")
Refactoring is part of a project lifecycle. When dealing with large and complex codebases this might even be the greater part of your work. Can AI help at this step? The short answer is: “eh, maybe!”
For the longer answer, keep reading this article. We combine our language engineering knowledge with that on AI to provide a good answer to this question. If you have not recently used AI-enhanced refactoring, the article might surprise you (or horrify you).
We are going to look through several examples of refactoring tasks to see where AI can help, or whether traditional methods are still better.
Our Example Project
To experiment with refactoring our victim, our test case will be a project created in one of our articles: So Much Data, So Many Formats: a Conversion Service. This is a simple web service meant to convert files from CSV format to JSON format and vice versa. It is based on ANTLR and C#.
We will compare the results of:
- the existing algorithmic, deterministic methods, to accomplish a task (when available)
- a local model or, other local machine-learning based tools
- a Large Language Model (LLM), i.e., a cloud-accessible model
As the local model we are using the one currently considered the best, Codestral. For the cloud-accessible model we are using Claude-sonnet, also the state-of-the-art or close to it. For your reference, dear reader, this article was originally written in March 2025.
Renaming Symbols
Contemporary IDEs offer the possibility of renaming symbols, like variables or functions with a simple click.
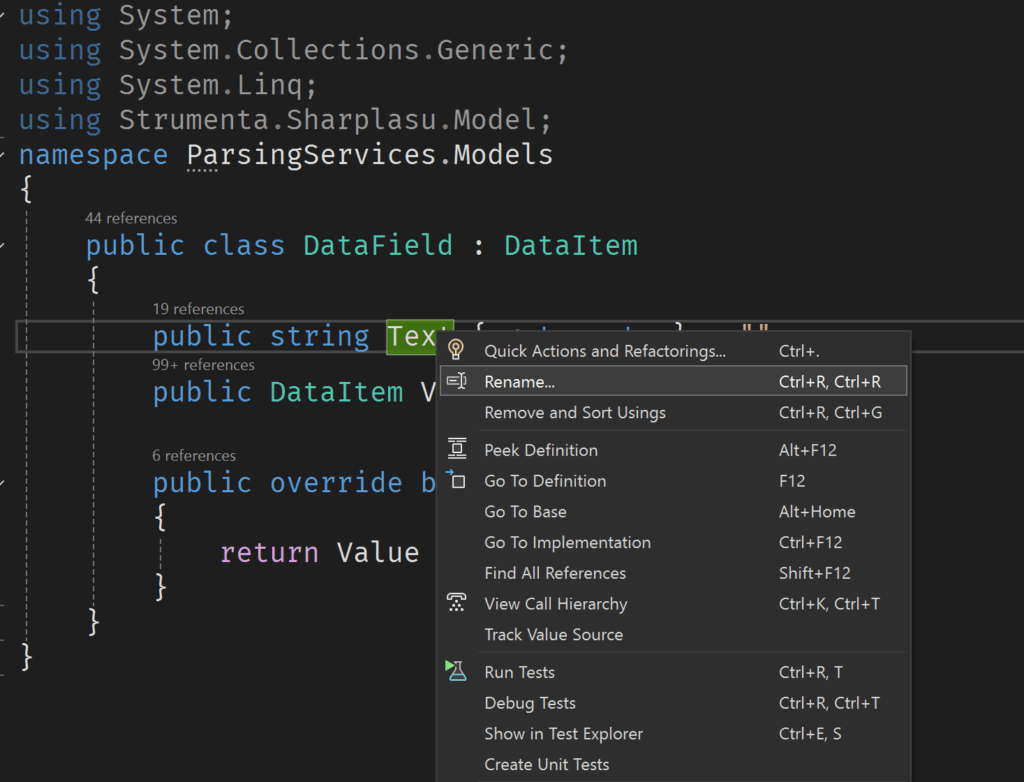
It’s quick, reliable and it works. All you need is the ability to parse the code and resolve symbols. We need to resolve symbols because we don’t want to change the name of elements with the same name or references to other elements with that same name. For instance, in this example we want to change the name of the variable text of the constructor, but not the one of the same name of the class.
