepared is through our Migration Blueprint process. In this article, we explain the steps of the process, so that you can be inspired to make your own plan before starting a software language migration.
Do we really, really need a plan?
For folks’ sake, what is all this speech about planning? Can’t we just jump into action?
Performing the migration of an extensive software system from one programming language to another feels like transplanting a company’s know-how to a new technology. While the process is performed, the company needs this system to keep working, without interruptions. If you would ever have to undergo this kind of surgery, I guess you would prefer to work with someone who has a clear plan before starting. Opening the figurative chest of the company and then making it up as you go would probably not cut it (it would make for exciting times, though!).
A crucial aspect to consider is that the whole process is scary for most companies, as they have not gone through it before and do not know what to expect. There are also a lot of misconceptions about automated migrations, as very few people have experience with Language Engineering. So, building confidence before jumping into this adventure helps get the support of all the people involved. And we are going to need it if we want to be successful.
With this article, we try to dispel some mystery and explain how this can be done and how we do it each time.
Note: This process evolves from a previous one we had, which was called Audit & Analysis. Luckily, we are much better at Language Engineering than at naming. And yes, that means we spent a few years working on getting the best plan we could. We are happy to report that all our “patients” survived in the process.
An Overview of the Migration Blueprint process
Ok, enough with the introduction. What is this process about?
Well, this process is called Migration Blueprint, as in the Blueprint you would ask an engineer to produce before getting started with any non-trivial construction project.

In essence, the Migration Blueprint is about:
- Figure out why the company wants to go through this migration process
- Look at the existing system and learn as much as possible about it: how it is structured, the constructs that are most frequently used, the modules it is made of, the unused code, the functions of the standard library it depends on, etc.
- Define the new system architecture: which environment should we run in? Which programming languages should be used? Which frameworks? Are there patterns or guidelines the company would like to follow?
- Define a plan to get from the system we have (defined through a legacy language) to the system we want (expressing the same know-how in a modern programming language). What can go wrong? Which steps are we going to follow? How are you going to translate the UI? What about the data? Etc.
Before getting started: the why
Before we get started, we want to figure out the “why” behind this migration.
In our experience, there are two very common reasons behind the vast majority of the migrations:
- Hiring issue: the company wants to move away from languages such as RPG, Visual Basic, or EGL because they cannot find developers who are familiar with these legacy languages. Some companies decide to act on this when they have a few developers left (typically five or fewer), while others wait for Bob, the last developer left, to communicate that he is going to retire six months from now
- Costs issue: typically, Companies move away from languages like SAS or COBOL because of the costs associated with software or hardware licenses. The CFO of the company figures out that they could save from hundreds of thousands to tens of millions of dollars (depending on the size of the company) and conclude that this looks like an interesting opportunity
These are not the only reasons clients cite when they reach out to perform a migration, but they account for over 90% of the cases.
What about you? Have you heard about other reasons for migrating from one programming language to another?
What does it mean to understand the existing system?
This is the process’s first step, typically taking between 25% and 40% of the total effort.
Before we dare present our suggestions for migrating a system, we need to ensure we do our best to understand it. And that is quite a challenge. This typically means talking with developers who know these systems deeply because they developed them or evolved them for decades. One needs to gain their respect, be humble, study, and ask them the right questions.
The things to understand about a system are many:
- Environment: one needs to figure out where the system is currently running. Is it running on the AS/400? Which database is it using?
- Identify the technologies used: We need to determine the technologies involved. Is code written in RPG IV? Are there parts in RPG III or RPG II? Are CL scripts used? This is needed because as part of the translation, we may need to process more than one programming language, and several scripting languages or support files (like files describing file structures, screens, etc.)
- Identify modules: we need to figure out the overall architecture of the system. How many modules composed it? How do they interact? This is useful, as it enables us to plan for an iterative migration, moving module by module and not necessarily all of the system at once
- Identify dead code: we want to identify all the dead code. And you may be surprised at how much code is left around that no one has been running for years. Of course, no need to migrate the dead code
- Identify clones: in addition to identifying dead code, we also want to identify code clones so that we can remove them during the migration.

