")
It all started after attending LangDev 2022. We were watching a lot of great presentations about language engineering and realized that none of those tools were compatible. There were great editors of different kinds, model repositories, parsers, code generators, interpreters, symbol solvers and much more. Each one of them was incompatible, with the other tool being presented. And that was even at the lowest level (model exchange), let alone tighter integration. During this conference, we decided to create LionWeb: building Language Engineering applications by combining components.
Well, that was so blatantly irrational, that it could not be ignored. So, while sitting in front of a nice beer (or two) in Aachen, a bunch of language engineering professionals decided it was the time to solve this problem. And we started the LionWeb initiative.
You may wonder why it is important to be able to combine these components. To answer that, I think that a couple of examples could help.
Examples of Language Engineering solutions
Let’s look at some examples of language engineering solutions and see how they could be built combining several components.
Scenario 1: DSL for tax calculation
Suppose we are working for a company providing software for tax calculations to all tax consultants across Europe. We want to define a language that the different tax experts in the different European countries can use to define the formulas and rules for tax calculations.
We then want an army of QA engineers to write a set of tests, by specifying a scenario and defining what they expect the calculated taxes to be.
In this scenario we could use different components:
- The Tax Formulas DSL implemented using JetBrains MPS for expressing the formulas. This would be the tool used by the tax experts
- The Tax Testing DSL, running in the browser and implemented using Freon, to be used by QA engineers to conveniently define their test cases
- A code generator, that given the code written in the Tax Formulas DSL, will be able to generate the corresponding code in Java and C#, for executing the actual calculations for the clients of the tax consultants
- An interpreter that can process code written in the Tax Testing DSL and call the the code generated from the previous point, to verify that the results produced are the ones defined in the test
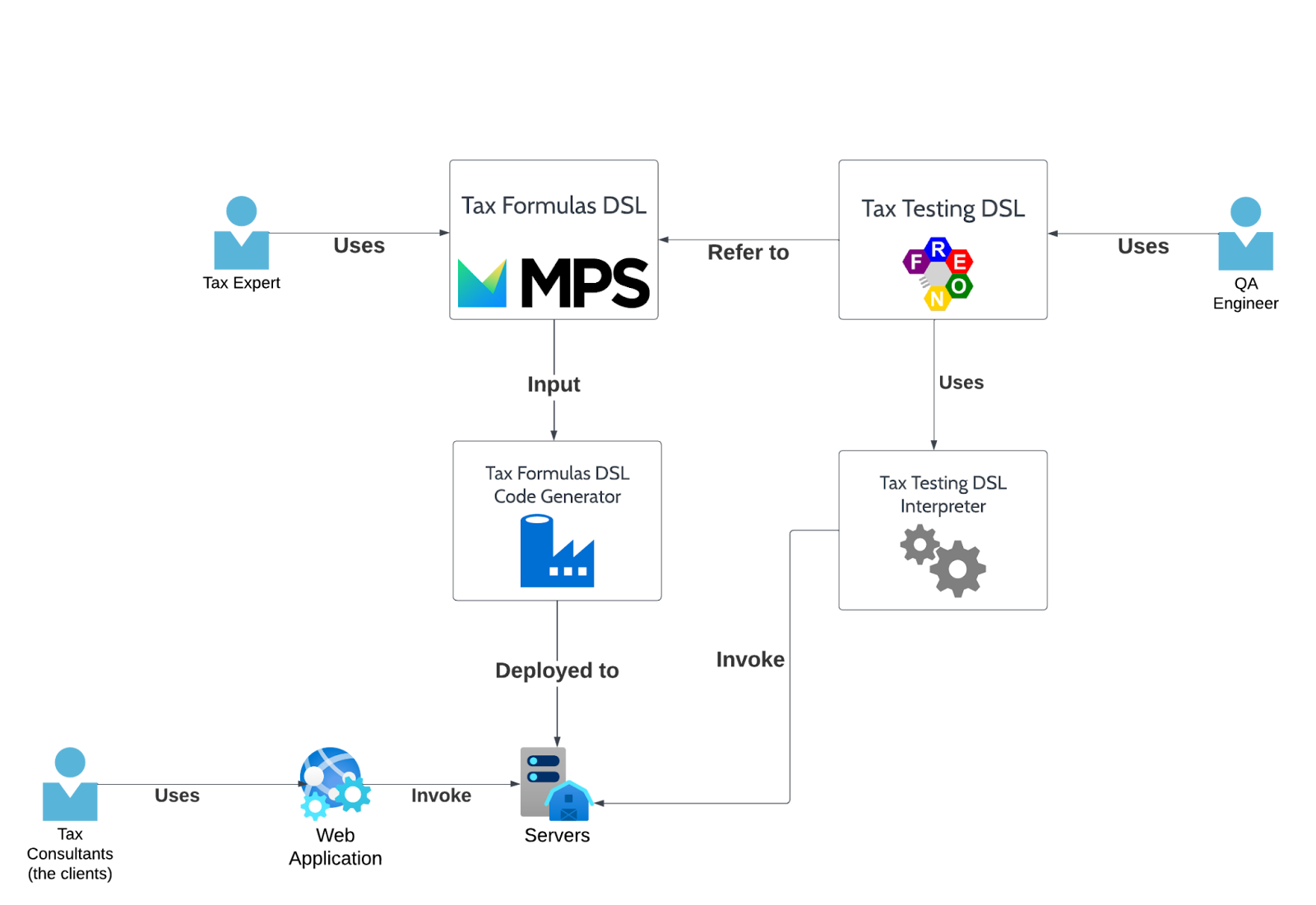
How do we need to integrate these components?
