")
Introduction
In this article, we will learn how to implement parsers in Python using Pylasu and ANTLR. In order, we will:
- Create an ANTLR grammar for a simple ‘kinda-functional’ programming language called Slang and generate a parser from it;
- Define an Abstract Syntax Tree (AST) using Pylasu and learn how to build these from ANTLR parse trees;
- Integrate our parser with a Command-Line Interface (CLI) application, allowing users to parse Slang code from both strings and files and visualize a JSON representation of the corresponding AST;
In order to keep the article from being too verbose, some code details might be omitted. Check out the complete project source code on GitHub. Feel free to fork the project, play with it and share your improvements, comments or ideas with us!
Parsers and Abstract Syntax Trees
Maybe as part of our latest attempt to create a shiny-looking innovative programming language or data format, or maybe to dust off an existing one – teaching computers to understand languages is a fun drive!
In this, the absolute first step consists in transforming text into something that can be easily manipulated by computers. At first glance, venturing into the dark world of regular expressions might seem like the right path. After all, we are talking about text, aren’t we?
Unfortunately, regular expressions might not provide enough expressive power to process the syntax of language constructs. Most of the existing ones, indeed, require Context-Free Grammars (CFGs) – thanks Prof. Chomsky. Also, manually implemented regular expressions might easily become cryptic and hard to maintain in this context.
In practice, CFGs are used to describe the syntax of most computer languages in terms of rules and dedicated software components are implemented to recognize syntactic constructs in conformance with such grammars. Put simply, we use Parsers.
The typical output of a parser consists in a tree-like data structure called parse tree. In this, the root and the intermediate nodes represent non-terminal rule matches, while leave nodes correspond to terminals. For example, here is a possible parse tree representation (right-hand side) for a simple series of Javascript statements (left-hand side).
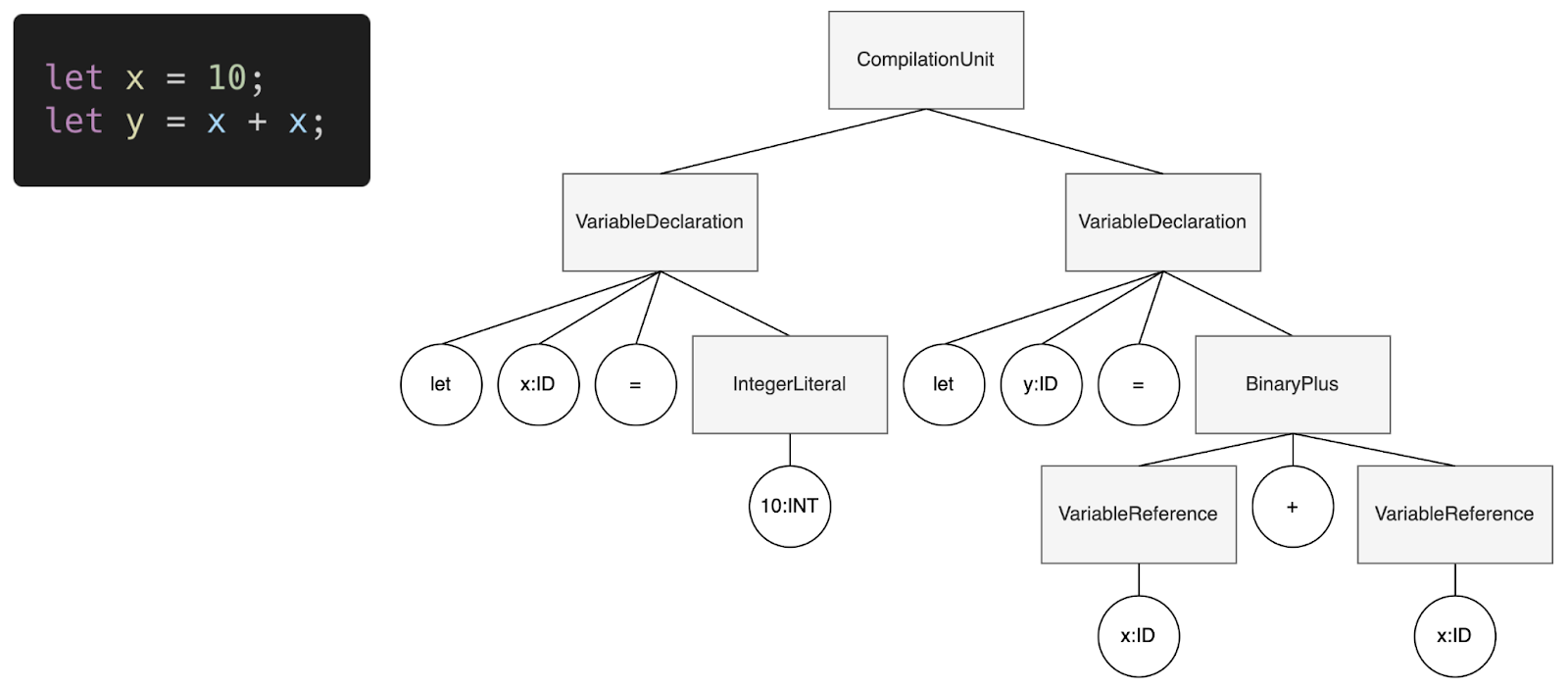
Numerous parsing algorithms exist in the literature, providing different trade-offs between expressive power and computational complexity.
