")
Today, we are discussing migration project challenges. Instead of discussing just the theory, we’ll take a real piece of software written in Java and convert it to Python.
Now, at Strumenta, we typically work on legacy migration projects, involving applications built in older languages like RPG, Visual Basic, or various 4GLs. However, those applications are proprietary and we cannot tell you much about them. This is why we picked an example that was open-source (and something we actually needed to convert).
Sure, there are some differences with migrating a legacy application, but the principles remain the same. More on the differences below.
How does this migration compare to a typical legacy migration project?
Typically, legacy applications we want to migrate are ERPs or MRPs which contain proprietary business logic accumulated over decades, lack unit tests, and are riddled with code clones and massive functions.
In this article instead we will share insights from our migration of LionWeb-Java to LionWeb-Python, both implementations of the LionWeb specification—a library for language engineering and model processing.
| Typical Legacy Migration Project | LionWeb-Java to LionWeb-Python | |
| Size of the codebase | 1M-20M lines of code | 10K lines of code |
| Can we show the code? | No | Yes! |
| Presence of tests | No | Yes, but we will ignore them, to simulate their absence |
| Usage of libraries | Typically depending on the system library and internal library | Dependencies limited to Gson and some serialization libraries |
| Quality of the code | Low: code clones, dead code, god functions | High: code developed in the open, reviewed, refined |
| Migration Principles | Exactly the same | |
Where do we start?
For most projects, this process begins with a Migration Blueprint, during which we analyze the existing application, compute statistics, and define the target system in collaboration with the client. However, in this case, since we were both the authors of LionWebJava and the primary users of LionWebPython, this step was more informal. The main decision points were adopting modern Python practices, such as using pip for package management and type hints for type safety. Ok, we just replaced several workshops with a couple of sentences. Good.
But we also made an important decision: we will deliver the migrated code incrementally. In other words, we want to deliver a first group of files that can work independently and that the client can start validating or even use. Alternatively, we could deliver the entire codebase at once, but that’d be a bad idea.
Why? Because a full transpiler takes time to develop, leaving the client without intermediate deliverables for validation. So, in a real project, the client would be in the dark for quite a while, wondering if they’d made a good decision to trust the people they’d asked to build the transpiler. That’s not a great scenario.
Instead, we aim to provide an incremental migration plan where initial outputs can be reviewed early. In this way the client has something they can put their hands on and use to start providing feedback. That’s reassuring for them, but also for us, because no matter how deep the initial requirements discussion are, it is always wise to check we are aligned as frequently as possible.
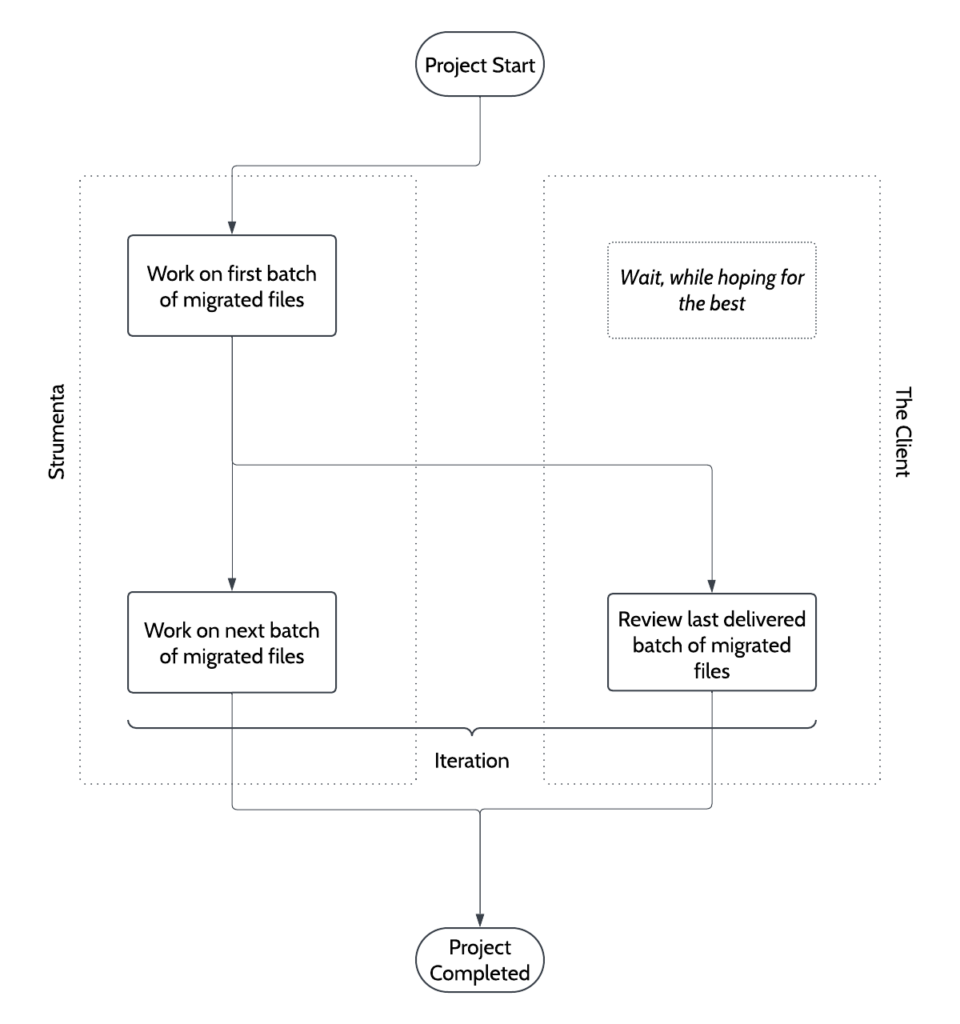
Defining a Migration Plan
Once we decided to proceed, the next critical task was defining the migration order of files. You can’t simply take files randomly because of interdependencies between them: a certain Python module will reference another Python module and if that module isn’t there the code will fail to run. Therefore, we needed to calculate dependencies between files and establish an optimal sequence for translation.
Dependency analysis requires parsing the code and resolving symbols:
- When encountering a method call, we must locate its definition.
- This requires understanding Java’s method resolution rules, including inheritance, overloading, and interfaces.
Let me illustrate this with this example:
