")
In this article, we present Strumenta’s EGL parser, a battle-tested parser for IBM EGL. It’s also the only EGL parser that we are aware of. It’s based on our StarLasu methodology and real-world use cases.
You can use it to analyze a project and remove unused code. You can use it to provide autocomplete support in an editor. It can even be the foundation of a transpiler to move from EGL to Java.
The parser is commercially licensed, and we hope this article will be useful for anybody wanting to learn what a parser is for and how to use one.
We will show you two limited examples, to give you an idea of its potential:
- build documentation extracting the API of a REST service
- create a diagram from record definitions
Even if you are looking to design your own parser, we can help you by showing you why you might want to follow our Chisel method to build one. You can do that on your own too. You should expect it to take a significant effort and refinements over millions of lines of code before it’s in great shape. At least that is what it took us to get there.
What is a Parser (And What it is Not)
We work with parsers every day. So for us, it’s very clear what a parser is and what it can do. However, 99% of developers will never look too closely at what a parser is, so let’s refresh our memory.
In general terms, a parser is software that can understand the syntax, but not the semantics of code.
Fundamentally, a parser is software that creates a model of the input, so we can extract data from it.
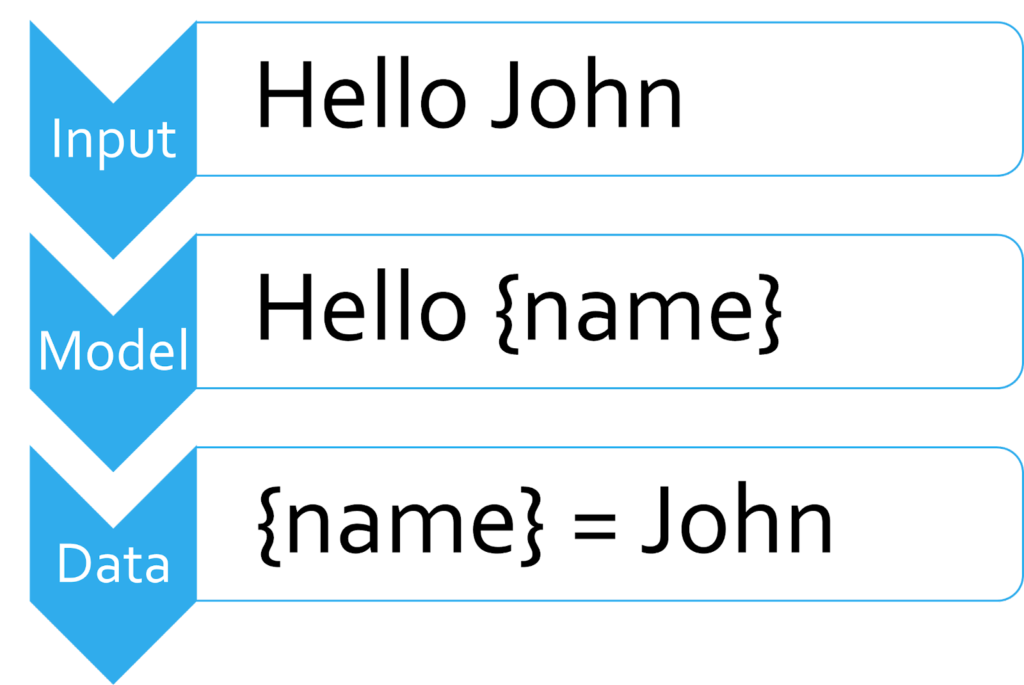
This model should be clear, useful, and easy to work with. The model that matches all these criteria is the Abstract Syntax Tree (AST). Using an AST to represent code is a common practice, Starlasu defines a standard. Of course, how to design the AST for a particular language is open to debate.
A parser can read the code, but it cannot execute it. For example, a parser can recognize both a variable declaration and an expression.
