
How an engineer is supposed to survive accounting
One of the “pleasures” of having your own business is dealing with accounting.
Now, to survive I tried a few things like:
One boring thing to do is to organizing receipts and invoices I had to pay: travel expenses, books, conference fees, etc. You get the idea.
Why I need a software to find dates in PDF files
Ideally I would like to have a tool that matches the receipts with lines from my bank statements and generate some report that could make my business consultant very happy.
The first step to do so is having a tool that given a bunch of PDFs can associate dates with them. Once I get dates I know which lines of the bank statement to consider and I can do the match (perhaps considering also the amount).
First step: get text out of PDFs
There are two possible situations: the PDF contains already the text or the PDF is a simple image and we need to recognize the text using OCR techniques.
In the first case things are relatively easy. We use PDFBox to extract the text:
fun getTextInPdf(fileName: String): List<PieceOfText> {
val reader = PdfReader(FileInputStream(File(fileName)))
val n = reader.numberOfPages
var i = 0
val listener = MyTextRenderListener()
val processor = PdfContentStreamProcessor(listener)
while (i<n) {
val page = reader.getPageN(i + 1)
val resourcesDic = page.getAsDict(PdfName.RESOURCES)
processor.processContent(ContentByteUtils.getContentBytesForPage(reader, i + 1), resourcesDic)
i++
}
reader.close()
return listener.process()
}
But of course real life brings always surprises. Some PDFs containsone block per paragraph (great!) while others contain one block per letter. That means that we have to look at the position of each single letter and see if it is contiguous to another one. In that case we need to merge them to get words.
If we do not have the text in the PDF we need to employ OCR techniques. I have used tesseract which is written in C++. To used it in the JVM I used the javacpp-presets.
Once we get the block of texts we need to split it in sequences of words. This part is relatively easy but not as trivial as expected because we need to take track of the exact position of each single word. So when splitting a block in words some math is involved to find the bounds of each word.
Second step: recognize dates
We have now a bunch of words. We need to look at those and finding sequences of words corresponding to dates.
Now dates can come in all sort of weird formats. Consider also that I have receipts in English (UK & US), French, German, and Italian.
Let’s see some examples.
First the classical DD/MM/YY:
- 15/04/2016
- 18-06-2016
- 01.04.2016
Sometimes you can find the YY/MM/DD instead:
- 2016-05-13
The month could be in letters, in any language:
- May 7, 2016
- 18 June 2016
- 22 Aprile 2016
- 1 juillet 2016
- avril 12, 2016
It could also be abbreviated:
- 2016 Apr 14
- 12 Apr 2016
Of course, there are dates that cannot be recognized for sure because the Americans at some point decided it was a good idea to invert the month and the day in dates. So if I read 2/3/2016 it could either be the 2nd of March or the 3rd of February. It means that some dates are ambiguous.
Third step: decide which date is the date of the order
Now, an invoice can contain many different dates. Consider this example:
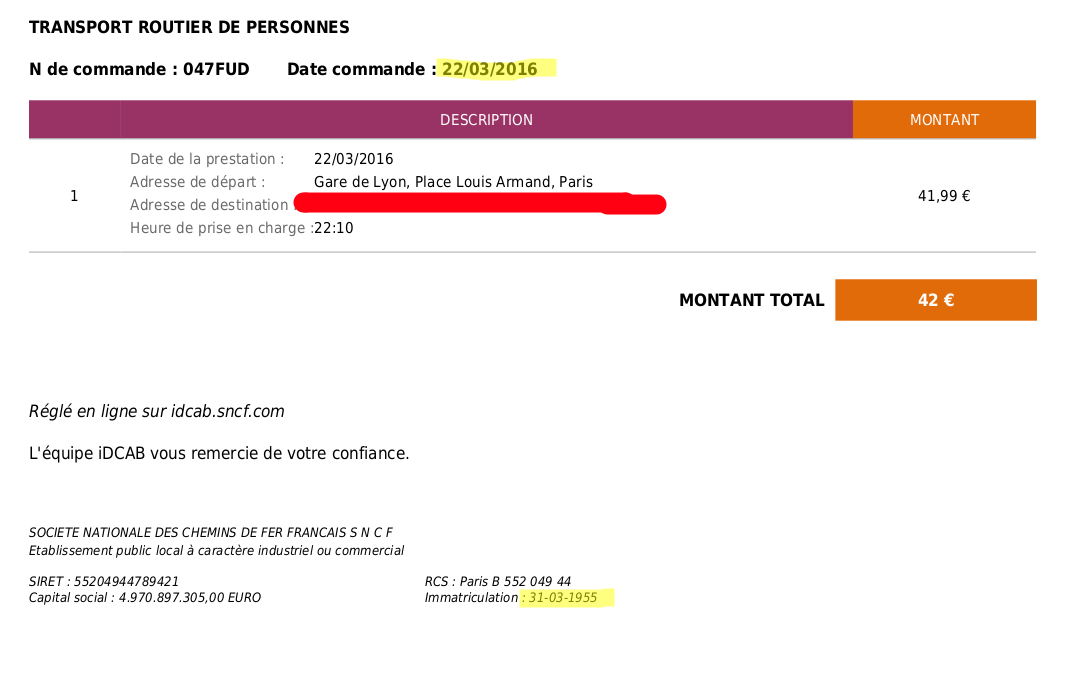
One date is the voice of the order (commande in French), another one is the date of registration of the company. This is definitely a date we are not interested into.
There are other examples:

Or again:


How do we handle this cases?
Well, we use a series of heuristics which seems to work in most cases. One of the most powerful is looking for meaningful words near the date such as facture/invoice/fattura, or order/commande/ordine. We can also use the size of the font and the position of the date on the page.
Do these tricks work always? No.
Do they work pretty often? Yes, they do.
Conclusions
Let me first of all share with you my enthusiastic appreciation for the date format chosen by Americans. I find it a really good idea and not at all idiotic and unfortunate. In practice it is a big source of pain and the first cause of error.
Most of my receipts are in the electronic format and they contain the text. In the few cases in which I needed to use OCR it seems to be working decently enough.
In the end I am quite satisfied with this prototype because after some tuning it seems to guess correctly over 90% of the time. Not bad, not bad at all.
Oh, well, I guess I have to go back to my accounting.
Any idea of things you would like to automate to make your life easier?
")