This process can be complex, especially when dealing with inherited fields, generic types, method chaining, and lambdas.
Once we’ve done it, we get our migration plan, i.e., the order in which we should translate our Java files:
Our initial dependency graph showed:
- Some files (e.g., enums, interfaces) with no dependencies.
- Files that depend only on those fundamental files.
- A large set of files that is interdependent with each other, forming a cluster of 27 tightly coupled files.
Handling Clusters of Interdependent Files
When we encounter a cluster we can decide whether to translate it as a whole, or partially, using an appropriate technique that we’ll describe.
To make this decision we may want to consider the effort necessary to translate these files. Now, the effort is not determined by the size of the codebase. It depends instead on how many idioms and constructs we haven’t yet encountered in the project up to that moment. If, for example, we encounter a cluster of interfaces, and we’ve already created the rules to translate interfaces, there’ll be no new work for us to do, whether there are three or three hundred interfaces. So we measure the effort in terms of idioms and constructs not yet supported by our transpiler, and that we need to support to translate the cluster.
If the effort can fit into an iteration, then we don’t bother performing a partial translation of the cluster – we just translate it in its entirety. If instead the cluster requires a lot of work to be transpiled, then we move the dependency analysis to another level of granularity.
So far, when we said that a file was dependent on another file we considered all references appearing anywhere in the file. However there are references that appear in more delicate positions than others. Consider this:
- A file Foo.java defines a class Foo, which extends Bar, defined in Bar.java. So Foo.java depends on Bar.java
- A file Zum.java defines a class Zum, which defines a method zum, which returns Baz, defined in Baz.java. So Zum.java depends on Baz.java
- A file Qux.java defines a class Qux, which defines a method qux. Inside that method we instantiate Blorp, defined in Blorp.java
These three cases illustrate three level of dependencies:
- The first case is a type-definition dependency: we cannot even define the types without satisfying the dependency
- The second case illustrates a method-signature dependency: we can define the type, but not the methods they declare, without satisfying the dependency
- The third case illustrates an implementation dependency: we can define the type and the methods, but not their body, without satisfying the dependency
So what we can do in a similar case is to translate some files partially: we translate everything besides the bodies of the methods which have dependencies to files we have not yet translated. In those cases we just replace the body with a statement to throw an exception indicating the file has yet to be translated.
So we could translate some methods for some classes out of those 27 files, and provide a subset of methods that work and can be executed correctly.
Similar approaches can be used for other languages, but the level of dependencies is different for different languages, so this method requires some language-specific adaptations.
Validating the Migration with Unit Tests
In the case of LionWeb-Java, we could have translated the existing Java unit tests alongside the code. This would enable the client to run tests and validate the correctness of the migrated files. However, in most legacy systems, unit tests do not exist. Given we want to show how this approach could work also for legacy applications, we pretended we didn’t have such unit tests.
We instead generated unit tests, and we did that based on the original Java code rather than the translated Python code. This is crucial because generating tests directly from the migrated Python classes would only verify internal consistency rather than correctness relative to the original system. By instead deriving tests from the Java source, we ensured that the migrated Python code was validated against an independently produced reference.
