We’ve all been using LLMs for a while now, and we’ve all been impressed by them. At some point it is natural to ask the question: is this it? Is this what is going to replace software? Are we just going to talk to computers from now on, describe what we want, have it appear, and skip everything in between?
I don’t think so, but it’s tempting to believe it. Type “show me sales for the last five years” and you get a chart. Ask for the slide deck and you get the slide deck. Done. Who needs SaaS anymore?
But that misses what software has been doing for us all along. In my opinion, it remains relevant in four ways:
- Data organized and normalized.
- Consistency enforced.
- Things visualized in ways that help us see patterns.
- Processes guided step by step. Years of accumulated know-how about how to do a job right, captured and made executable.
So yes, LLMs are showing us something genuinely useful: that interfaces can be far more flexible than we assumed. But I don’t think that’s the same as software disappearing into conversation. Let’s look at why.
What does software actually do?
Let’s ground this in something concrete: a CRM. Yes, CRMs are boring as hell, but every B2B company has one and we are familiar with them. And, let’s face it, most of the software we use does not have to be glamorous. It just has to do some boring job for us.
It organizes data into a structured, queryable, normalized form.
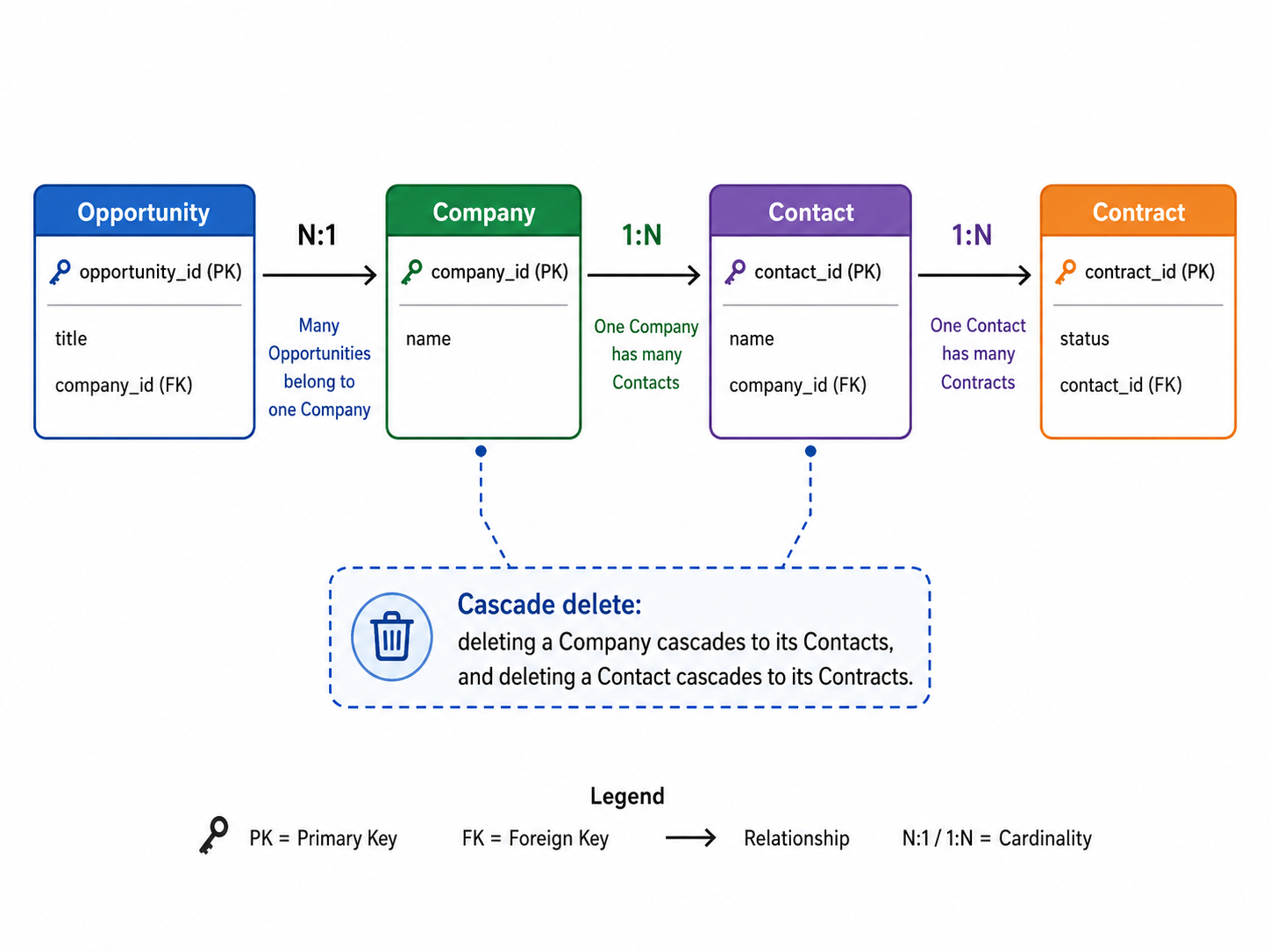
An opportunity is not a blob of text. It is a record linked to a company, which has contacts with phone numbers and emails, a lead-source field that feeds your marketing attribution, and a chain back to past contracts. That structure is what lets you ask “which opportunities came from referrals and closed above €50k in the last six months?” and get an answer you can trust in milliseconds, not a paragraph that sounds plausible.
Yes, just writing free-form notes would be more convenient. But without the discipline of organized data, we would lose the possibility of doing most analysis. Also, we are glad our colleagues have to put information into a standard format, right?
It enforces consistency and integrity.
You cannot create an opportunity without first creating the company it belongs to. You cannot delete a company that still has open contracts. The system stops you, or cascades the deletion through every linked record in a defined order. These are the rules that keep your data from turning into garbage six months from now. You know, giving up immediate gratification for a better future.