Is there any value to using AI for this? No, even a software like Cursor, an AI-based code editor, uses the basic VS Code functionality to achieve this.
This is also true for things like linting and static analysis. For the most part, the existing tools are more reliable than asking AI to enforce a particular coding style. While AI might be easier to set up, you can never be sure if it really gets everything, It might miss or confabulate something, and you don’t really want this uncertainty in software meant to enforce standards. And we didn’t even mention that it’s slower and potentially expensive. Here, software based on language engineering techniques (i.e., parsing, symbol resolution) is still king.
The only potential value of using AI is in corner cases. For instance, if you have a project that uses cryptic names, and you want to mass rename variables to make them more meaningful.
In a small example we can see that it works quite well. Although in larger projects and variables used in different files, it is unreliable. Remember that LLMs do not perform symbol resolution, they just act on patterns. Especially when using languages with complicated scoping rules, like Java, we don’t trust AI to correctly change each variable reference. You can try it, if you’re willing to move step-by-step, compiling, checking each change and repeating the process.
Making Repeated Small Fixes
Writing code means accepting that you have to repeat or fix your code a lot of the time. You end up rewriting small bits of code. These changes are too complex for a regex, so in the past you ended up doing the work by hand. Now you can speed up these small fixes.
You implement something, and then you realize you have missed some details and have to rewrite part of the code. Making mistakes like these doesn’t bother me at all.
As you can see in this short video, in an IDE like Visual Studio you can activate machine learning-based suggestions, i.e., a smart autocomplete, to avoid re-typing small edits by hand.
This feature is called IntelliCode, and it’s quite neat, especially since you don’t need to send your data to the cloud, so there are no risks or big downsides.
Having this machine learning feature is neat. Until you need to fix 631 classes, it is helpful.
Implementing Methods
If you’ve ever programmed in a language like C# or Java you’re certainly familiar with methods used to implement object comparison. In C#, they are called Equals and GetHashCode. You’ve probably written a lot of implementations.
Modern IDEs can also generate basic implementations that work generally well. Sometimes you need to change them to ensure the comparison actually makes sense, but you often get lucky. Sadly, this generation is a rarity, most of the time when you ask an IDE to implement interface methods it just generates methods that return an exception.
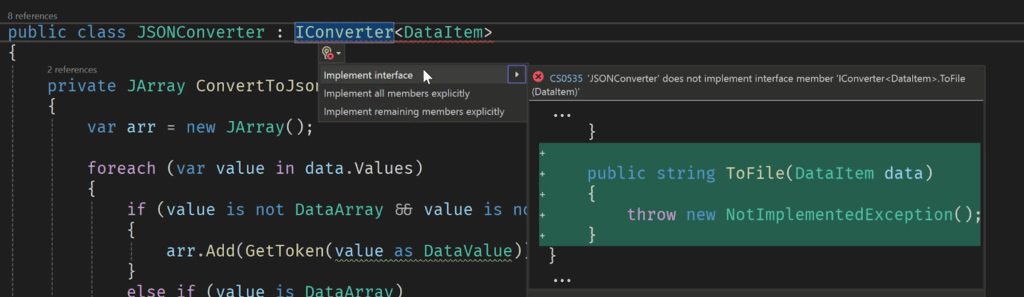
At least this way you get the signature right and can compile the code, but it’s not much.
Is there something that AI can finally help with?
In this short videos I use Cursor to generate implementations for two methods of the interface: ToFile and FromFile. The interface is a generic way to create DataItem objects, i.e., the internal representation of data in this program, and an output file.
Let’s see the ToFile method first.
And then the FromFile method.
We can compare these two implementations with the ones I have created myself.
public string ToFile(DataItem data)
{
JContainer container = data switch
{
DataArray array => ConvertToJsonArray(array),
DataObject obj => ConvertToJsonObject(obj),
_ => null
};
if (container == null)
return string.Empty;
var settings = new JsonSerializerSettings
{
ReferenceLoopHandling = ReferenceLoopHandling.Ignore,
Formatting = Formatting.Indented
};
return JsonConvert.SerializeObject(container, settings);
}
public DataItem FromFile(Stream dataFile)
{
var parser = new JSONParser();
try
{
return parser.Parse(dataFile).Root;
}
catch
{
return new DataItem();
}
}
For context, keep in mind that I’m using the Cursor autocomplete feature rather than the agentic interface. So, it’s the lowest level of performance and comparable to what you would see in a local model.