- The Tax Testing DSL will need to know about both the language definition of the Tax Formulas DSL and the models defined using such DSL.
While defining the Tax Testing DSL itself, we will need to refer to the concept defined in the Tax Formula DSL. For example, the language definition of Tax Formulas DSL could tell us that there are things called “Tax Definitions” and that a “Tax Definition” can be applied to physical persons (i.e., human beings), moral persons (i.e., companies, associations, etc.), or both. When defining the Tax Testing DSL we could say that when writing a scenario the scenario writer can pick a Tax Definition, and then a taxpayer. The Tax Testing DSL will then check if the taxpayer picked is compatible with the Tax Definition, and if not it will show an error. Writing these checks requires knowing the structure of the Tax Formula DSL.
The editor of the Tax Testing DSL, will then need to provide a way to pick existing Tax Definitions (through a combobox or through auto-completion). To do that it will need to find and load all the models defined through the Tax Formula DSL.
- The Tax Formulas Code Generator will need to know at compile time the structures of the Tax Formulas DSL. In this module we may write a for-loop that given all the Tax Definitions creates a corresponding Java class with the same name, and depending on which kind of tax payer the Tax Definition is applicable to, make the class extends a different base class (e.g., PhysicalPersonTaxDefinitionJavaBaseClass, MoralPersonTaxDefinitionJavaBaseClass, PhysicalOrMoralPersonTaxDefinitionJavaBaseClass). To write this code we will need to know the structures defined in the Tax Formulas DSL.
Then, when running the code generator, we will need to be able to load the single models of the Tax Formulas DSL, and read their data, to feed the code generator.
- The Tax Testing DSL interpreter will need to know at compile time all the concepts defined by the Tax Testing DSL. Its code will consist of navigating the models expressed through the Tax Testing DSL, evaluate the expressions defined there and invoke the code generated by the Tax Formulas Code Generator. In order to write the logic to evaluate the result of a string concatenation expression defined in the Tax Testing DSL, we will need to know that it has two fields and how they are called (e.g., left and right, or before and after).
The Tax Testing DSL editor will need to know how to invoke the Tax Testing DSL interpreter and process the results received back.