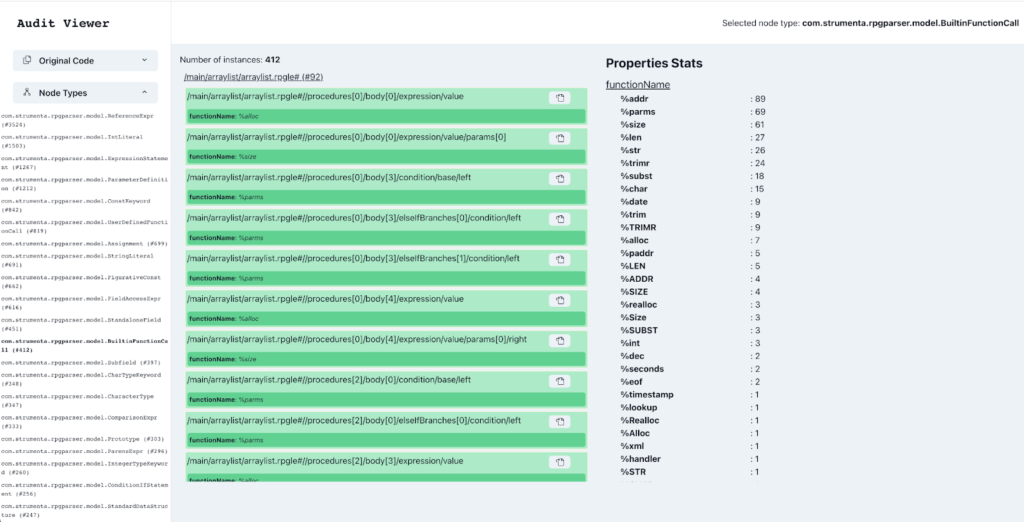
- Statistical analysis: we study which programming language constructs are used and which part of the standard library are used. This is important as, typically, legacy languages are very large, and their standard libraries can be huge. Most companies use only a subset of the capabilities of the language and standard library, and that is the subset we need to support in the migration. This information will be key to estimating the effort for performing the migration
- Largest and most complex files, procedures, and classes: we do not just look at statistics, but we also open up the largest and most complex elements of the codebase to study them. We want to know what are the biggest challenges as if we deal with them, we can deal with all the rest
- UI: we look at the UI specifically. Now, most legacy codebases are either batch programs or they have a form-based UI. There are exceptions to that, of course. We do that as the client may want to migrate the UI, and therefore, we need to translate it during the migration phase. But they may also want to rewrite it, and we could still generate documentation, or XML files, or diagrams to support the people performing the rewriting
- Data: Where is data stored? Some systems use relational databases, while others store data on files. The typical scenario involves moving from a non-relational database to a relational one, and we need to be ready for the challenges involved.
- Recurring patterns: we want to analyze the codebase to find typical idiomatic patterns. This is key to producing more idiomatic and maintainable code. The fact is that recurring blocks of code indicate a missing abstraction in the language, they indicate a specific intention. For example, on certain systems one iterates over the records, moving the cursor over each of them just to delete them. When we recognize some patterns we can translate the pattern and not the single statement. In this case, this pattern could be translated in a “clear table” command, in the migrated system.
What does it mean to define the target system?
This is typically the most straightforward step of the process, accounting for from 5% to 20% of the total effort.
Depending on the situation, the company looking to migrate its code may already have a pretty clear idea of what target technologies it wants to use. If this is the case, we just need to learn about those choices. In some cases, however, these decisions have not been made yet, and we need to take those decisions now in order to move forward with the migration.
In particular, we need to finalize and write down decisions about:
- The Environment: will the new system run on Linux boxes? Which OS? Will they be hosted in-house or on the cloud?
- Programming languages: which programming languages will be used? Java? Python? Which versions?
- Framework: deciding to migrate to Java or JavaScript is one important step, but different frameworks are available. Should we migrate to Spring Boot? Which version?
- Guidelines: Does the company already have guidelines they want to follow? Maybe they love Lombok, maybe they hate it. Maybe they have rules about code formatting. Do they have systems in the target language that we should integrate with or harmonize with?
- The database: Will we move the data? Or will we keep using the same database used in the original system?
- The UI: Will this be similar to the original one or a paradigm change? Will we move from a console-based UI to a graphical UI?
