")
There is one thing that studying English and French (and failing at German) taught me about coding — especially when dealing with unfamiliar codebases.
I’ve learned through firsthand experience that you can’t truly learn a language by relying on books or your high school English teacher. Maybe you’ve gone abroad and enthusiastically wished someone good luck by translating literally, “break a leg,” only to be met with blank stares and a bemused “Oh, les Américains…”. In Italy, for example, the equivalent phrase is “in bocca al lupo”—literally, “into the wolf’s mouth.” An Italian might respond “crepi!” (may it die!), which would sound just as strange to an English speaker. If you’re unfamiliar with idioms, communications can be difficult and confusing.
Ok, but what idioms have to do with understanding code?
Idioms, are shortcuts to communicate something complex, very quickly. In code, idioms provide concise, elegant ways to express ideas, transforming complex instructions into something instantly recognizable to fellow developers.
In this article, we’ll explore how to leverage idioms to define idiomatic migrations. We’ll learn:
- The science behind idioms;
- What are code idioms useful for;
- How to identify idioms that are specific to a codebase;
- How to used to translate that meaning—not just the literal syntax—into another language or platform.
This is the difference between wishing someone break a leg in Italian as “rompiti una gamba” (which would just sound like a threat) and saying “in bocca al lupo” like a true Italian. And, of course, if you avoid asking for pineapple on your pizza and gesture with your hands a little, people might even mistake you for a native.
For the impatient, this is a video given a concrete idea of how idioms look like:
The science behind idioms
Idioms are more than just handy shortcuts—they tap into how our brains work. In The Programmer’s Brain by Felienne Hermans, the author builds on De Groot’s theory to explain why idioms are so powerful. Here’s the gist: your working memory can juggle only 5 to 9 things at once. That’s it. To do more, you need to pack more into each slot, and this trick is referred to as chunking—grouping a sequence of smaller elements into a single, meaningful unit.
Think about it this way: someone learning a programming language for the first time might need all their focus to keep track of the pieces of a for-loop. They’re thinking about initialization, the loop condition, the increment operation, and the loop body—juggling all these elements takes effort. Now imagine an experienced developer: they don’t think about those details anymore. They just see the for-loop and instantly think, “iterate over the list.”
Not only does this make writing code easier, but it also streamlines communication with others. An experienced developer doesn’t need to explain every detail of a loop—they can say, “iterate over the list,” and the other person understands. What once required a lot of mental energy now takes almost none, leaving room to focus on higher-level problems.
Idioms compress complexity into a single, digestible concept. This doesn’t just save effort—it enables you to operate at a higher level of abstraction. By expanding your mental vocabulary with idioms, you reduce cognitive load, write cleaner code, and collaborate more effectively.
Not a small feat, eh?
What are code idioms useful for
Code idioms are the glue that holds consistency and clarity in a codebase. They’re more than just shortcuts—they also reflect the intent of the developer, showing not just what the code does, but often why.
Every community of developers—whether it’s the broader users of a programming language, the team at a specific company, or even contributors to a single codebase—tends to develop its own set of idioms. These are the “unwritten rules” of how things are done, shaping the style and logic of the code. And the more consistent these idioms are, the better. In fact, “boring” and predictable code is exactly what you want: excitement might be great in life, but not so much in code.
At Strumenta, code idioms are central to two areas of our work:
- When Designing DSLs
As we develop Domain-Specific Languages (DSLs), we often notice that users express themselves using certain recurring structures—essentially, their own idioms. This can indicate a missing abstraction, something that could make the DSL more expressive or natural. This is an important part of refining a DSL, and we may want to explore in depth in a future article.
- When Dealing with Legacy Code
Code idioms in legacy codebases are essential for two main reasons: helping developers familiarize themselves with unfamiliar systems and enabling high-quality migrations to modern languages or platforms. This is the use case we want to investigate further in this section.
How Idioms learn with legacy code
When we have a legacy codebase to deal with, there are essentially two situations we find ourselves in:
- If we decide to keep it as is, we need to help people navigate it and learn about it
- If we decide it is time to move to another language, we need to translate the knowledge trapped in this codebase into another language
In both situations, Idioms can help us. Let’s see how.