Scenario 2: Legacy Modernization
In this scenario, we want to process a legacy codebase, that contains code written in RPG, COBOL, and CL. RPG and COBOL are two General Purpose Languages, and CL is a language to define shell scripts.
Suppose that in this scenario we want to produce a web tool to produce a visualization of the system and explore it. The tool would be used to reverse engineer the architecture of the system, learn how it works and in this way help with maintenance.
Let’s suppose that we also want to write a transpiler to automatically translate a subset of the business logic defined in the system into a more modern language, such as Python.
In this scenario, we could use different components:
- An RPG parser
- A COBOL parser
- A CL parser
- A Model Repository: here we will store the output of the parsers, in a single place, where we can analyze and find connections between the different programs. For example, examining which RPG and COBOL programs are started by which CL scripts and which RPG and COBOL programs call each other
- The web tool that produce the visualization of the architecture of the system
- The transpiler translating RPG and COBOL code into a Python, with the support of a Python code generator. The transpiler itself received RPG and COBOL ASTs, and know how to transform them into Python ASTs. The finally step, consists of transforming the Python ASTs into actual Python code (i.e., a string). This step is demanded by the transpiler to the Python code generator.
- A Python code generator, useful to implement the transpiler defined above
In this scenario, we may have a team that will build a web tool, probably using Typescript and another team that will build the transpiler, let’s say using C#.
Now, both teams will need to be able to use an RPG parser, a COBOL parser, and a CL parser. However we do not want to build or buy an RPG parser implemented in Typescript (so that we can use it in the web tool), and another one implemented in C# (so that we can use it in the transpiler). These teams may want to reuse an existing RPG parser independently in which language it has been implemented. The same is true for the other two parsers. For example, in this scenario they could use the RPG parser provided by Strumenta and a CL parser provided by another vendor. What is important is that all of these parsers can communicate through LionWeb, so that they can be accessed by all components which can work with LionWeb, independently of which programming language they are written in (at this time LionWeb has bindings for Java and Typescript, with bindings with C# to be under development and bindings for Python being planned). By bindings we indicate libraries that can read and write LionWeb languages and models.
In a simpler scenario, some components may want to get directly the RPG, COBOL, or CL ASTs from the parser, while in this scenario they will instead get them from the Model Repository. In a sense, doing one or the other would be transparent as both the parsers and the model repository will expose LionWeb models. In this scenario, we have the Model Repository as a middle-man for two reasons:
- For performance reasons: we want to parse files once and store the AST
- To perform application-level symbol resolution. We need to process all ASTs obtained from parsing all the files part of the application and find the links between the different elements. For example, we need to associate each subroutine call with the corresponding subroutine definition. This is much easier to do if we have a central place where to store all the ASTs.
Similarly, we want to reuse whichever Python Code Generator we can find (provided it is compatible with LionWeb), and not having to necessarily find one written in C# (the language in which we want to write our transpiler, in our example).
LionWeb will help us to make all of these components interoperable.