Define how to get from the system we have to the target system
This step typically takes roughly half of the total effort of the process.
In this phase, we want to do two things:
- Identify risks and define a mitigation strategy
- Define how the translation would look line
Risks management
At this time, we want to start with an open conversation. Let’s start by asking the people who know the current codebase what risks they perceive. Then, we need to understand which are just perceived and which are real. We also chip in, contributing our ideas on what typically turns out to be challenging.
Risks, perceived or real, are typically about:
- Performance
- Different arithmetic
- Maintainability of the transpiled code
- Testing
Each of these topics would deserve to be covered in a specific article (and if you are interested in that, let us know using the contact form!). What I can say in a few lines is that we want to be sure to discuss each risk. At this stage, we can plan for dealing with real risks and misspell perceived risks. To me, perceived risks are as important as real risks, as we want a team that is confident in the migration initiative and supports it.
Designing the translation
Here we simply take pieces of the original code and show how they would look like after the migration.
What pieces do we take, and why do we go through this process?
Well, we take pieces that are either common or problematic.
- Common pieces of code represent recurring patterns in the code. Through the initial analysis of the codebase, we know which single constructs are most frequently used, but we also identify common patterns. Those are sequences and combinations of constructs that are repeated multiple times. For example, a combination of a goto and a label that is used to emulate a do-while loop.
- The most problematic are either the most complex parts of code (measured by length, cyclomatic complexity, or similar metrics) or the ones discussed during the risk management conversation. If we can provide a satisfactory translation for those, confidence goes up
The translation of the database and the UI typically deserves some attention in this discussion. We would need to dive deeper into these two other topics in a separate article. Would you be interested in hearing about those? Use the contact form to let us know.
At the end of this phase, the need to trust that a translation is possible is much lower, as we have seen how the translation would look.
How does the process look like
We have seen what we need to cover, but you may wonder how the process works in practice.
It all starts with the Client delivering the code to us. We then take two weeks to study it, analyzing it through our internal tool, Code Insight Studio.
After two weeks, we hold the first workshop involving us and the Client. It lasts 90 minutes and is recorded. Depending on the complexity of the case, we hold another workshop every week or every other week until the fifth and last one.
Two weeks after the last workshop, we deliver a report.
So, the engagement takes between eight and twelve weeks.
What do we cover during the workshops?
We have guidelines about what we cover during the workshops, but the truth is that we then adapt to the specific circumstances. For example, some Clients have very clear ideas about the target system they want to build, while others need to hear their options and ask for an opinion from us. This may affect what we cover in Workshop #2. It can be unintuitive but we do not change the number of workshops. Over time, we reached the conclusion that 5 workshops are enough to provide a clear picture of what a migration would entail so that the Client can make an informed decision about it. Have less, and it would be a jump in the dark; have more, and you risk remaining entangled in an endless discussion when the time to go into action has come.
Below are the guidelines we use as a starting point for planning the workshops.
Workshop #1
We recap the structure of the engagement.
We start by discussing the migration goals and then focus on understanding the existing system.
Topics to cover:
- Why do you want to migrate?
- Do you want to throw away the legacy code or keep it and perform a continuous transpilation?
- Do you want to migrate all the code or only part of it?
- What does the application do?
- Who is using the application? For which purpose?
- Understanding the architecture of the existing system
- Examining how data is stored in the existing system
- Looking into code
- Different programming languages used
- Role of the different kinds of files (e.g., DDS, CL, Display Files, etc.)
- Size of the codebase
- Libraries you used frequently
- Looking into the UIs provided by the existing system
- Looking into the composition of the development team
- General considerations
- What drawbacks of the current system do you want to avoid?
- What are the main challenges you see with the migration?
If there is time, we can start sharing some initial stats on the codebase
Workshop #2
At this time, we are focusing on the requirements for the new system.
We then start discussing how to migrate the UI and the data.
- We discuss performance requirements
- Do you have any module- or operation-specific performance requirements?
- Which programming languages should be used for the new system? Do you require specific versions to be used?
- Discuss frameworks to be used
- Plans for the UI
- Which UIs do we want to dismiss?
- Which ones do we want to rewrite manually?