Using Code Idioms to Familiarize with a Legacy Codebase
Imagine joining a team tasked with maintaining a legacy system, perhaps one developed over decades, long before you arrived. The codebase might span millions of lines of code, written by different developers using various styles, reflecting the practices of their time. Getting up to speed with it will not be an easy task.
Here’s where code idioms come in. By identifying idioms across the codebase, we provide an interpretation key—a way to understand the underlying recurring structures quickly. Automating this process is crucial because manual exploration of such a vast and complex system would be impractical. When idioms are identified and presented to the developer, they offer an efficient way to grasp the logic and conventions of the system, making onboarding and ongoing work significantly easier.
In practice, we can:
- Beforehand we can build a catalog of common idioms, providing for each one a description, an explanation of its meaning, and a list of examples.
- When navigating existing code we can show inline if they are instances of those idioms and if so let the user navigate to the definition of the idiom. We can do that through a dedicated code navigation tool or by creating a plugin for the IDE of choice.
Using Code Idioms to Avoiding Frankenstein Code During Migrations
Idioms also play a critical role in migrations. Without recognizing and leveraging idioms, a migration becomes a low-level translation exercise: replicating the original code, construct by construct, in the target language. This approach often leads to what some call “Frankenstein code,” where the target language is filled with patterns and constructs that clearly don’t belong.
Take, for example, the term JOBOL—a nickname for COBOL code translated into Java. While the code is technically Java, it just means that the Java compiler would be willing to accept it. It does not mean that a self-respecting Java developer would want to touch. Each line reeks of COBOL from three miles away, with every line screaming that it was written by someone who has never heard about the practices of the Java community.
By identifying idioms, we can find a solution to this problem. Instead of copying the original structure directly, we pause to understand the intent behind the idiom. What question was the idiom answering? What purpose was it fulfilling? Then, we re-express that purpose in the target language in the most idiomatic way possible.
For instance, imagine a complex structure in the original code that represents iterating over a list. In the target language, we wouldn’t replicate every low-level detail of this structure. Instead, we’d translate the intent—iterating over a collection—into the cleanest, most idiomatic construct available in the target language. The result is not just functional code but code that feels natural and at home in its new environment.
Does this sound very abstract? Let’s see an example then.
Suppose you have this COBOL code. It searches over a record in a sequential file:
SET NOT-FOUND TO TRUE. PERFORM UNTIL EOF-FLAG = "Y" OR NOT-FOUND = FALSE READ FILE-IN INTO RECORD-AREA AT END MOVE "Y" TO EOF-FLAG NOT AT END IF RECORD-ID = SEARCH-ID MOVE FALSE TO NOT-FOUND END-IF. END-PERFORM.
If we can recognize this idiom we can define the corresponding idiom in Java, and translate each instance of the COBOL idiom in an instance of the corresponding Java idiom. For example, in this way:
List<Record> records = readRecordsFromFile(“file.txt”);
Optional<Record> foundRecord = records.stream()
.filter(record -> record.getId().equals(searchId))
.findFirst();
if (foundRecord.isPresent()) {
System.out.println("Record found: " + foundRecord.get());
} else {
System.out.println("Record not found.");
}
If we instead had translated the code a-la-JOBOL, the result may look like this:
boolean notFound = true;
boolean eofFlag = false;
RandomAccessFile file = new RandomAccessFile("file.dat", "r");
while (!eofFlag && notFound) {
byte[] recordBytes = new byte[50]; // Assuming each record is exactly 50 bytes
int bytesRead = file.read(recordBytes);
if (bytesRead == -1) {
eofFlag = true;
} else {
String record = new String(recordBytes);
String recordId = record.substring(0, 10).trim(); // Assuming ID is in the first 10 characters
if (recordId.equals(searchId)) {
notFound = false;
}
}
}
file.close();
Which one would you want to maintain?
Recognizing idioms (or mining code idioms)
If you want to use idioms effectively in a migration—or any coding task—you need to start by building a catalog of idioms. Think of it as your pocket phrasebook.