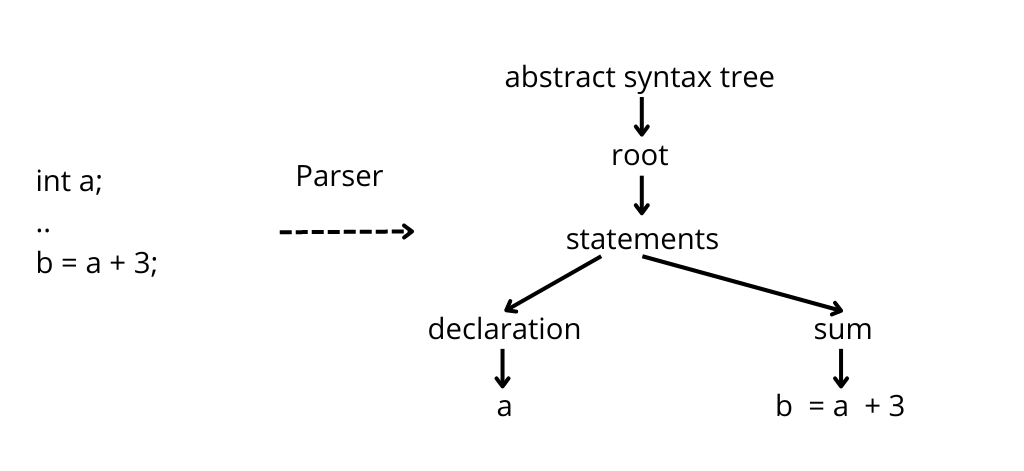
What it can’t do is link the two and understand where a variable used in an expression was declared. This feature is called symbol resolution and it’s a functionality built on top of the parser.
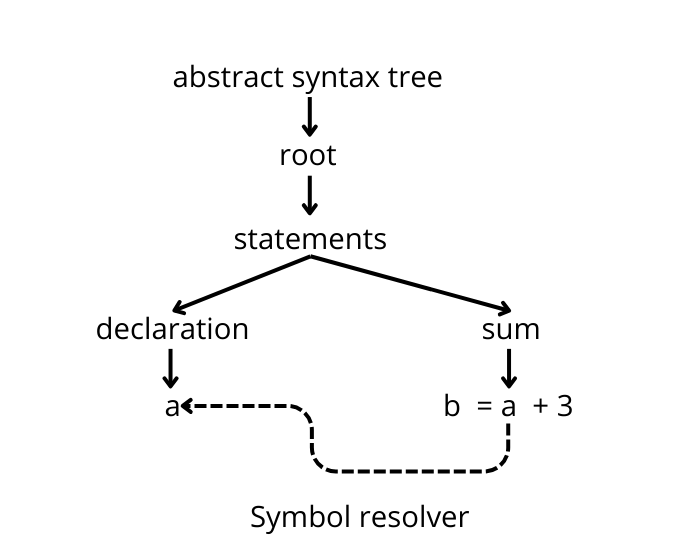
Given the needs of our clients, we implemented symbol resolution functionality. This is technically outside the scope of a parser, but it was needed, so we added it.
For example, our EGL parser can resolve references to record definitions. We are going to see some examples of what our specific parser can do later. However, it is an important point to keep in mind in case you are comparing different parsers.
Chisel Methodology
The EGL parser is based on the Chisel methodology. It’s the missing link between source code and a convenient structure for its interpretation and manipulation: an AST. When building an interpreter, transpiler, compiler, editor, static analysis tool, etc., at Strumenta, we always implement the software using a pipeline. A set of reusable components that can be shared for different projects.
For example, this is a pipeline for an EGL-to-Java transpiler.
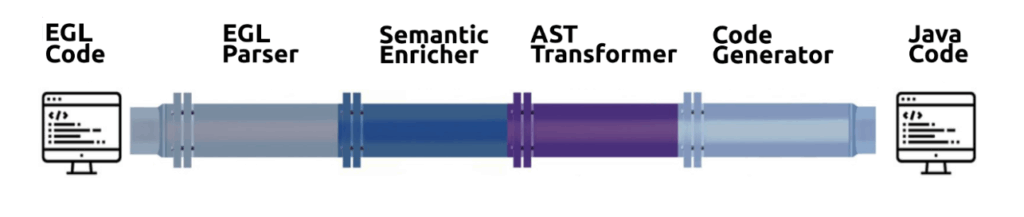
The EGL parser and the Semantic Enricher components can be re-used for, let’s say, building an interpreter. This approach increases productivity and improves the quality of the software. For instance, any core component improvement for one project is automatically shared with others.