Parsing algorithms can be implemented manually, but a definitely more convenient approach consists in relying on parser generators. These take a grammar specification and produce a conforming parser implementation.
Among parser generators, we love ANTLR at Strumenta – we use it in all sorts of parsing projects on a daily basis and it always worked well for us!
The tree-like nature of parse trees entails ease of navigation and manipulation of the input. However, at some point, the purely syntactic nodes included in it might become irrelevant. For example, parentheses can be useful to understand the order of the operations in text and determine how the parse tree is organized. Once the parse tree is created these do not provide useful information anymore and can be removed. This is different from what happens with identifiers or literals, which remain valuable as they provide information through their content.
For this reason, additional transformation steps are implemented into parsers to extract what’s called Abstract Syntax Tree (AST). Going back to our Javascript example, this is a possible abstract syntax tree representation where purely syntactic keywords and punctuation has been removed.
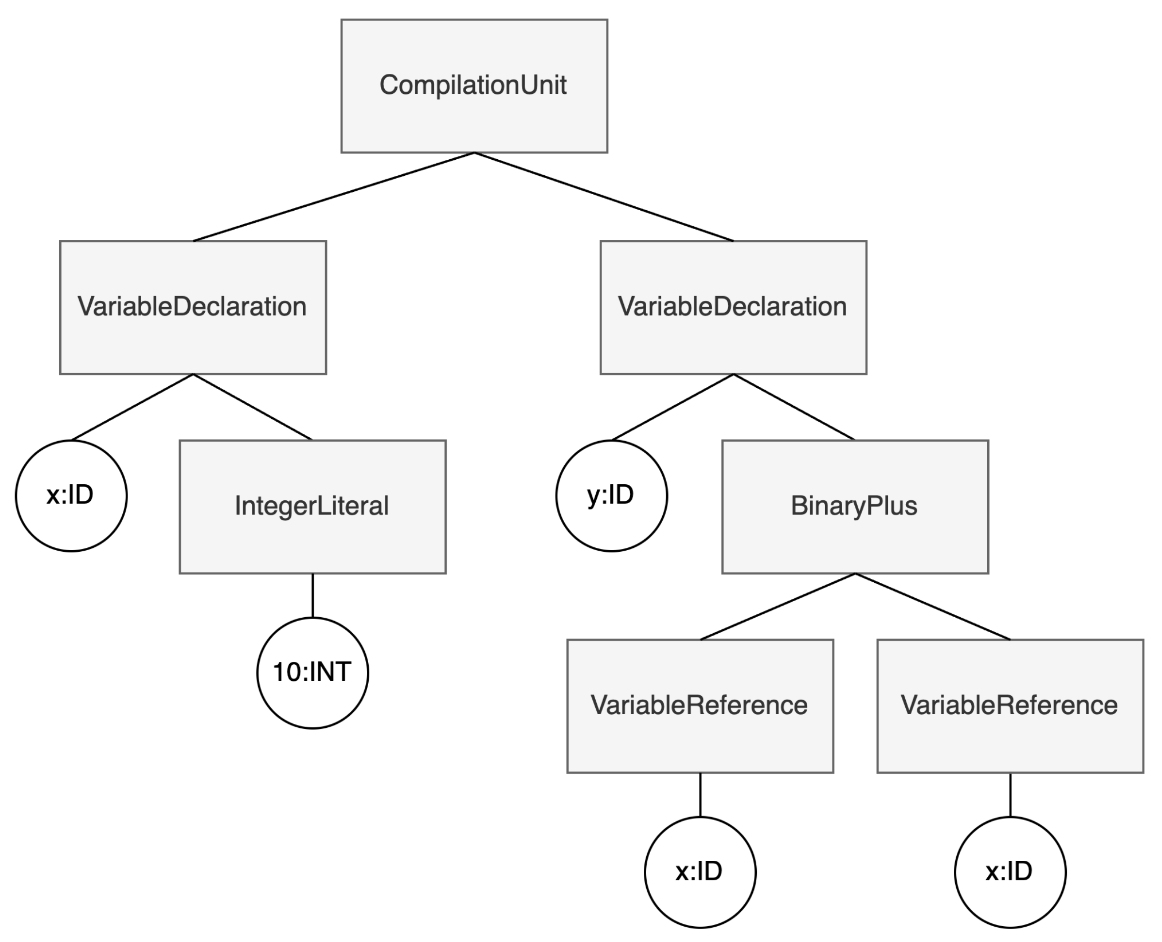
The Slang Language
Slang is a toy programming language showcasing some typical language constructs found in both imperative and functional languages. As such, feel free to interpret each construct with your preferred semantics, the following discussion will rather only focus on the syntactic aspects of the language.
Example – Fibonacci using Slang
The function computing the Nth number of the Fibonacci series seems to be a quite popular example to give a taste of the syntax of a programming language. We like the Fibonacci series, so here is a possible outstanding implementation using Slang
function fibonacci(n) {
if (n <= 1) return n;
else return fibonacci(n - 1) + fibonacci(n - 2);
}
In the following paragraphs, we introduce the various language constructs for Slang. For each construct, we provide the corresponding ANTLR parser grammar rule. The complete ANTLR parser and lexer grammar specifications can be found in SlangParser.g4 and SlangLexer.g4 files on GitHub, respectively.
Workspaces
Each file contains a single workspace definition in Slang. This acts as a container construct for zero or more function definitions and standalone statements.
workspace: functions+=function* statements+=statement* ;
Functions
Function definitions consist of a name, zero or more parameters and zero or more statements. Parameters are identified by their name and do not include type constraints or specifications.
function: FUNCTION name=NAME LPAREN (parameters+=NAME (parameters+=NAME)*)? RPAREN LBRACE statements+=statement* RBRACE ;