Building this catalog is the prerequisite. Once you’ve identified the idioms, you can look for instances of them in the codebase, understand their purpose, and ensure they’re translated idiomatically into the target environment during migration. But how do you go about finding these idioms?
We can ask humans or machines to find them. Let’s see how these approaches compare.
Human-Centric Approaches to Finding Idioms
If we want to use humans to build the catalog of idioms our first choice may be an expert in the language under consideration (e.g., COBOL). So let’s start with that and then see what it looks like to use someone who is not an expert instead.
Asking an Expert in the Language to Find Idioms
The most obvious place to start is by asking a developer familiar with the codebase or language. This is like asking a native speaker to teach you idioms in their language. They might rattle off a few classics—the “break a leg” or “in bocca al lupo” of the codebase.
But there is one problem: just as native speakers don’t consciously think about every idiom they use, expert developers can be “blind” to idioms in the code they work with every day.
Idioms tend to surface naturally in context. So, a developer reviewing the codebase with you might point them out as they encounter them, but they’re unlikely to remember everything in one sitting. So just asking an expert for idioms is a good starting point but won’t give you a comprehensive catalog.
Asking a Fresh Pair of Eyes to Find Idioms
Here’s where things get interesting: someone who’s not familiar with the codebase—or even with the language—can conter-intuitively be a good idea.
For example, imagine a junior developer learning Java for the first time. They might look at the code and say, “Why do all these methods start with get or set? Why does every file operation involve a try block?” These questions can reveal idioms that a seasoned Java developer takes for granted.
This outsider perspective can be particularly useful for spotting surprising or non-obvious idioms.
We can turn these things he noticed into questions and get the answers from an expert.
Machine Centric Approaches to Finding Idioms
Human intuition is invaluable, but it has limits and costs—especially with large or complex codebases. This is where technology steps in.
Mining Code Idioms Algorithmically
The fundamental idea is simple: look for constructs—statements, expressions, methods, etc.—that frequently appear together or in specific contexts more often than expected.
For example:
• Calls to close() are far more likely to occur within a finally block than in other contexts.
• Methods prefixed with set typically have one parameter and return void, which is statistically significant compared to the general occurrence of single-parameter methods.
By analyzing Abstract Syntax Trees (ASTs) or control flow graphs, one can detect recurring combinations and flag them as potential idioms.
This process, however, isn’t trivial. While tools for frequent subtree mining, graph-based analysis, or statistical correlation can help, distinguishing meaningful idioms from noise is a major challenge. You might end up with thousands of irrelevant patterns unless you carefully filter and validate the results.
Scientific Foundations
If you are interested in this topic, there is some material you can dive into. The term “mining code idioms” was introduced by Allamanis et al. in their paper Mining Idioms from Source Code (2014). This work pioneered a method for extracting idioms by analyzing large code repositories, aiming to capture recurring syntactic fragments that reflect a community’s coding practices. Their probabilistic model was specifically designed to extract idioms that convey meaning and intent beyond surface-level patterns.
Other research has contributed to this field, exploring different aspects of code idioms:
• Kim et al. (Automatically Inferring Code Idioms, 2018) focused on identifying idioms localized to specific domains or projects, recognizing that idioms often reflect contextual best practices.
• Allamanis and Sutton (Mining Idioms for Code Comprehension and Synthesis, 2013) demonstrated how idioms could aid code comprehension and automated synthesis, reinforcing the idea that idioms carry significant semantic value.
• Nguyen et al. (Graph-Based Mining of Frequently-Used Code Idioms, 2012) emphasized the importance of graph-based analysis to uncover idioms tied to control flow and structural relationships, particularly in large-scale systems.
These studies highlight that idioms are more than recurring patterns—they encapsulate meaning, intent, and best practices critical for understanding and working with a codebase.
The Challenges of Idiom Mining
While tools for frequent subtree mining, graph-based analysis, or statistical correlation can help, the process is far from straightforward.
- Noise and Irrelevance: Mining tools often generate thousands of patterns, many of which are statistically significant but semantically meaningless. Filtering out this noise requires careful validation and domain-specific heuristics.