StarLasu is a method, a set of supporting tools and a collection of runtime libraries that implement this methodology to support it in Java, Kotlin, Python, Javascript, Typescript, and C#.
At its core, StarLasu permits the definition of ASTs, on which all other functionalities are built. You can navigate and transform ASTs to do everything from reading the original values to simplifying your code. With the features provided by the library, you can do anything from analyzing a codebase to building a transpiler.
Some core features shared by our StarLasu libraries are:
- Navigation: utility methods to traverse, search, and modify the AST
- Serialization: export and print the AST as XML, as JSON, as a parse tree
- LionWeb and EMF interoperability: ASTs and their metamodel can be exported to the LionWeb or EMF formats
Interoperability with LionWeb and EMF is important because these are standard formats used in language engineering. So you can mix and match different software, even from different providers.
You can read more about our methodology in a dedicated article.
What is EGL?
EGL (Enterprise Generation Language) is a high-level, platform-independent programming language developed by IBM (and is now open-source). It enables rapid development of multi-platform enterprise applications and is commonly used on IBM i (AS/400, System i), integrating with COBOL, Java, JavaScript, and relational databases.
For instance, you can write EGL code and have the system generate Java code, so you can run it on the Java platform.
EGL was intended to allow rapid enterprise development with less concern about platform details, like middleware and glue code to the underlying. Thus enabling business-oriented developers to write full-stack applications.
What Do You Need an EGL Parser For?
EGL systems are typically large and complex. In many cases, EGL programs are older than the language itself. This isn’t the start of a logic puzzle: it’s a language adopted by companies that wanted to keep old codebases on their IBM AS/400 platform, but develop new code using a more modern language. One consequence of this typical use case is that programs were written to work with older custom software that followed patterns of COBOL or RPG code.
You may use a parser to modernize your EGL code and cut the time your developers lose in updating old-style code.
EGL simplifies development by abstracting the underlying complexity of UI, logic, and data handling layers. This allows business-oriented developers to build software ignoring technical implementation details. The downside is that somebody must actually implement the technical details.
For example, a common Java developers’ complaint is that the Java code generated by EGL has bad performance on the JVM, and it’s not easy to work with from the Java side. Another example is that somebody needs to implement the UI that is described using RUIHandler. Now, that development and maintenance of EGL is stopped, you might decide to take this UI description and generate a UI yourself.
To do any of these things you need to first understand the code. That’s where a parser comes in.
A parser helps you analyze the code structure and transform it into a meaningful representation like an Abstract Syntax Tree (AST). From there, you can enable a wide range of applications: refactoring, migration, documentation, or code generation.
Why Use a Ready-to-go Parser?
You need a parser that has been thoroughly tested, documented, and gives you someone to call in case you encounter any problems.
We are experts, and we have built tons of parsers for our clients. This means that we completely understand the importance of this component, and we have a solid methodology.
And we build parsers designed for what our users need. For example, our SAS parser is geared to support data lineage, because that’s what the typical user needs.
Our EGL Parser has also been built for the needs of our clients, so it is battle-tested by us and them. It comes with symbol resolution, so it can also power transpilers or static analysis tools.
How to Setup the Parser
The only requirements you need to use the parser are the ast and semantics modules. They are developed in Kotlin, so they’re easy to use in the JVM world. They can also be used from other languages as we can provide bindings for TypeScript, Python, and C#.
For example, for a Java maven you would write something like this.
<dependencies>
<dependency>
<groupId>com.strumenta.langmodules.kolasu-egl-langmodule</groupId>
<artifactId>ast</artifactId>
<version>1.0.1</version>
</dependency>
<dependency>
<groupId>com.strumenta.langmodules.kolasu-egl-langmodule</groupId>
<artifactId>semantics</artifactId>
<version>1.0.1</version>
</dependency>
</dependencies>
This would use the EGL ast and semantics module.
You can easily adapt this for another build system like Gradle.
dependencies {
implementation "com.strumenta.langmodules.kolasu-egl-langmodule:ast:1.0.1"
implementation "com.strumenta.langmodules.kolasu-egl-langmodule:semantics:1.0.1"
}
That’s all you need to be able to use the parser in your code just as easily as any other library.
