
The code for this article is on GitHub: reverse-dictionary
In this article we are going to see how to use Word2Vec to create a reverse dictionary. We are going to use Word2Vec but the same results can be achieved using any word embeddings model. Do not worry if you do not know what any of this means, we are going to explain it. A reverse dictionary is simply a dictionary in which you input a definition and get back the word that matches that definition.
Natural Language Processing in Practice
Natural Language Processing is a great field: we found it very interesting and our clients need to use it in their applications. Up until now, we wrote a great explanatory article about it: Analyze and Understand Text: Guide to Natural Language Processing. Now we want to write more practical ones, to help you use it in your project. We think it is useful because it can be quite hard to get into it: you never know if a problem can be solved in one day, with a ready-to-use library, or you are going to need two years and a research team to get decent results. To put it simply: the hard part is not the technical side, but understanding how to apply it successfully.
That is even more true if a problem can be solved with machine learning. You need a bit of background to understand machine learning. And even if the solution works, you might still need weeks of tweaking weights and parameters to get it right.
So, in this article we are going to just see one technology and a simple application: a reverse dictionary. That is to say: how to get a word from its definition. It is a neat application and you cannot really get one with traditional means. That is there is no official reverse dictionary book that you can buy and you cannot code one with deterministic algorithms.
Representing Words in Machine Learning
The first step in a machine learning problem is understanding how to represent the data you have to work with. The most basic way is using one-hot encoding. With this method you:
- collect a list of of all possible values (e.g., 10 000 possible values)
- each possible value is represented with a vector, that has as many components as the possible values (e.g., each value is represented by a vector with 10 000 components)
- to represent each value, you assign 0 in all components except in one which will have 1 (i.e., each component is 0, except for one that is 1)
For example, applied to words this would means that:
- you have a vocabulary of 10 000 words
- each word is represented by a vector, the vector has 10 000 components
- the word
dogis represented by [1, 0, 0 …], the wordcatis represented by [0, 1, 0 …], etc.
This method is capable of representing all words, but it has a couple of big drawbacks:
- each vector is very sparse; most components are at 0
- the representation does not hold any semantic value; father and mother are close in meaning, but you would never see that using one-hot encoding
Word Embeddings to the Rescue
To overcome both these limitations word embeddings were invented. The key intuition of this type of word representation is that words with similar meaning have a similar representation. This allows to have much denser vectors. And to capture the meaning of words, at least in relation to other words. The second statement means simply that word embeddings do not really capture what father means, but its representation will be similar to that of mother.
This is a very powerful feature and allows all kinds of cool applications. For instance, this means that you can solve problem like this one:
what word is to father as mother is to daughter?
The first model for word embedding was Word2Vec (from Google), the one that we are going to use to build a reverse dictionary. This model revolutionized the field and inspired many other models such as FastText (from Facebook) or GloVe (Stanford). There are small differences between these model, for instance GloVe and Word2Vec train on words, while FastText trains on character n-grams. However the principles, applications and results are very similar.
How Word2Vec Works
The effectiveness of Word2Vec lies on a sort of trick: we are going to train a neural network for one task, but then we are going to use it for something else. This is not unique in Word2Vec, but one of the common approaches at your disposal in machine learning. Basically, we are going to train a neural network to produce a certain output, but then we are going to drop the output layer and just keep the weights of the hidden layer of neural network.
The training process works as usual: we give to the neural network both the input and the output expected for such input. This way the neural network can slowly learn how to generate the correct output.
This training task is to calculate the probability that a certain word appears in the context, given our input word. For example, if we have the word programmer, what is the probability that we are going to see the word computer close to it in a phrase?
Word2Vec Training Strategies
There are two typical strategies to train Word2Vec: CBOW and skip-gram, one the inverse of the other. With Continual Bag of Words (CBOW) we are going to give in input the context of a word and in output we should produce the word we care about. With skip-gram we are going to do the opposite: from a word we are going to predict the context in which it appears.
The term context at the most basic level simply means the words around the target word, like the words before and after it. However, you could also use context in a syntactic sense (e.g., the subject, if the target word is a verb). Here, we are going to concentrate on the simplest meaning of context.
For instance, imagine the phrase:
the gentle giant graciously spoke
With CBOW, we are going to give in input [gentle, graciously] to have in output giant. While with skip-gram we are going to give in input giant and put in output [gentle, graciously]. Training is done with individual words, so in practice, for CBOW:
- the first time, we are actually give in input
gentleexpectinggiantin output - the second time, we give
graciouslyexpectinggiantin output
For skip-gram we would invert input and output.