- Which ones do we want to translate?
- Plans for DB
- Which DBs do you want to keep where they are?
- Which DBs do you want to dismiss?
- Which DBs do you want to migrate? To which technology? Where would they be hosted?
- Rounding and mathematical operations
- We could discuss risk mitigation strategies for the risks that emerged during the first workshop
If there is time, we can discuss code clones and dead code that we identified.
Workshop #3
We discuss the migration of the code.
- We can discuss the data
- We can share ER diagrams
- Discuss foreign keys, primary keys
- We look at how to map the data
- Discuss how we will migrate data
- We should start by looking at more stats
- Prevalence of statements
- Prevalence of builtin function calls
- Prevalence of calls to framework functions
- We can share our understanding of the application supported by sequence diagrams
- We discuss the overall mapping (e.g., one RPG program into one Java class, one subroutine in one method)
- We look at common statements and how they will be translated
- Here, we expect the client to have an opinion
- Discuss how to handle comments
Workshop #4
We discuss the migration of the code.
- We look into the migration of specific patterns
- We show the patterns
- We explain how many instances we found of such patterns
- We propose how we want to translate them and start a discussion about that
During this workshop we transitioned from asking a lot of questions to discussing more and more code, showing our proposed translation from the constructs of the original language.
Workshop #5
We should then discuss the migration execution plan, or in other words, who will be doing what and in which order.
- Discuss testing
- Share template for end-to-end testing
- Discuss the execution plan
- Deploy the new system when it is ready for production. Who will do that?
- Deploy the new system continuously during development for manual testing. Who will do that?
- Manual testing (User Acceptance Tests) on the new system during development. Who will do that?
- Migration of data. Who will do that?
- Verify the new system behaves exactly as the old one. Who will do that?
- Verify the new system has a specific performance. Who will do that?
- Re-train developers. Who will do that?
- Ask for final doubts, comments, and perceived risks
- Explain the next steps
What do we do in between workshops?
We study the codebase between workshops and refine our analysis based on the elements that emerged during the workshops.
We also reflect on the translation, sketching how the new code would look like, given a certain piece of the original code. This translation is always done on slides first, but, depending on the time available, we may start drafting a transpiler or adapting an existing one, if we have one for the interested pair of languages. In this way we can demonstrate through this Proof-of-Concept the translation at scale of parts of the codebase.
What is contained in the report?
At the end of the engagement, we deliver a report that captures all of our discussions and conclusions.
The first objective of the report is to provide all the information for the Client to decide how to move forward. In addition , it can be stored and used ten years after the migration to reconstruct what happened and why certain decisions were made.
The report is composed of six sections. Below, we explain what is contained in each of them.
Section 1 – Goals of the migration
This section should summarize the migration goals in half a page or so.
Typically, the migration’s goals are cost reduction, solving a developer shortage, improving maintainability, or increasing scalability.
This section is typically unsurprising. Yet, we believe there is value in taking a moment to clarify why we are considering migrating our code so that the goal is clear to every single person involved in the project. It is surprising how many times we believe everybody has a clear view of an initiative’s goals, just to find out that at least someone has a very different perspective.
We also believe that is valuable to track these goals in a written report for two reasons:
- Shortly after the migration has been performed, the Client can look back at the goals and assess if the initiative is successful. This exercise, while scary, is important for organizations to do
- Years after the fact, the client’s team can reconstruct why such an important decision was taken and refer to the point of view their colleagues had at the time they took the initiative to proceed with the migration. The importance of documenting decisions is something that emerges as very obvious when working on migrations.
Section 2 – The current system
This section should provide an overview of the current system. It would typically take a significant part of the report and could be two to ten pages long.
We should start by explaining the system’s goals: What does the software do? Who is using it? For which purpose?
We should then explain the system’s structure. We should define the various components of the system with diagrams or words: on which hardware they run, how many different parts there are, where they are deployed, by whom, and how this system interfaces with other systems.
We should then list the different externalities that affected the definition of the current system and explain if any of those changed in the meantime. These could include laws, regulations, corporate rules, security rules, licenses, and any other such elements.