- Semantic Validation: Identifying patterns that are not just frequent but also meaningful to developers requires incorporating type information, control flow, and developer intent.
- Scalability: Analyzing large codebases efficiently demands algorithms that can handle the complexity of real-world systems while maintaining performance.
The Temptation of LLMs
We have started by looking at algorithmic approaches, but in these times and days one start to wonder, why going through the effort of designing or implementing algorithms when an LLM can give me the solution?
It’s an appealing idea—low-cost, low-effort.
We tried this approach. And the results were less than impressive.
The problem is that LLMs struggle to differentiate between design patterns, code clones, and code idioms—subtle distinctions that require deep understanding. Additionally, the lack of extensive literature on idiom mining makes it harder for LLMs to provide accurate answers. While LLMs can occasionally generate interesting insights, they’re unlikely to offer a reliable or systematic solution to idiom discovery.
That said, if you don’t have the resources to develop your own algorithms, experimenting with LLMs might still be worth a shot. Just manage your expectations—they’re no substitute for a robust, purpose-built tool.
FactsVector: the algorithm we developed for mining code idioms
At Strumenta, we designed an algorithm called FactsVector to identify code idioms in any codebase, regardless of the programming language. The magic lies in how we analyze Abstract Syntax Trees (ASTs) built using our StarLasu approach, which provides a consistent and unified API for analyzing code constructs. This flexibility is what allows the algorithm to be language-agnostic
Here’s how FactsVector works:
- The first thing we do is gather a list of “facts” about each AST node type. These facts are simple yes-or-no statements that can be checked for any given node. For example, if we’re analyzing a method declaration, here are some facts we might look at:
- The method name starts with get.
- The method name starts with set.
- The method name starts with IS.
- The method name is equals.
- The method name is hashCode.
- The method name is toString.
- The method return type is void.
- The method return type is int.
- The method has exactly one parameter.
- The method is marked as static.
- For each node, we systematically verify these facts and record the results as a series of 0s and 1s. Each fact represents one dimension in a multi-dimensional space, and the collection of these values forms a vector. The more facts we consider, the more dimensions our vector space will have.
If we had just the facts we listed above, here’s what this looks like:
- A method named getName() with a return type of String would produce a vector like [1, 0, 0, 0, 0, 0, 0, 0, 0, 0] (indicating it starts with GET but doesn’t match any of the other facts above).
- A method named hashCode() would result in [0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
- The different vectors representing the nodes are grouped into clusters based on shared characteristics. This is achieved using the Birch clustering algorithm, which scales sufficiently well for our use-cases, potentially covering tens of millions of nodes. Each cluster represents a group of nodes that share certain characteristics.
- After forming clusters, the algorithm refines its understanding of the codebase through an iterative process. Clusters are treated as higher-level pseudo-types, which provide a more abstract representation of the nodes they contain. Using these new types, the algorithm generates updated facts about the codebase, recomputes characteristics, and re-clusters nodes. This iterative refinement allows the algorithm to uncover deeper and more nuanced patterns.
- Up to this point, the algorithm has focused on identifying clusters of nodes with shared characteristics, considering the node itself and the subtree it contains. The next step is to examine idiomatic sequences of nodes, which is crucial for identifying recurring patterns in the order of execution or declaration.
For example, we analyze sequences of nodes across the codebase to identify when specific combinations occur significantly more often than expected. If a local variable declaration (e.g., a local variable of type int named i) frequently precedes a while statement in a specific context, we infer a correlation between these constructs. The algorithm identifies such relationships by calculating the frequency of sequences and comparing them to their general distribution.
This step is particularly valuable for uncovering idiomatic sequences of statements, which represent common workflows or patterns in a codebase.
We tested it so far with codebases of hundreds of thousands of lines, and results are produced within minutes. We are confident that it can be scaled to work on codebases that are tens of millions of lines code with reasonable performance. We are working on refining this algorithms, to identify more kinds of facts and better filtering meaningful idioms from the ones constituting noide. While I am sure this will keep us busy for years to come, the results we got make us happy.