Statements
Slang provides support for the following kinds of statement:
- Return Statement – can be used to return back some value specified through an expression from a function;
- Print Statement – can be used to display the representation of a value somewhere, e.g. standard output;
- Conditional (aka If-Then-Else) Statement – can be used to execute different logic depending on some condition;
- Binding Statement – can be used to associate names to values;
- Expression Statement – can be used to wrap expressions as statements;
Each statement, except for conditionals having multiple statements in their body, ends with a semicolon. Curly brackets are used to wrap multiple statements in conditionals and can be omitted otherwise.
statement
: RETURN value=expression COLON #returnStatement
| PRINT argument=expression COLON #printStatement
| IF LPAREN condition=expression RPAREN
(LBRACE positive+=statement* RBRACE
|positive+=statement)
(ELSE (LBRACE negative_branch+=statement* RBRACE
|negative_branch+=statement))? #conditionalStatement
| name=NAME BND value=expression COLON #bindingStatement
| expression COLON #expressionStatement
;
Expressions
Slang provides support for the following kinds of expressions:
- Grouping Expression – can be used to override the ordinary operator evaluation order using parentheses;
- Unary Operation Expression – can be used to apply both logical and arithmetic negation, as well as arithmetic identity;
- Binary Operation Expression – can be used to perform arithmetic calculations and comparisons;
- Invocation Expression – can be used to invoke functions with expression arguments;
- Reference Expression – can be used to reference the value of parameters and variables;
- Literal Expression – can be used to define constant integer values;
expression
: LPAREN expression RPAREN #groupingExpression
| operator=(NOT|ADD|SUB)
operand=expression #unaryOperationExpression
| left=expression
operator=(MUL|DIV)
right=expression #binaryOperationExpression
| left=expression
operator=(ADD|SUB)
right=expression #binaryOperationExpression
| left=expression
operator=(LT|GT|LTQ|GTQ)
right=expression #binaryOperationExpression
| left=expression
operator=(EQ|NQ)
right=expression #binaryOperationExpression
| target=NAME
LPAREN (arguments+=expression
(COMMA arguments+=expression)*)? RPAREN #invocationExpression
| target=NAME #referenceExpression
| value=NUMBER #literalExpression
;
Generating Parsers with ANTLR
In order to generate a parser from a grammar specification using ANTLR, there are first a couple of tools that need to be installed. Generally, ANTLR can be used by downloading and running its JAR – hence requiring Java to be installed on our machine. However, there is a simpler solution for us – antlr4-tools.