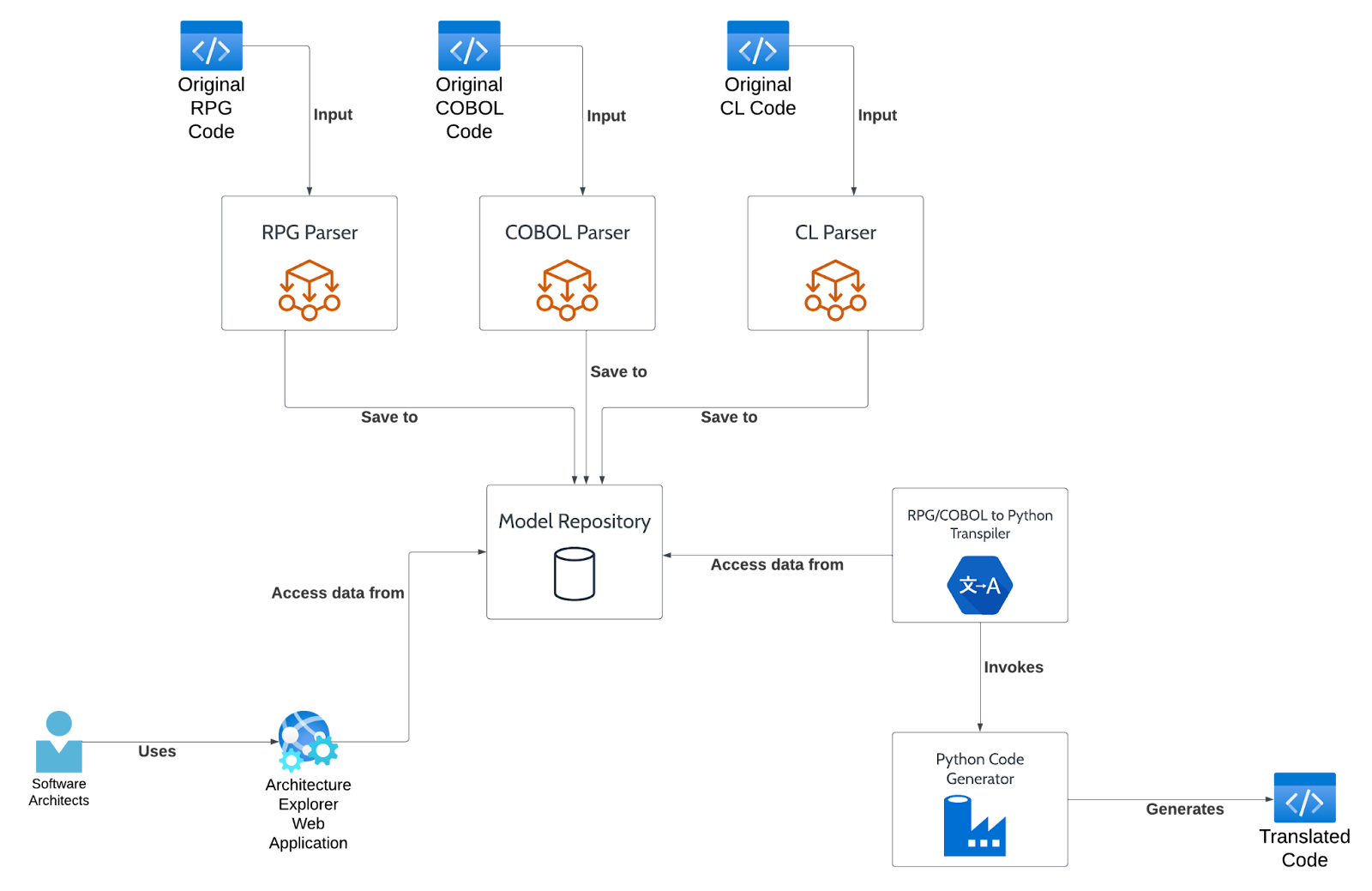
Let’s look at how these components are integrated:
- The different parsers need to export their results in an homogeneous format, which is understood by the Model Repository
- The transpiler will need how to access the Model Repository to retrieve the ASTs stored by the parsers (and later processed, to perform symbol resolution)
- The transpiler will internally define the result Python AST. It will then need to pass such AST to the Python Code Generator that will output actual python files
What kind of Language Engineering stuff may I want to combine?
Language engineering solutions typically have many moving parts:
- Editors: they permit to use a language to define “models”. They can be based on text (like most editors for programming languages) or projectional (like the ones you can build with MPS or Freon), they can run on Desktop (like MPS, IntelliJ IDEA, or VS Code) or in the browser (like Freon or CodeMirror). We may need to combine several of them, to offer different editors to different kinds of users. LionWeb is currently building support for Jetbrains MPS (see lioncore-mps) and Freon (see lioncore-freon).