What We Get from the Neural Network
As we said, at the end of the training we will drop the output layer, because we do not really care to know what are the chances that a word will appear close to our input word. For example, we do not really care to know how likely it is that USA will appears close when we have the word flag in input. However, we are going to keep the weights of the hidden layer of our neural network and use it to represent the words. How that works?
It works because of the structure of our network. The input of our network is the one-hot encoding of a word. So, for instance dog is represented by [1, 0, 0 …]. During training, the output would be also a one-hot encoding of a word (e.g., using CBOW, for the phrase the dog barks, we could give dog in input and put barks in output). At the end, the output layer will have a series of probabilities. For example, given the input word cat, the output layer will have a probability that the word dog will appear close to cat, another probability that the word pet will appear close, and so on.
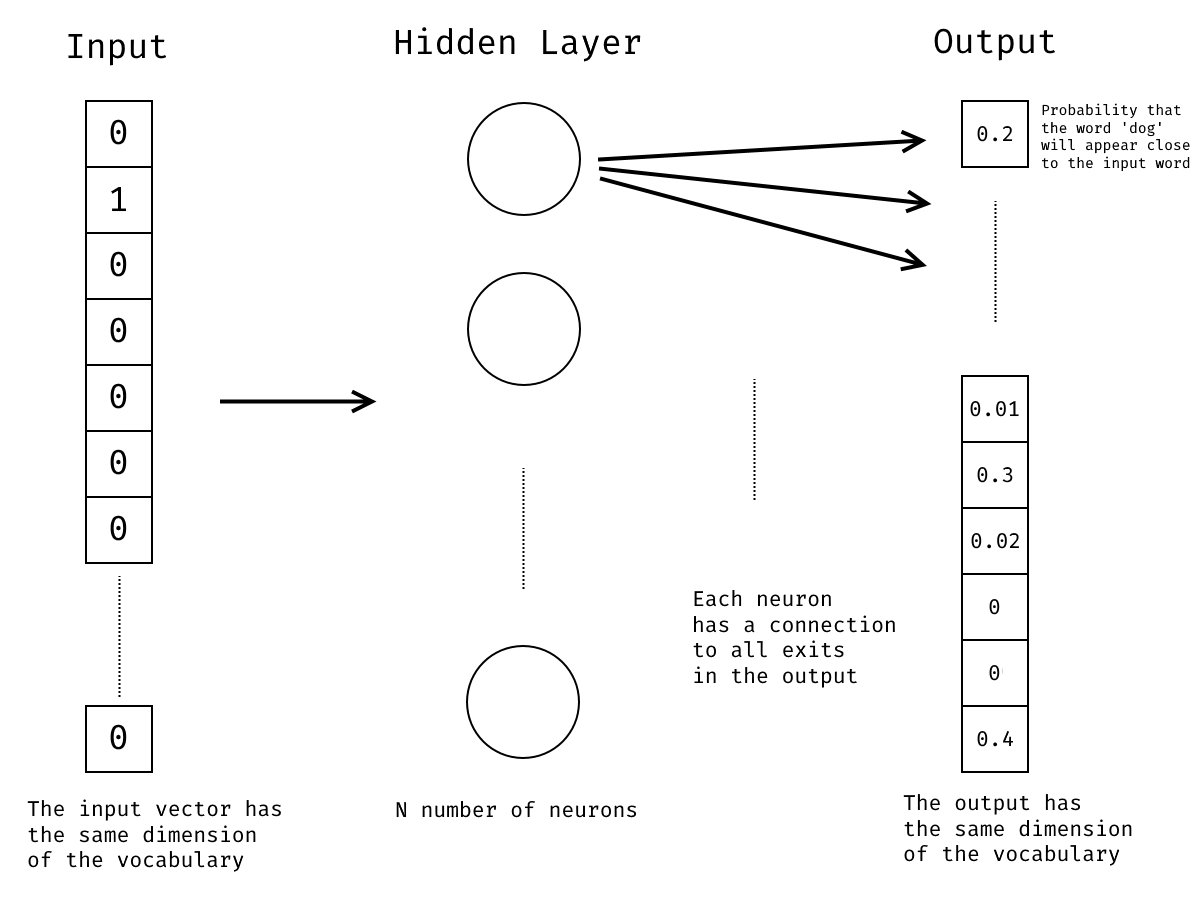
Each neuron has a weight for each word, so at the end of training we will have N neurons, each one with a weight for each word of the vocabulary. Also, remember that the input vector, representing a word, is all zeros, save for one place where is 1.
So, given the mathematical rules of matrix multiplication, if we multiply an input vector with the matrix of neurons, the 0s of the input vector will nullify most weights in the neurons, and what will remains will be one weight, in each neuron, linked to the input word. The series of non-null weights in each neuron will be the weights that represent the word in Word2Vec.