Using this, the only requirement is reduced to Python, which typically comes installed on all operating systems. The tool will create two executables to generate and invoke parsers – respectively antlr4 and antlr4-parse. The first time any of these commands will be invoked, the installation of both Java and ANTLR will be silently handled.
Checkout the antlr4-tools GitHub repository for detailed installation instructions.
Let’s get back to our example! We are using the PDM package and dependency manager, hence the following command is executed to install antlr4-tools:
pdm add -dG antlr antlr4-tools
Given our SlangParser.g4 and SlangLexer.g4 grammar files, we can then generate an ANTLRv4.9.3 parser targeting Python3 with the following command:
antlr4 -v 4.9.3 -Dlanguage=Python3 -no-visitor -no-listener SlangLexer.g4 SlangParser.g4
The process will generate our parser in SlangParser.py, while the SlangLexer.py file will contain the lexer. The -no-visitor and -no-listener options specify that we are not interested in generating ANTLR4 base visitors and listeners in this case.
Check out our ANTLR Mega Tutorial for further details and start your path towards becoming an ANTLR ninja!
In order to rapidly test out the generated parser, we can use the antlr4-parse command as follows:
# parse and print out the tokens antlr4-parse SlangParser.g4 SlangLexer.g4 workspace <file_path> -tokens # parse and print out the parse tree antlr4-parse SlangParser.g4 SlangLexer.g4 workspace <file_path> -tree
Otherwise, we could also install the ANTLR Python runtime and programmatically invoke the parser as follows:
# Install antlr4-python-runtime with: pdm add antlr4-python-runtime from antlr4 import CommonTokenStream, InputStream from slang.parser.antlr.SlangLexer import SlangLexer from slang.parser.antlr.SlangParser import SlangLexer # the code that we want to parse code = "...slang code..." # tokenize the input using the lexer lexer = SlangLexer(InputStream(code)) # or FileStream(absolute_path) for files # parse the token stream using the parser parser = SlangParser(CommonTokenStream(lexer)) # retrieve the parse tree root parse_tree = parser.workspace() # print out a formatted representation of the parse tree print (parse_tree.toStringTree())
Printing out the parse tree for our fibonacci function will produce the following output – don’t worry, we will make it more readable soon:
(workspace:1 (function:1 function fibonacci ( n ) { (statement:3 if ( (expression:5 (expression:8 n) <= (expression:9 1)) ) (statement:1 return (expression:8 n) ;) else (statement:1 return (expression:4 (expression:7 fibonacci ( (expression:4 (expression:8 n) - (expression:9 1)) )) + (expression:7 fibonacci ( (expression:4 (expression:8 n) - (expression:9 2)) ))) ;)) }))
Defining ASTs with Pylasu
Until now, we defined an ANTLR grammar specification for our language, generated a parser from it and saw how to print out the parse tree for a given file or string. Let us now introduce an abstract syntax tree using Pylasu.
Pylasu is an open-source library supporting the StarLasu methodology in Python. Other equivalent libraries exist to enable support in Kotlin (and the JVM), Typescript and C#.