How Do We Use Code Idioms to Improve Migrations
If you want to learn how we design transpilers you may be interested in our article How to Write a Transpiler.
But here it comes a summary.
The Overall Design of Our Transpilers
Our transpilers follow a three-step process:
Step 1 – Parsing the Source Code
We start by parsing the original code to create a detailed Abstract Syntax Tree (AST). This AST captures not just the structure of the code but also all the information it contains, such as types, relationships, and dependencies. For example, in a migration from RPG to Java, we would parse the RPG code to produce an RPG AST.
Step 2 – Transforming the AST
The core of the migration happens here. We transform the original AST into a target AST that represents the same program but in the target language. For example, we would transform an RPG AST into a Java AST.
Step 3 – Generating Target Code
Finally, we use the target AST to generate code in the target language, such as Java files that can be saved, compiled, and maintained.
Transforming the AST: Construct-to-Construct vs. Idiom-to-Idiom
The transformation step is the heart of our transpilers. It’s where we decide how to map elements from the source AST to the target AST. This transformation can follow two approaches:
- Construct-to-Construct Transformation
This is the more straightforward method. Each construct in the source AST is translated to its equivalent in the target AST. For example, a for statement in RPG might translate to a for statement in Java. These transformations are rule-based and tend to focus on individual constructs in isolation, with some consideration for their immediate context.
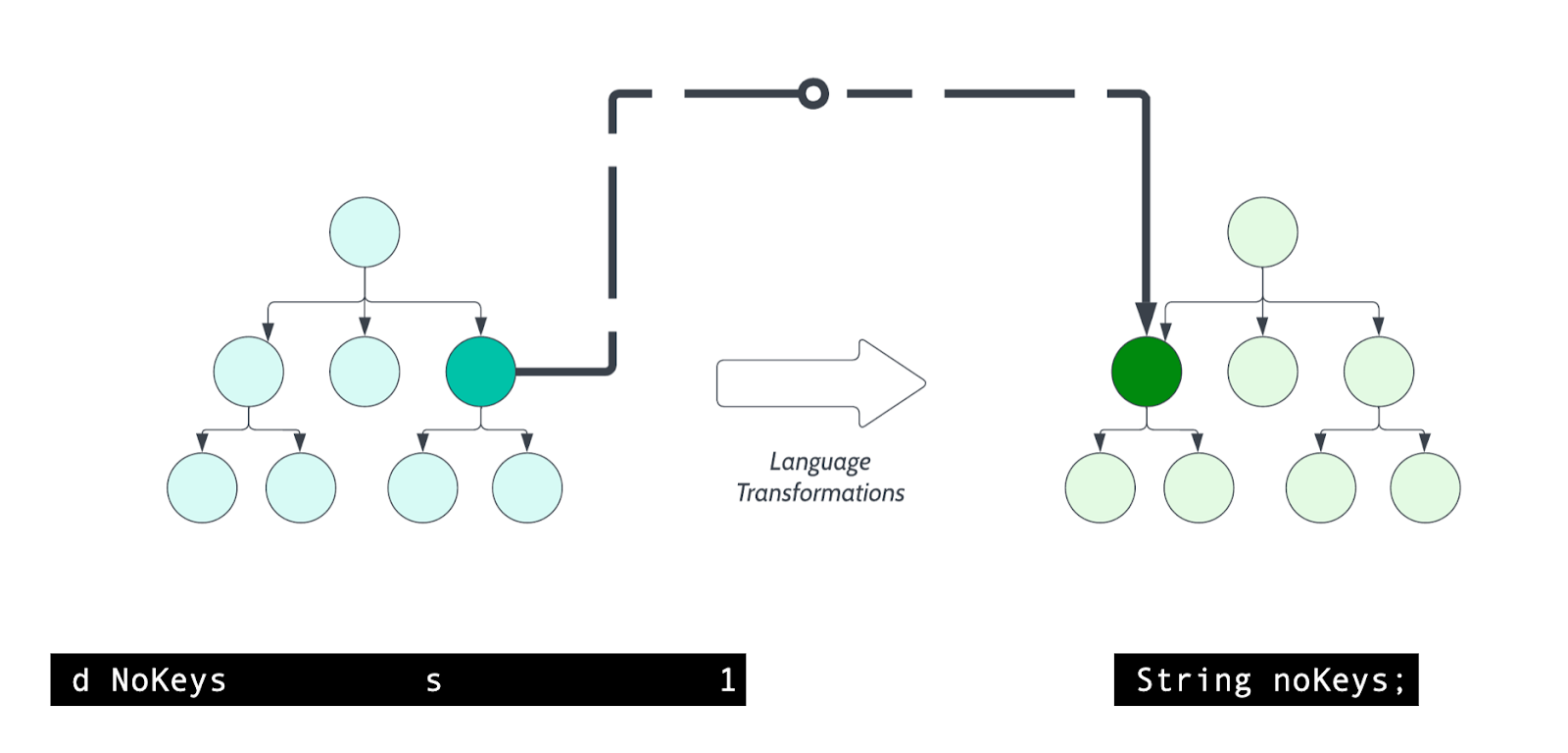
- Idiom-to-Idiom Transformation
This is a more sophisticated approach. Instead of translating individual constructs, we recognize idioms in the source AST and map them to corresponding idioms in the target language.