Words that have similar contexts will have similar output: so they will have similar probabilities to be found next to a specific word. In other words, dog and cat will produce similar outputs. Therefore they will also have similar weights. This is the reason because in Word2Vec words that are close in meaning are represented with vectors that are also close.
The intuition of Word2Vec is quite simple: similar words will appear in similar phrases. However, it is also quite effective. Provided, of course, that you have a large enough dataset for the training. We will deal with the issue later.
The Meaning in Word2Vec
Now that we know how Word2Vec works, we can look at how this would lead to a reverse dictionary. A reverse dictionary is a dictionary that finds the word from an input definition. So, ideally, if you input group of relatives the program should give you family.
Let’s start from the obvious: a natural use of word embeddings would be a dictionary of synonyms. That’s because, just like we said, with this system similar words have a similar representation. So, if you ask the system to find a word close to the input one, it would find a word with a similar meaning. For example, if you have in input happiness you would expect to get joy.
From this fact you might think that also doing the opposite is possible: to find antonyms, words with the opposite meaning of the input word. Unfortunately this is not possible directly, because the vector representing the words cannot capture so precisely a relation between words. Basically, it is not true that the vector for the word sad is in the mirror position of the one for happy.
However, we can give in input to the system:
- a pair of words that are in the desired relationship
- a third word
This in order to get an unknown world that has the same relationship to the third word as the words in the given pair. For instance, we can solve problem like this one:
what word is to father as mother is to daughter?
In this example, the pair is mother and daughter, while the third word is father.
The system is able to solve this riddle, so to find the word son, because it can use the relation between mother and daughter to find the word that is similarly related to father. This is simply due to vector mathematics.
Why it Works?
Look at the following simplified representation of the word vectors to understand why it works.
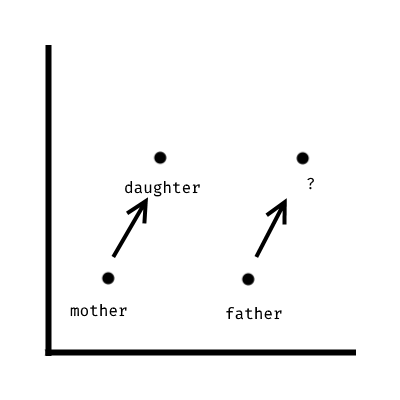
The system can find the word indicated by ?, simply because it can add from the vector for father the difference between the two given word vectors (mother and daughter). The system does capture relationship between word, but it does not capture their relationship in a way that is easily understandable. Put in other way: the position of the vector is meaningful, but it is meaning it is not defined in an absolute way (e.g., the opposite of), only in a relative one (e.g., a word that looks like A minus B).
This also explains why you cannot find antonyms directly: in the Word2Vec representation there is no mathematical operation that can be used to describe this relation.
How the Reverse Dictionary Works
Now that you understand exactly the power of word vectors, you can understand how you can use them to create a reverse dictionary. Basically, we are going to use them to find a word that is similar to the combination of input words, that is to say the definition. This would work because the system uses vector mathematics to find the word that is closer to the set of words given as input.
For example, if you give in input group of relatives it should find family. We are also able to use negated words in definition to help identify a word. For example, group of -relatives resolves to organization. We will see the precise meaning of negating a word later.
The Data for Our Word2Vec Model
Now that the theory is all clear, we can look at the code and build this thing.
The first step would be building the dictionary. This would not be hard per se, however it can be long to do it. More importantly, the more content we can use the better, and for the average user it is not easy to download and store large amount of data. The dump of the English Wikipedia alone, when extracted, can take more than 50 GB (only the text). And the Common Crawl (crawled pages freely available) data can take petabytes of storage.
For practical reasons it is better to use the pre-trained model shared by Google and based on Google News data: GoogleNews-vectors-negative300.bin.gz. If you search for this file you can find it in many places. Previously the official source was on a Google Code project, but now the best source seems to be on Google Drive. It is 1.6GB compressed and you do not have to uncompress it.
Once we have downloaded the data, we can put it in the directory models under our project. There are many libraries for Word2Vec, so we could use many languages, but we opt for Python, given its popularity in machine learning. We are going to use the Word2Vec implementation of the library gensim, given that is the most optimized. For the web interface we are going to use Flask.
Loading the Data
To start we need to load the Word2Vec in memory with 3 simple lines.
model = KeyedVectors.load_word2vec_format("./models/GoogleNews-vectors-negative300.bin.gz", binary=True)
model.init_sims(replace=True) #
model.syn0norm = model.syn0 # prevent recalc of normed vectors
The first line is the only one really necessary to load the data. The other two lines are needed to do some preliminary calculations at the beginning, so that there is no need to do them later, for each request.