It enables visualization and filtering.
Purely textual interfaces do not work very well for everything. We need to see data, notice outliers in a graph, and spot patterns at a glance. For that we need visualizations, and also filtering.
Ask an LLM for a sales chart and it’ll happily draw you one. But where did the numbers come from, and will it give you the same answer next month?
It guides processes.
It encodes your company’s terminology, its sequence of approvals, and the little pieces of domain savoir-faire that took years to get right. “You can’t mark an opportunity as won until the contract is attached,” for example. That’s not friction. That’s rules. You may not like them, but you would certainly like your colleagues to follow them if you need to take over some tasks from them.
A historical side note: SQL and the dream of plain English
There is an old dream behind all this. Back in the 1970s, when IBM researchers Donald Chamberlin and Raymond Boyce designed SQL, part of the pitch was that it would be simple enough for non-programmers to use directly. The idea, repeated in talks and papers of the era, was that you wouldn’t need a developer standing between you and your data: a manager could just type out what they wanted in something close to plain English and get an answer back.
The often-cited illustration was something like a home cook typing in the ingredients they had on hand and getting back a list of recipes they could make. It sounded like the end of “the technical layer” getting in the way. Fifty years later, we are still trying to make that promise true, and still discovering that the hard part was never only the interface.
Why can’t an LLM alone replace business software?
Strip away the chat interface and ask: where does an LLM keep its data? It doesn’t. A model has no schema, no foreign keys, no transactions, no constraints.
In many agent setups, the “memory” is a collection of files or notes that the agent reads and writes between sessions. That can be useful, but it is not a database. Notes don’t enforce that an opportunity has a company. Notes don’t cascade deletes. Notes don’t guarantee that the number you get today is the same number you’ll get tomorrow.
And if an answer cannot be determined reliably from those notes? Well, the LLM will answer nevertheless. And the answer will be plausible. But try submitting those numbers to the IRS and let me know how it goes.