Abstract syntax tree nodes can be defined through classes extending the Node base class in Pylasu. Nodes come with various built-in features supporting the implementation of recurring tasks when implementing language processing applications:
- Position – each node keeps track of its corresponding position in the source text in terms of line and column number;
- Traversal API – various functions can be used to navigate nodes, their children and properties;
- Transformation API – dedicated classes and functions can be used to transform nodes into other nodes or text;
- Origin and Destination – when involved into a series of transformations, each node keeps track of its origin and destination, that is the nodes where it originates from and those produced from it;
In addition to these core features, StarLasu libraries provide support for advanced concepts, such as symbol resolution, type computation, serialization, testing. Check out the documentation for further details!
Going back to our language, the following snippet shows how the node representing function definitions can be defined using a Python dataclass:
from dataclasses import dataclass, field from typing import List @dataclass class Function(Node): name: str = field(default_factory=str) parameters: List[str] = field(default_factory=list) statements: List['Statement'] = field(default_factory=list)
That’s it, really! Extending the Node base class will integrate our node specification into the Pylasu infrastructure. Therefore, we will be able to navigate through its children, access its corresponding position in the source code (if coming from a textual source) and so on.
Node classes can also contain no properties or extend each other. For example, we decided to define a dedicated AST node for each unary operation. In the parse tree, instead, these are all represented using a single UnaryOperationExpression node. The following snippet illustrates how unary operation expression nodes can be modeled for our purpose:
from dataclasses import dataclass, field from pylasu.model import Node from typing import Optional @dataclass class Expression(Node): '''AST node representing an expression''' pass @dataclass class UnaryOperation(Expression): '''AST node representing a unary operation expression''' operand: Optional[Expression] = field(default=None) @dataclass class Not(UnaryOperation): '''AST node representing logical negation operations''' pass @dataclass class Minus(UnaryOperation): '''AST node representing arithmetic negation operations''' pass @dataclass class Plus(UnaryOperation): '''AST node representing arithmetic identity operation''' pass
The rest of the AST node definitions is omitted for brevity, you can find it inside the nodes.py module.
From ANTLR Parse Trees to Pylasu ASTs
We are now ready to transform our Parse Tree into an AST.
In Pylasu, transformations can be implemented by creating and configuring ASTTransformer instances. In the specific case of a transformation mapping ANTLR Parse Trees to ASTs, the dedicated ParseTreeToASTTransformer class can be used. A transformer instance can be created as follows:
from pylasu.mapping.parse_tree_to_ast_transformer import ( ParseTreeToASTTransformer ) transformer=ParseTreeToASTTransformer(allow_generic_node=False, issues=[])
The idea behind transformers consists in supporting a mostly declarative specification of transformation rules using NodeFactories, while taking care of all details concerning the position of nodes – that is, the line and column number at which these appear in text.
There are various ways a NodeFactory can be defined, the simplest one consists in specifying the source and target node types, along with their children – used to guide the transformation. For example, mapping a WorkspaceContext parse tree node into our Workspace AST node, the following factory can be registered:
from pylasu.transformation import PropertyRef
from slang.ast.nodes import Workspace
from slang.parser.antlr.SlangParser import SlangParser as _
# workspace (constructor-node-factory-with-child)
(
transformer.register_node_factory(_.WorkspaceContext, Workspace)
.with_child(PropertyRef('functions'), PropertyRef('functions'))
.with_child(PropertyRef('statements'), PropertyRef('statements'))
)
In short, we are instructing the transformer to create a Workspace instance whenever a WorkspaceContext is encountered in the parse tree, and populate the functions and statements properties by mapping each element with the appropriate factory – the rules mapping FunctionContext with our Function node, for example. PropertyRef is a Pylasu class used to represent references to node properties.
Sometimes, however, we might need a bit more freedom. Passing a reference to the class constructor – e.g. Workspace – requires this being a parameter-less one. Other classes could have mandatory constructor parameters, therefore, we also provide support for more complex kinds of factories – any Callable producing the right AST node instance.
Let’s use lambdas, for example, to define our node factory mapping BindingContext parse tree nodes into Binding AST nodes, as follows:
from pylasu.transformation import PropertyRef
from slang.ast.nodes import Binding
from slang.parser.antlr.SlangParser import SlangParser as _
# statement - binding
transformer.register_node_factory(
_.BindingStatementContext,
lambda source: Binding(name=source.name.text) # handle 'name' property
).with_child(PropertyRef('value'), PropertyRef('value'))
As you can see, we still use children references to map the value property, but the name property is manually handled. In particular, we are setting it using the text property of ANTLR terminal nodes – the NAME token in this case.