- Parsers: to “recognize” code and extract information about its structure. Parsers based on one of the StarLasu libraries are compatible with LionWeb
- Code generators: in many systems we want someone to write some logic concisely and then generate different stuff from that single source of truth. To do that we use code generators. Code generators based on one of the StarLasu libraries are compatible with LionWeb
- Transpilers: to translate code from one language to another. They typically combine parsers and code generators with transformation steps. Transpilers based on one of the StarLasu libraries are compatible with LionWeb
- Model repositories: to store the data extracted from parsers, or directly defined using projectional editors. Modelix is planning to support LionWeb in the future.
- Interpreters: to execute code without code generation. Interpreters receive models, traverse them and based on their content calculate values or execute actions.
- Compilers: to generate machine code or bytecode, for a deferred execution of the code
- Symbol solvers, type systems: to further process the data extracted from parsers
These components are complex to build and in the language engineering field there are mostly small service providers. It is difficult to imagine that any of them would have the resources to build and maintain all these different components. But if we share these components, the range of what we can achieve expands significantly.
To build these and other components one could leverage the existing bindings to consume LionWeb languages and models from Typescript and Java. One for C# is currently being developed and it may be released as open-source at some point. We also hope to provide support for Python and other languages. What about you? Any language for which you would like to have LionWeb bindings?
What will LionWeb achieve?
We think that building a mechanism for making different language engineering components able to interoperate would be useful for the following reasons:
- Organizations adopting Language Engineering solutions could put them together combining a large set of components. This would means richer solutions, built more quickly and of higher quality, because the components would be reused and tested more extensively
- Organizations adopting Language Engineering solutions would also reduce the lock-in and increase their alternatives, as more components would be compatible with LionWeb and more vendors would be able to provide services around it. This is important considering that the typical language engineering services provider is small
- Language engineering services providers could be able to produce more valuable solutions for their clients, with a more limited effort. This could potentially mean better margins
- Researchers and innovators could leverage the basis provided by the LionWeb ecosystem to introduce incremental innovations, without wasting their energies on re-implementing the foundational technological stack. As someone who survived a PhD, I am very sensitive to this argument, as it is extremely frustrating to have to build a lot of layers of non-innovative stuff, in order to be able to add the bits that are relevant for the research. This makes the barrier impossibly high for everyone who is not part of a large research team, with an established presence in the field
How can I learn more about LionWeb?
- You can take a look at our GitHub repositories at https://github.com/lionweb-io/
- You can watch a presentation we gave at the MPS Days 2023 https://www.youtube.com/watch?v=dzZdjqbRzuU&list=PLQ176FUIyIUZ6e7lGYfyzYlnNkZiB2n9v&index=14
- You can join us on Slack at https://lionweb.slack.com/. To get an invite, contact the LionWeb team there or write to [email protected]
- You can watch interviews with some of the LionWeb contributors. Interviews are in progress and you will find all of them in Strumenta’s YouTube channel. For now we have published the interviews with Jos Warmer and with Markus Voelter
- You can write to the contributors reaching out to them individually or writing to [email protected]
Can I help?
Of course, we would be glad of any help we can get. LionWeb is a recent initiative and we need the support from other language engineering enthusiasts to make it work.
We would appreciate help from people that:
- Could give feedback on the idea
- May want to provide support for LionWeb in new or existing components
- Want to try out things
- Perhaps want to sponsor development of some components, as part of a solution that is useful to them
What’s next
We will keep discussing and finalizing the idea behind LionWeb, and the development work. The development is going on both on libraries reusable to build and consume LionWeb components, but also on components compatible with LionWeb. After so much work in getting things in motion, we hope to see LionWeb acquiring speed in the coming months, and we hope that you will be part of it, as a contributor, or as a beneficiary.
Acknowledgments
Markus Völter and Meinte Boersma reviewed this article before I published it: thank you! And thank you also to all the amazing members of LionWeb. Discussing with them weekly has been an amazing experience, and helped me learn a lot