I would say that the results are mixed. The FromFile implementation is equivalent to my own, in some sense even better, given that it’s checking whether the string has content before trying to parse it. So, a great result!
But, the ToFile method isn’t good. It confabulates a ToString method, that would make sense to use, if it actually existed. So, it would make sense to avoid repeating code and relying on the method that generates a string from a DataItem object. However, the method doesn’t exist in the code. So, it’s generating code that makes structural sense, but it doesn’t actually compile. It’s a mediocre result, saves work, but need fixes.
Let’s see the results with the local LLM model.
public void ToFile(DataItem data, Stream outputStream)
{
if (data == null || !IsValid(data))
throw new ArgumentException("Invalid DataItem object");
var json = JsonConvert.SerializeObject(data);
using var writer = new StreamWriter(outputStream, Encoding.UTF8);
writer.Write(json);
}
public DataItem FromFile(Stream dataFile)
{
using var reader = new StreamReader(dataFile);
var jsonString = reader.ReadToEnd();
return FromString(jsonString);
}
We would rate these results of similar quality compared to the cloud models, but with different issues. Interestingly this model doesn’t confabulate methods. IsValid, FromString do exist in the code. The code also makes sense in both cases. However, it confabulates the interface for the FromFile method, so it loses some points there, so close to the finish line!
This is, of course, just one example. However, I have been trying AI-supported refactoring for a while and the results seem to be consistent. The local model can keep its own when both local and cloud models have limited access to the code. In both cases we’re just asking them to consider the local file. So, if you are privacy inclined, you don’t lose much value in relying on local models for this specific task.
The problem might be the interface to access this local model, so finding an IDE that allows you to integrate a local model for autocomplete. Aside from that, it does work equally well (meh level). The situation changes the closer we get to the next use case.
Making Changes that Affect the Whole Project
We’re now going to see refactoring that affects the overall project. These are changes that require an understanding the overall program structure in order to be successful. They might require us to write a lot of code, but not necessarily.
Some examples:
- Updating a simple dependency (i.e., a dependency that does not require rewriting much of the code)
- Separating a Web project that contains both API and client-facing interfaces
- Adding a new interface
- Adding tests to an existing project
Let’s try the first one. We are going to ask Cursor to update the outdated .NET Core 2.0 dependency to the latest version .NET 9.0. You can see the results in this video. The short version: it works, but the AI needs some prodding and help. It works better if you understand the process, and can tell it what to do when it gets stuck.
We consider this a simple dependency since it doesn’t require any significant change to the code, only to the configuration.
This is quite illustrative of the process of working with AI, every task is a journey of discovery: of new imaginative bugs created by AI, but also of actual solutions. Jokes aside, some notes on what happened.
I had to stop the video in places to manually solve some problems. Specifically it was easier to build the ANTLR parser directly rather than let the AI figure it out. The AI was trying to mix an old version of ANTLR with the current one. You can see at around the 2 minute mark that it was trying something that could have worked: using the MSBuild pipeline to build the ANTLR parsers automatically. I have used that in older versions of Visual Studio relying on an extension, but I don’t think it is feasible anymore with the more recent Standard runtime. I don’t consider this a failure: the task is unusual and there was a genuine lack of documentation in the project (it was in the original article). So, a failure was expected.
The project was also buggy from the beginning: it needed a Data directory to run correctly, which is absent in my copy of the code. The AI was able to figure it out by looking at the code and solve the problem.
The AI was also able to solve problems that it itself created, like the configuration problem requiring a redirect to a HTTPS version of the site, without setting up such version. This is a neat case to illustrate how it works: it created a standard configuration, based on its own knowledge, but that did not work for this specific case. However, it was able to figure out the issue and adapt its approach. We did end up with a working, updated project.