For instance, consider a pattern in RPG that involves iterating over a collection using a complex combination of loops and conditional checks. Instead of translating these elements piece by piece, we recognize the idiom for “iterating over a collection” and translate it directly into a Java for-each loop.
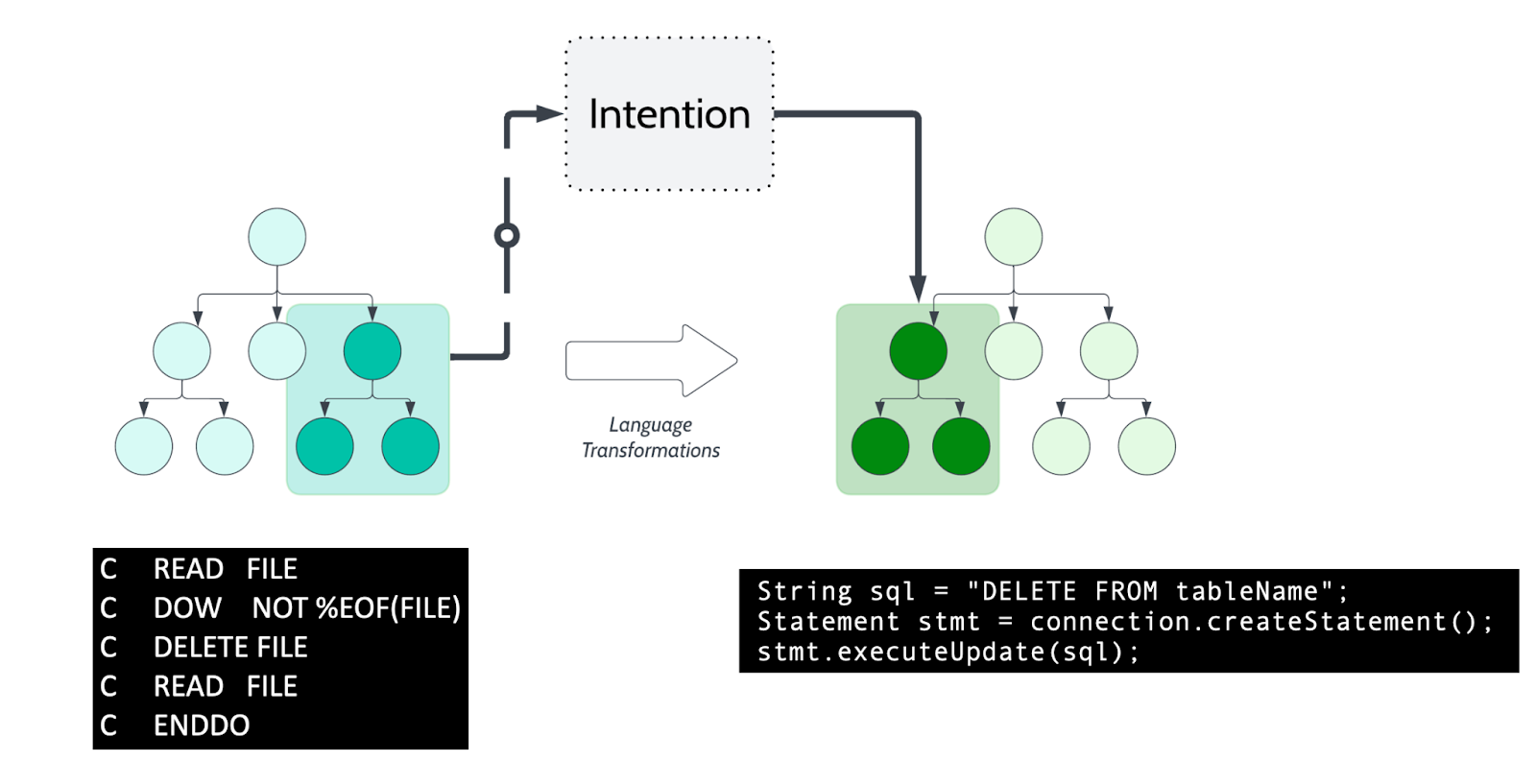
Why Combining the Two Approaches?
We combine construct-to-construct and idiom-to-idiom transformations to achieve an optimal balance between coverage and idiomaticity:
- Idioms First: During the AST transformation, we first check if an element is part of a recognized idiom. If it is, we apply an idiom-to-idiom transformation.
- Fallback to Constructs: For elements not covered by idioms, we fall back to construct-to-construct transformations, ensuring that the entire codebase is translated.
This hybrid approach allows us to produce idiomatic target code whenever possible while still maintaining broad coverage for all constructs in the source code.
How does it work in practice?
During the transformation process, we examine each element in the source AST and ask:
- Is This Part of a Recognized Idiom?
If so, the entire idiom is treated as a single input. A transformation is applied to produce one or more nodes in the target AST, representing the idiom’s intent in the target language.
For instance, consider an RPG idiom for reading a file line by line:
READ file; DOUNTIL EOF; processRecord(); ENDDO;
Translating this construct directly might result in verbose and unidiomatic Java code. Instead, recognizing the idiom allows us to transform it into a clean, idiomatic Java implementation using a BufferedReader:
try (BufferedReader reader = new BufferedReader(new FileReader("file.txt"))) {
String line;
while ((line = reader.readLine()) != null) {
processRecord(line);
}
}
- If Not, Apply Construct-Based Transformation