We should then look at the code, data, and UIs:
- Regarding the code: list language used (version) and supporting files such as DDS, CL, SQL scripts, build scripts
- Regarding the data: we could include ER diagrams, and describe the different databases and the main elements (i.e., the core 1-5 tables or data structures). We should also specify the version of the databases
- Regarding the UIs: how they look like now
We should discuss the modules into which the application can be divided. For example, we could have a series of batch scripts related to processing wire transfers, a separate set of applications for inserting wire transfers, and another one to produce reports.
We could then dive into a more analytical part. In particular we may want to include:
- Comments about the statistics on the size of the system (number of files, number of lines)
- Comments about the prevalence of the different constructs
- Comments about the quantity of dead code
- Describe common patterns in the code
Section 3 – The new system
This section lists the requirements for the new system. It could be five to fifteen pages long.
We describe:
- Which problems from the old system we want to avoid
- What are the requirements in terms of features or performance
- We describe decisions on the programming languages to be used, their versions, and the frameworks to be adopted
- We describe the different modules and the architecture, describing how they interoperate
- We describe the different databases to be used by the new system
- We describe the environment where each module will run. More specifically, we can look at the hardware and the OS used, but also at the fact that the module is to be run on the cloud or locally
- We describe the planned user interfaces, if any
Section 4 – Migration from the current system to the new system
In this section, we define a plan for migrating the existing system (described in Section 2) to the new system (described in Section 3). This section could go from five to fifteen pages.
In this section, we cover topics such as:
- The plan for migration of the UI: which parts of the UI of the new system will be replaced by which parts of the UI of the new system? We will define which parts will be migrated and which ones will be rewritten
- The plan for migrating the data, specifying which databases from the old system will be kept as-is and which ones will be migrated, and how
- Specify how we will translate the different elements. This section describes common code patterns and how they will be translated. This part is key to ensure idiomatic translation of the code
- We discuss risks identified during the workshops and the mitigation strategies we can put in place
- We define a testing strategy
- Provide the Test Specification Template
- Discuss end-to-end testing
Section 5 – Migration execution plan
This section details how to implement the plan presented in the previous section. It could be one to three pages long.
- We define a list of activities to be performed
- We discuss responsibilities to be handled for performing the migration: if the Client decides to move forward with the migration, who will perform each of the activities identified at the previous point? Strumenta, the Client, or a third party?
- Deploy the new system when it is ready for production
- Deploy the new system continuously during development for manual testing
- Manual testing (User Acceptance Tests) on the new system during development
- Migration of data
- Verify the new system behaves exactly as the old one
- Verify the new system has certain performance
- Re-train developers
In this section, we also indicate how long it would take for Strumenta to deliver the migration.
Section 6 – Final considerations
In this section, we include final considerations. Based on our experience with previous migrations, we provide comments on the challenges facing this project and the aspects to be kept under control during the migration’s execution.
This section is typically half a page long.
What do we get at the end of the Migration Blueprint?
So, after participating in five workshops and reading the final report, what does the Client get out of it?
- Confidence in the migration: they have seen the risks they identified, discussed, and answered. They have seen how the migrated code would look like. They had discussions with someone who solved the same problems multiple times before
- A preview of what we are going to get. They do not need to imagine. They could look at concrete examples of the translated code
- A plan that is based on data and indicating effort. They know how long it would take to migrate, and how much it would cost. They know who should be involved, who will do what, and the different steps
And now what? We answer that below.
What happens after the Migration Blueprint?
At this stage, the Client has enough information to make a decision.
In essence, their options are:
- Not performing the migration (or not doing it now)
- Go ahead, working with Strumenta
- Go ahead and do that on their own or work with other partners. The plan provided in the report would guide them step by step
Summary
There are many companies out there with important know-how trapped in old technologies. At the very least, this hinders their development speed, but in many cases, it puts those companies at risk.
There are ways to change that, and automated migration can greatly help. But so many companies do not know about them, and vendors out there make promises that sound vague and are not supported by anything concrete. So, we thought of doing something different and sharing many of our internal processes to give you a concrete idea of what it means to plan for a migration.
You know, it is not at all that scary if you know what you are doing.
We wish you all the best for your migrations. If you are interested in learning more about how we build transpilers, you can read How to Write a Transpiler.