The AI is not omniscient, but it is able to do things by trial and error, relying on help from error messages and human suggestions.
We tried the same task a few times. It did succeed most of the time, but the code had slight differences. For instance, sometimes it used .NET 8.0 and sometimes .NET 9.0. So, it isn’t usable as-is in production projects: you will get inconsistencies. You need to actually check every line of code added by AI.
We did try to do the same with a local model and the result was just failure. Partly it’s an issue with lack of context. There isn’t a ready to use interface to provide access to a whole project using a local model. In part, it’s that the buzzword at the time, agentic, in this case is actually meaningful: there are no good and effective open-source models able to act meaningfully in managing projects (i.e., compiling and react to compiler feedback). So, local models do work for solving small problems, but not changing projects.
What About Other Examples?
We also tried all the other examples listed at the beginning of this section, like adding tests. We didn’t show a video of those attempts because the results are similar. It works better on a clean slate and with less complicated things than others. For example, it managed to create a Vue-based web interface. Even adding, completely unprompted, an “About” page with interesting ideas to improve the project.
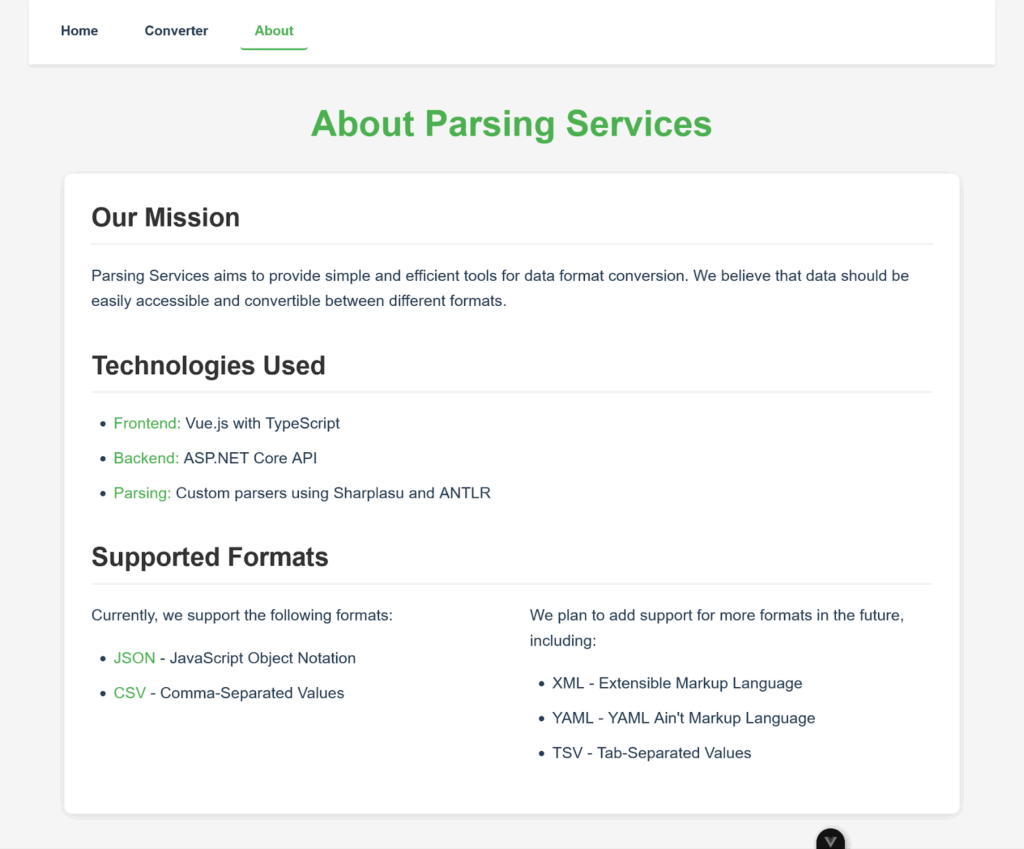
Note that the project did effectively just support CSV and JSON, and adding other formats make sense. So, it was really a good surprise.