For constructs not part of a recognized idiom, we apply a transformation rule specific to that construct type. These rules can be context-sensitive, considering the construct’s surrounding elements. For example, the transformation of a statement might depend on whether it appears within a method or as part of a field declaration.
One big plus of this approach is that it makes tracking progress much easier—something that’s often tricky in software projects, especially migrations. We start by identifying a set of idioms, which can range from 20 to 100 or more in larger, more complex codebases. For each idiom, we can see whether we’ve defined a transformation, how many instances it covers, and how much of the codebase it represents. The same goes for constructs. This doesn’t mean everything will always move as quickly as we’d like—migrations can be challenging—but at least we always know where we stand. With objective measures, we can make better predictions about when we’ll hit certain milestones or complete the migration, taking most of the guesswork out of the process.
Summary
Code migrations are tough—there’s no way around it. Moving code from one language to another isn’t just a trivial mechanical process; it’s about interpreting the intent behind the original solution. Every codebase tells a story, and idioms are what make that story readable and expressive. Without them, the migrated code feels unnatural, like something that doesn’t quite belong.
At Strumenta, we’ve found that focusing on idioms makes all the difference. By combining idiom-to-idiom transformations (for elegance) with construct-based rules (for comprehensive coverage), we strike a practical balance that gets results. Our approach has worked well for us, and we think it’s worth exploring if you’re tackling a migration yourself.
And by the way, if this sounds like the kind of approach you’d rather not reinvent on your own, we’re always happy to help through our migration services. Whether you want advice or a complete solution, we’re here to make sure your migration is done right.