Defining lambdas for complex logic is cumbersome, often not possible and generally discouraged in Python. In these cases, we can use user-defined function references – defs.
As mentioned in the previous section, while unary operation expressions are represented using a single kind of parse tree node, we decided to define dedicated nodes in our AST. Therefore, we need some slightly more sophisticated logic to map UnaryOperationExpressionContext parse tree nodes into UnaryOperation AST node subclasses, as follows:
from pylasu.parsing.parse_tree import to_position
from pylasu.validation import Issue, IssueSeverity, IssueType
from pylasu.transformation import PropertyRef
from slang.ast.nodes import Minus, Not, Plus
from slang.parser.antlr.SlangParser import SlangParser as _
# node factory from user-defined function
def unary_operation_node_factory(source: _.UnaryOperationExpressionContext):
# common builder function for unary operations
def build_unary_operation(unary_operation_constructor: ...):
unary_operation = unary_operation_constructor()
# manually invoke the transformer to transform the 'expression' property
unary_operation.expression = transformer.transform(source.operand)
return unary_operation
# branch depending on the operator
if source.NOT():
# create a 'Not' AST node instance
return build_unary_operation(Not)
elif source.ADD():
# create an 'Add' AST node instance
return build_unary_operation(Plus)
elif source.MINUS():
# create a 'Minus' AST node instance
return build_unary_operation(Minus)
else:
# oops...
issues.append(
Issue(
IssueType.SYNTACTIC,
f"Unsupported unary operation: {source.operator.text}",
IssueSeverity.ERROR,
to_position(source)
)
)
return None
# register the node factory
transformer.register_node_factory(
_.UnaryOperationExpressionContext,
unary_operation_node_factory
)
See the oops there? This example also illustrates how issues can be added during the transformation. In this case, we are creating a syntactic error issue in case an unexpected unary operator is found. This should not happen given that the ANTLR parser would not recognize other unary operators…but better be safe than surprised.
All the other mappings fall into one of these categories and are omitted in this article for brevity. Please check the complete source code in the transformations.py module on GitHub.
‘Packaging’ our Parser
As mentioned at the beginning of this article, our objective consists in implementing a parser and integrating this into a CLI allowing users to parse strings and files.
Before doing so, it is convenient to wrap our parser capabilities into a well-defined interface. More specifically, we expose two functions from a main.py module, namely parse_string and parse_file:
from antlr4 import CommonTokenStream, FileStream, InputStream from pylasu.validation import Result def parse_string(code: str) -> Result: return parse_input_stream(InputStream(code)) def parse_file(filename: str) -> Result: return parse_input_stream(FileStream(filename))
Both functions wrap their input into an ANTLR input stream and delegate the actual work to another function named parse_input_stream. The result consists in a Result instance, which is a utility class provided by Pylasu to represent parsing results. More specifically, it keeps a list of possible issues encountered during the parsing process and a reference to the root of the AST.
The issues list can be populated with errors thrown by the internal ANTLR parser or user-defined ones emerged during subsequent phases, e.g. as seen with our unary operation node factory in the previous section.
What is happening inside the parse_input_stream function? Well, we put all the previous steps together and build a Result instance out of it, as follows:
from antlr4 import InputStream from pylasu.validation import Result, Issue def parse_input_stream(input_stream: InputStream) -> Result: # keep track of all issues issues: List[Issue] = [] # 1. build the ANTLR Parse Tree parse_tree = _build_slang_parse_tree(input_stream, issues) # 2. transform the ANTLR Parse Tree into the Pylasu AST abstract_syntax_tree = _build_slang_abstract_syntax_tree(parse_tree, issues) # 3. build a Result instance and return it back return _build_pylasu_result(abstract_syntax_tree, issues)
The complete source code is omitted for brevity, please checkout the main.py module on GitHub for further details.
A Pretty-Cool Command-Line Interface
We are finally ready to implement our PC-CLI!
For this, we are going to cheat a bit and delegate the ‘make-it-cool’ task to Typer, a Python package supporting the creation of command-line interfaces with built-in auto-completion, argument validation and so on.