However, it failed in creating a Blazor-based interface. To be fair, even manually I had trouble finding the error. Even comparing it with a Blazor project created by Visual Studio, I was unable to figure out what was wrong. So, maybe it is just Blazor that is error-prone. There have also been drastic changes in the use of the Blazor technology in the last few years, so the examples available in its training were probably confusing.
In any case, generally it does ultimately produce working code, especially if it can rely on hard, reliable information: standard error messages from compiler and other tools.
This is the best source of feedback probably because it is consistent, so the AI had seen it as-is during training. Sometimes when it got stuck we tried other solutions, such as pointing it to an article with the right approach or carefully telling it what to do. These solutions are less reliable since it is not always able to interpret it correctly.
Changing Foundational Dependencies
We are at the last big category of refactoring: changing foundational dependencies that requires refactoring large parts of the code. An example could be changing Object-relational mapping (ORM) libraries or large scale refactoring. Another one is migrating from Mulesoft to Spring Boot. The linked article is about this kind of refactoring.
The current best solution is to use tools like Spring Boot Migrator or OpenRewrite that implement a recipe: a sequence of rules. The rules are deterministic changes to the project, like adding some configuration setting or changing function calls. These rules are written by developers expert in both platforms.
Does AI change that? It seems that the answer is, yes but not in a straight way. Moderne is the company that maintains OpenRewrite. So they are an interested party in this debate. However, they performed an analysis that confirm our experiments: How to use generative AI for automating code remediation at scale.
They asked AI models to apply one of the rules you would use in these migrations. In their case it was a static analysis rule, but the principle is the same: find and modify certain lines of code. The automated tool is reliable and effective. The AI sometimes get it right, especially if guided and when the human tells it where to focus:
One thing of note that this experiment confirmed for us is that AI is more successful (i.e., accurate) if the issues are identified first then provided to the AI to focus the work. As an anecdote, the AI performed better when only given the code snippet that needed to be changed.
So, this confirms what we have seen previously in the article. AI works better when asked to perform a limited task and when provided with clear feedback. The problem is that this doesn’t fit well with the task we are currently focused on. Sure, changing the code correctly is important, since it requires specialized knowledge in both platforms. It is also boring and repetitive. However, finding the code to change is also a big part of the job.
To solve this problem, then, of course, Moderne offers its own AI. They trained a custom model to be better at this kind of refactoring. Their main claim is that their model is better at creating a meaningful representation of code, therefore it can work better on manipulating it. We are not in a position to evaluate this, but we agree on a specific use case they suggest.
Second, while auto-remediation with OpenRewrite recipes is the most effective way to fix source code, recipes must initially be created by developers who could use an assist from deep learning. The Moderne platform can use AI to enhance and speed recipe authorship, resulting in 100% accurate code changes. In fact, recipe authorship is a perfect use case for generative AI—with well-defined parameters and well-tested results before put into mass use.
The emphasis is ours. We would not ask an AI model to perform mass refactoring directly. However, it is a great idea to use it to create rules that govern industry-standard refactoring tools. It is a great fit for AI since you have a well-defined output (i.e., the recipe) that a human can inspect and evaluate. Then you rely on an automated, deterministic and reliable tool to actually implement the change.
Using this approach you can improve productivity on the creation of rules without risking disaster modifying the code at scale.
The Many Kinds of Refactorings
There are many kinds of automatic refactoring that have been invented or used over the years. We’ve seen a few examples in this article. We categorize them to see if, and when, AI can be useful.
- Renaming variables and functions. Such as changing a function from
getHelptohelpMe.- AI is not needed here.
- Making Repeated Small Fixes. For example, you want to replace a long series of nested calls to a call to one extension method.
- Local machine learning methods work well, when available.
- Implementing Methods. Like creating the methods of an interface.
- Both local models and large cloud models can be effective. You need to find good tools to use local models in your IDE
- Making Changes that Affect the Whole Project. Such as adding a new web interface. Or changing from using directly a library like ANTLR to build an AST with a support library like Sharplasu.
- Your only option is to use cloud models. They work, eventually.
- Changing foundational dependencies. For instance, migrating from an outdated framework to a new one in a production application.
- Local cloud models used directly are unreliable. They can be used to instruct automated refactoring tools that can do these changes well, though.