If you like, we have two sets of artifacts we derived from the original source code:
- The translated source code, produced by the transpiler
- The generated tests, produced by the tests-generator
These two set of artifacts are produced by two independent processes. We then verify that they produce coherent results. We do that by ensuring the tests compile and work against the transpiled code. When this happens it means that either both set of artifacts are coherent, and therefore the process producing them is correct, or they happen to be wrong in an accidentally compatible way. This latter scenario is highly improbable.
This is an example of a generated test:
import unittest
from lionwebpython.utils.IdUtils import IdUtils
class IdUtilsTest(unittest.TestCase):
def test_clean_string_single_period(self):
input_string = “hello.world”
expected_output = “hello-world”
self.assertEquals(IdUtils.clean_string(input_string), expected_output)
def test_clean_string_multiple_periods(self):
input_string = “192.168.1.1”
expected_output = “192-168-1-1”
self.assertEquals(IdUtils.clean_string(input_string), expected_output)
def test_clean_string_no_periods(self):
input_string = “helloWorld”
expected_output = “helloWorld”
self.assertEquals(IdUtils.clean_string(input_string), expected_output)
def test_clean_string_empty_string(self):
input_string = “”
expected_output = “”
self.assertEquals(IdUtils.clean_string(input_string), expected_output)
def test_clean_string_only_periods(self):
input_string = “….”
expected_output = “—-“
self.assertEquals(IdUtils.clean_string(input_string), expected_output)
Ok, I will admit it is a rather simple case, but it should give you the idea.
You may wonder how we generated the tests. Well, every good chef has their little secrets, right? This is something that we’ll expand in a future article, but for now we can share some insights into our approach. We used a combination of algorithmic techniques to extract the appropriate context and then fed into an LLM, that was instructed to analyze the original code to identify requirements. From those, with some massaging and providing context about the migrated code, we were able to generate tests that we could incrementally refine removing compilation and stylistic errors. This allowed us to cover realistic scenarios and verify that the migrated code behaved consistently with the original.
That said, there are alternative approaches for those who cannot fully automate unit test generation in their migration projects. One option is to manually create higher level tests using Gherkin. This enables teams to describe expected behaviors in a human-readable format, making it easier for non-developers to contribute to test definitions.
Another interesting alternative is Approval Tests, which help verify code behavior by automatically comparing test output against an approved reference result. This is particularly useful in migration projects where the primary goal is to ensure that the migrated code produces the same output as the original, without necessarily having to rewrite specific test cases for every function.
In a future article, we might dive deeper into our approach and compare it with these other solutions to help those facing similar migration challenges choose the best strategy for their context.
At this point we can deliver running code with running (and passing) tests to the client. The client can then review the translated files for stylistic and performance considerations while running the unit tests for functional verification.
Beyond validation, having unit tests for the migrated system is essential for long-term maintainability. The lack of unit tests in legacy applications is a primary reason for their difficult upkeep. By introducing tests during migration, we help clients maintain confidence in the correctness of their new system and reduce the risk of regressions in future modifications.
Additional Challenges in Java-to-Python Migration
Beyond dependency management and testing, several technical challenges arise when migrating from Java to Python:
- Library Equivalents: Legacy applications tend to rely on the standard library and a limited set of libraries developed internally by the client. Therefore, we can just translate those libraries. Modern applications tend instead to rely on a lot of libraries developed by others. They may have tens of dependencies and this may pose a challenge. In this case, LionWeb-Java has just a few dependencies. It uses Google’s GSON library and a few others (Protobuf, Flatbuffers). When migrating, we needed to find Python equivalents or reimplement similar functionality.
- Overloaded Methods and Multiple Constructors: Java allows method overloading and multiple constructors, while Python does not support overloading in the same way. So we needed to merge these overloaded methods and constructors. Others may have preferred renaming the different overloaded methods and using factory methods to replace the multiple constructors. This is the kind of choice that we would discuss with our client during the Migration Blueprint.
Conclusion
Migrating every application presents some challenges: analyzing dependencies, ensuring incremental validation, and handling language differences (like support for overloaded methods or lack of it). Of course, a migration from Java to Python has some specific challenges, but the approach to deal with it remains the same: thorough analysis, structured planning, and an iterative migration process.
By generating unit tests from the original system, and gradually delivering validated components, we ensure a smooth transition while maintaining visibility into the migration’s progress. So while we demonstrate this approach on a simple, modern application, in reality, these techniques are particularly valuable for large-scale enterprise migrations, with a lot of interdependencies and no test coverage.