However, these 3 lines can take 2-3 minutes to execute on your average computer (yes, with SSD). You have to wait this time only once, at the beginning, so it is not catastrophic, but it is also not ideal. The alternative is to make some calculations and optimization once and for all, then we save them and at each startup we load them from disk.
We add this function to create an optimized version of our data.
def generate_optimized_version():
model = KeyedVectors.load_word2vec_format("./models/GoogleNews-vectors-negative300.bin.gz", binary=True)
model.init_sims(replace=True)
model.save('./models/GoogleNews-vectors-gensim-normed.bin')
And in the main function we use this code to load the Word2Vec data each time.
optimized_file = Path('./models/GoogleNews-vectors-gensim-normed.bin')
if optimized_file.is_file():
model = KeyedVectors.load("./models/GoogleNews-vectors-gensim-normed.bin",mmap='r')
else:
generate_optimized_version()
# keep everything ready
model.syn0norm = model.syn0 # prevent recalc of normed vectors
This shorten the load time from a couple of minutes to a few seconds.
Cleaning the Dictionary
There is still one thing that we have to do: cleaning the data. On one hand the Google News model is great, it has been generated by a very large dataset, so it is quite accurate. It allows us to get much better results that the one we would get building our own model. However, since it is based on news, it also contains a lot of misspellings and, more importantly, model for entities that we do not need.
In other words it does not contain just individual words, but also stuff like the names of building and institutions that are mentioned in the news. And since we want to build a reverse dictionary this could hinder us. What could happen is that, for example, if we give in input a definition like a tragic event the system could find that the most similar item for that group of words is a place where a tragic event happened. And we do not want that.
So, we have to filter all the items outputted by our model to ensure that only words commonly used and that you can actually find in a dictionary are shown to the user. Our list of such words comes from SCOWL (Spell Checker Oriented Word Lists). Using a tool in the linked website we created a custom dictionary and put it in our models folder.
# read dictionary words
dict_words = []
f = open("./models/words.txt", "r")
for line in f:
dict_words.append(line.strip())
f.close()
# remove copyright notice
dict_words = dict_words[44:]
Now we can easily loads our list of words to which compare the items returned by our Word2Vec system.
The Reverse Dictionary
The code for the reverse dictionary functionality is very simple.
def find_words(definition, negative_definition):
positive_words = determine_words(definition)
negative_words = determine_words(negative_definition)
similar_words = [i[0] for i in model.most_similar(positive=positive_words, negative=negative_words, topn=30)]
words = []
for word in similar_words:
if (word in dict_words):
words.append(word)
if (len(words) > 20):
words = words[0:20]
return words
From the user we receive in input positive words that describe the needed word. We also receive negative words, mathematically these are words whose vector must be subtracted from the other words.
It is harder to grasp the meaning of this operation: it is not as if we were including the opposite of the word. Rather we are saying that we want to remove the meaning of the negative word. For example, imagine that the definition is group of -relatives, with relatives the negated word and group, of the positive words. We are saying that we want the word which has the closest meaning to the one identified by the set of group and of, but from that meaning we remove any sense that is specifically added by relatives.
This happens on line 5, where we call the method that found the top 30 words most similar to the meaning identified by the combination of positive and meaning words. The function returns the word and the associated score, since we are only interested in the word itself, we ignore the score.
The rest of the code is easy to understand. From the words returned previously, we select only the ones that are real words, rather than places or events. We do that by comparing the words from the database of dictionary words we loaded earlier. We also reduce the list to up to 20 elements.
Cleaning Words from the Input
In the find_words method, on lines 2 and 3, we call a function determine words. This function basically generates a list of words from the input string. If a word is prepended by the minus sign is considered a negative word.
def determine_words(definition):
possible_words = definition.split()
for i in range(len(possible_words) - 1, -1, -1):
if possible_words[i] not in model.vocab:
del possible_words[i]
possible_expressions = []
for w in [possible_words[i:i+3] for i in range(len(possible_words)-3+1)]:
possible_expressions.append('_'.join(w))
ex_to_remove = []
for i in range(len(possible_expressions)):
if possible_expressions[i] in model.vocab:
ex_to_remove.append(i)
words_to_remove = []
for i in ex_to_remove:
words_to_remove += [i, i+1, i+2]
words_to_remove = sorted(set(words_to_remove))
words = [possible_expressions[i] for i in ex_to_remove]
for i in range(len(possible_words)):
if i not in words_to_remove:
words.append(possible_words[i])
return words
This function starts with generating a list of words, but then it also adds expressions. That is because the Google News model has also vector representations of phrases in addition to that of simple words. We attempt to find expressions simply by putting together 3-gram words (i.e., a sliding set of 3 words). If an expression is found in the Google News model (line 14) we have to add the expression as a whole and remove the individual words.