Extracting and Documenting REST Service Interfaces
Imagine you’re maintaining a suite of EGL programs that uses third-party REST services. Over time, new services were added, old ones were modified, and some were deprecated. There’s no centralized documentation, and nobody knows which external services the EGL code uses. This makes it hard to keep track of what services your company uses or even migrating the interfaces to another language.
With the EGL parser, you can automatically:
- Identify all REST-enabled services (
@GetRest, etc.) - Extract metadata such as method, URL and path
- Generate a live catalog of used endpoints in formats like JSON or HTML
Keeping service documentation up to date manually is error-prone. By using the parser to generate this information, you ensure consistency between the code behavior and the documentation. This is quite useful for teams maintaining services or consuming APIs and for compliance purposes.
Example Interface
Let’s take a look at some example code. This is an interface necessary to bind an external REST service to an EGL program.
Interface WeatherForecast
Function GetWeatherByZipCode(zipcode string in) returns(myRecordPart)
{@GetRest{uriTemplate="/GetWeatherByZipCode?zipCode={zipcode}",
requestFormat = JSON,
responseFormat = JSON}};
end
We want to extract the metadata and produces something like this.
Endpoint: GET /GetWeatherByZipCode?zipCode={zipcode}
Input: [string zipcode]
Create Diagrams from Record Definitions
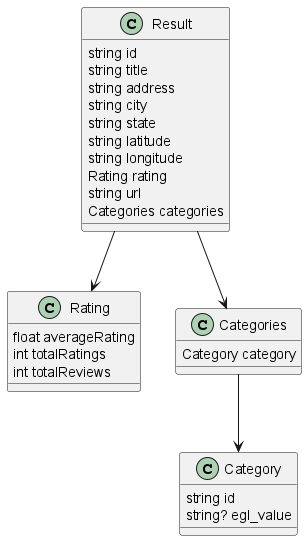
Imagine that you have a series of records, like the following ones.
record Result id string; title string; address string; city string; state string; latitude string; longitude string; rating Rating; url string; categories Categories; end record Rating averageRating float; totalRatings int; totalReviews int; end record Categories category Category; end record Category id string; egl_value string?; end
You want to analyze these records and their relationships. For example, you want to create a diagram to document the structure of the data. Or maybe you want to create corresponding data classes in Kotlin.
The first step is the same, you parse the code and gather the info about records. To build a diagram you can take advantage of PlantUML, a library that can generated diagrams based on a description (DSL) you gave.
So, to create a diagram from your EGL records all you need to do is:
- Parse the code using our EGL parser
- Walk the tree and get a list of records and their fields
- Create a file written in the PlantUML format and have PlantUML generate the image
How many lines of code do you think you need to write to achieve this?
val result = EGLKolasuParser().parse(code)
val result = EGLKolasuParser().parse(code)
val root = result.root as EglCompilationUnit
var classesDefinitions = ""
var classesLinks = ""
// let's collect the classes used in this file beforehand
val registeredRecords = root.eglRecords.map { it.name }
// build the strings representing class descriptions and their relationships
root.eglRecords.forEach {
classesDefinitions += "class ${it.name} {\n"
it.fields.forEach { field ->
classesDefinitions += "${getType(field.field.type)} ${field.field.name}\n"
if(registeredRecords.contains(getType(field.field.type)))
classesLinks += "${it.name} --> " +
"${registeredRecords.first { r -> r == getType(field.field.type)}}\n"
}
classesDefinitions += "}\n"
}
// let's assemble the PlantUML file
val source = """@startuml
|${classesDefinitions}
|
|${classesLinks}
|@enduml
""".trimMargin()
val reader = SourceStringReader(source)
val png: OutputStream = FileOutputStream("diagram.png")
reader.outputImage(png)
If you answered 30 lines of code, you were right! We have to collect the list of records used in the file beforehand, on line 7, because you could define the records in any order. So, if record Result uses record Rating you do not need to define Rating before defining Result.
At the end, you would get an image like this one.
Conclusion
Using an EGL parser unlocks the ability to understand, transform, and modernize your EGL applications. Whether you’re building tools for developers, automating documentation, or preparing for a migration, having structured access to EGL source code is a game-changer.
In this article, we explored how to extract REST services interfaces, and showed diagrams that can make this process actionable. If you are interested in learning more or trying it on your own codebase, get in touch with us. We’ll be happy to help you get started.