Refactoring Projects Written in Legacy Languages
In this article we have not talked about the specific case of code refactoring in legacy languages. There are two issues to discuss:
- Availability of LLMs that are trained for legacy languages
- Specific kinds of refactoring needed for legacy code
Quite simply if there are no LLMs trained on legacy languages, then no AI code refactoring is possible. This is especially true because there are often few open-source projects written in legacy languages, so you cannot do it yourself, even if you had the budget to spend on building your own.
LLMs for Legacy Languages
The good news is that some LLMs are somewhat trained on many legacy languages: you can find models trained on SAS or COBOL. However, we should understand what it means: these LLMs have some familiarity with the syntax of the language, but that is all.
Now, we should consider that LLMs attempt to generalize from the information they are trained on, but there is a common misconception that everything is available to these models—whether legally obtained or otherwise. In practice, training data coverage is uneven, particularly for legacy technologies.
Modern languages like Java, Python, and JavaScript are heavily overrepresented, as millions of public repositories exist for them. For legacy languages such as SAS, COBOL, or RPG, the situation is very different: there are not nearly as many publicly available codebases. Not only that: the publicly available code it is often not representative of real-world enterprise applications. We experienced that ourselves: for years we have looked for an industrial-grade ERP written in RPG having its code publicly available, so that we could use it in public demos. We did not find a single one. We could find a few toy examples or small utilities, but that was all.
This is not just the case for RPG. It is also true, for example, for SAS, where most production systems live in closed, proprietary environments. For instance, a reader familiar with the StarCoder dataset pointed out that although SAS is nominally present in the training data, it is represented by around 9,000 programs—mostly from clinical trials or tabular report generation. These do not reflect the core analytics workflows that companies actually use SAS for. So while technically “included,” such datasets are of limited value for serious SAS-related LLM tasks. The consequence is that the conception that the LLM would have of SAS code, would be one derived from looking at code that is very different from the one used in most companies. To build a proper solution we would need to have access to tens or even hundreds of millions of lines of real-world code.
If your legacy language of interest is IBM RPG, the situation is even worse, as there are no known good models available with at least some cursory knowledge of the language. Even IBM, with Granite, its open source LLM, does not support RPG. You can see in the appendix of the linked paper that SAS and COBOL are there (with the limitations discussed), but not RPG. So, you will have try cloud LLMs and see how it goes.
Personally, we tried them, with decent results on simple refactoring. The problem for large code refactorings, aside from the quality of the training, is that even with agentic LLMs the feedback cycle is broken. We’ve seen that AI gets things wrong, but it can fix them based on hard feedback from compilers and other tools. However, this is not possible when trying to compile things for platform like the IBM AS/400, so the results are not going to be great.
We did ask an LLM to create a small IBM RPG program, but the code did not compile. And we didn’t receive any usable feedback from the IBM tools, so we stopped there.
Specific Refactoring Needs of Legacy Projects
The second issue relates to specific refactorings that are more useful for legacy projects. We don’t need to repeat the reasons here, but legacy program often follow poor practices such as:
- cloning existing programs and making small changes
- having a lot of dead code lying around that nobody is using
Old languages have no support for project management, so it happens frequently. We think that the results are a mixed bag here. AI could probably find cloned code and even refactoring it. Assuming it clears the first hurdle of having access to the feedback of compiler tools.
We don’t think that there’s a need for using AI to find dead code. Understanding what is dead code (i.e., code not used by any program) requires a deterministic dependency analysis, that is best done programmatically. This is a work for your language-engineering experts, that can build and use parsers and symbol solvers to navigate the code and safely identify what is used or not.
Conclusions
AI promises to improve productivity and revolutionize coding. We agree on the first part, but we are only half there on the second.
In our experience, it can dramatically improve the creation of prototypes or adding stuff like brand-new Web interfaces. It doesn’t work great for refactoring, except on the small scale. And it’s too unreliable for mass changes in production code.
So, for large scale changes you should use automated tools created for that specific purpose. You can use AI to instruct such tools, though. After all, configuring these tools only requires a small amount of code.