The Web App
For easy of use, we create a simple Flask app: a basic web interface to let the user provide a definition and read the list of words.
def create_app():
app = Flask(__name__)
return app
app = create_app()
@app.route('/', methods=['GET', 'POST'])
def index():
if request.method == 'POST':
words = request.form['definition'].split()
negative_words = ''
positive_words = ''
for i in range(len(words)):
if(words[i][0] == '-'):
negative_words += words[i][1:] + ' '
else:
positive_words += words[i] + ' '
return jsonify(find_words(positive_words, negative_words))
else:
return render_template('index.html')
The app answers to the root route: it shows the page with the form to provide the definition, and returns the list of corresponding words when it receives a definition. Thanks to Flask, we can create it in a few lines.
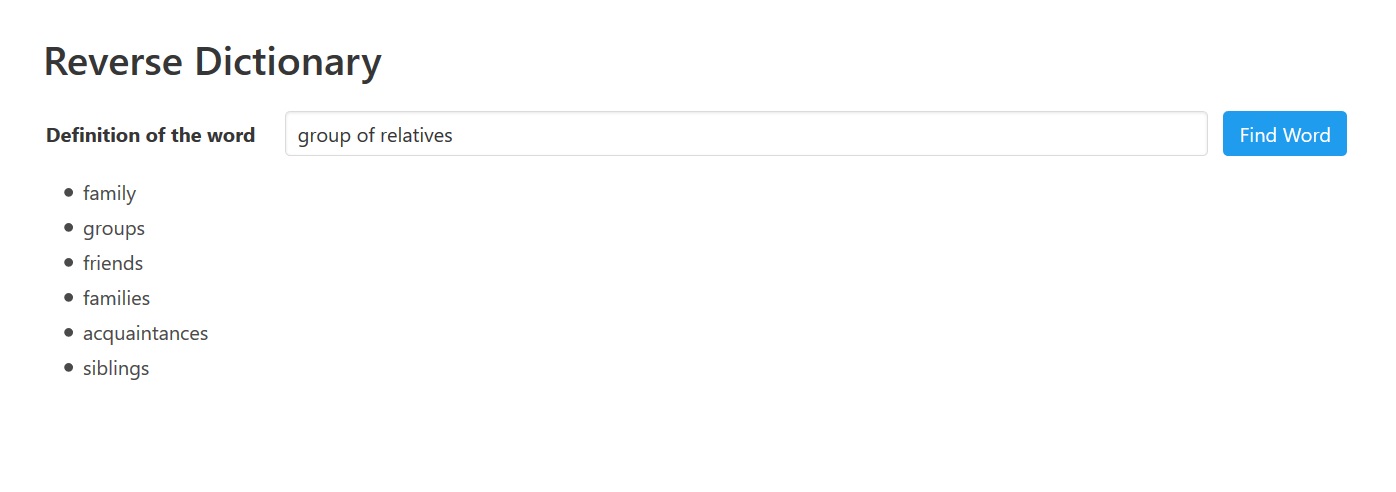
How well does it work? Well this approach works quite well for descriptive definitions, i.e., if we use a definition that describes the word we are looking for. By that we mean that you will probably find the correct word in the list returned by the app. It might not be the top word, but it should be there. It does not work that well for logical definitions, e.g., female spouse. So, it is certainly not a perfect solution, but it works quite well for something so simple.
Summary
In this article we created an effective reverse dictionary in a few lines, thanks to the power of Word2Vec and ready-to-use libraries. A pretty good result for a small tutorial. But you should remember something when it comes to machine learning: the success of your app does not depend on your code alone. As for many machine learning applications, the success depends greatly on the data you have. Both in the training data you use and how you feed the data to the program.
For instance, we left out a few trials and errors for to the choice of the dataset. We already expected to get some problems with the Google News dataset, because we knew it contained news events. So we tried to build our own dataset based on the English Wikipedia. And we failed quite miserably: the results were worse than the ones we got using the Google News dataset. Part of the issue was that the data was smaller, but the real problem was that we are less competent than the original Google engineers. Choosing the right parameters for training requires a sort of black magic that you can learn only with a lot of experience. In the end the best solution for us was using the Google News dataset and filter the output to eliminate unwanted results for our application. A bit humbling, but something useful to remember.
")