Sort of a version of Click on steroids – psss…that is actually what they are using inside! Check out their documentation for a complete overview of the supported features and feel free to make our CLI even cooler.
We can install the package as follows (if you are using our project setup):
pdm add "typer[all]"
Once completed the installation, setting up a series of commands is pretty straightforward. In our case, we want to structure our interface so that users can run the following commands:
slang parse string "<slang_code>" # parse slang code from a string slang parse file <file_path> # parse slang code from a file
In order to do so, we define the following decorated functions:
from pathlib import Path
from typer import Argument, Typer
from typing_extensions import Annotated
from slang.parser import parse_file
# initialize a Typer application
app = Typer()
# add the command group 'parse'
parser_app = Typer()
app.add_typer(parser_app, "parse", "Parse slang code from strings or files")
# add command 'string' to the 'parse' group
@parser_app.command("string", "Parse slang code from a string")
@track_progress("Parsing")
def from_string(code: Annotated[str, Argument(help="...")]):
return build_report(parse_string(code))
# add command 'file' to the 'parse' group
@parser_app.command("file", "Parse slang code from a file.")
@track_progress("Parsing")
def from_file(path: Annotated[Path, Argument(help="...")]):
return build_report(parse_file(str(path.absolute())))
The track_progress decorator function keeps the user entertained while the parsing process is running, i.e. it shows a progress bar. Instead, the build_report function just serializes our AST into JSON. Their complete specification is omitted for brevity, please check out their source code on GitHub.
There are various ways to expose scripts from a Python package, you can find the complete configuration inside our pyproject.toml file. In our case, we just added a script in the tool.pdm.scripts configuration to be able to execute commands like pdm run slang, as follows:
[tool.pdm.scripts]
slang = { call = "slang.cli:app" }
In order install the package and be able to run it using python -m slang, we can just add a __main__.py file into our package, create an instance of our command-line interface and change its default name, as follows:
from .cli import app app(prog_name='slang')
One last thing, update the pyproject.toml file with a project.script configuration as follows to be able to install the package and use it as an ordinary prompt command:
[project.scripts] slang = "slang.cli:app"
Now, we are finally able to play with our CLI. Here are some execution examples, feel free to run these by yourself and have fun!
Asking for help

Help…again

Parsing strings

The full output is omitted here, run it to see the entire AST.
…and parsing files
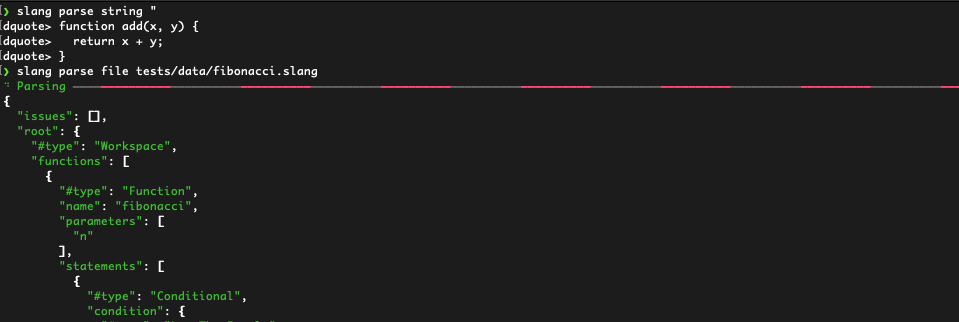
In this case, we parsed our fibonacci function and successfully got back the corresponding AST with no issues, yay!
Conclusions
In this article, we implemented a parser for the Slang toy programming language in Python using Pylasu and ANTLR.
First, we defined the ANTLR grammars and saw how antlr-tools can be used to trigger the generation process. Then, we defined our AST using Pylasu and implemented a model-to-model transformation to create instances of it from ANTLR parse trees. Finally, we integrated our parser into a CLI providing users the possibility to parse Slang code from both strings and files.
Pss…check out the project repository to see how the whole ANTLR generation process can be integrated into the build workflow using Tox. This might be a topic for a future article, let us know what do you think about it.
You did it, you reached the end of this article and we hope this was a fun and interesting drive! Get in touch with us on social media, through the project repository – or carrier pigeons if you like – for comments, feedback, everything really…and have a nice day!