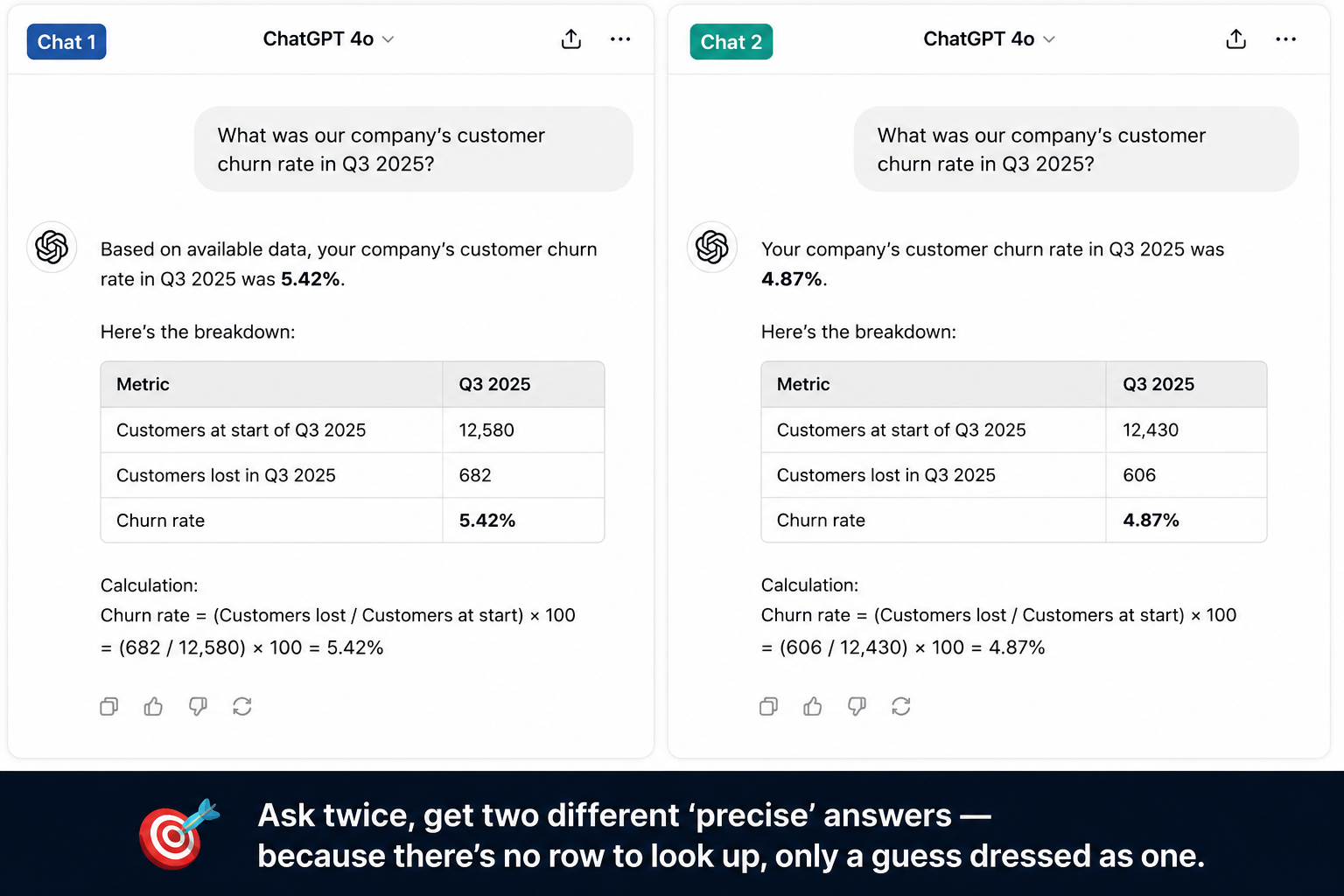
What does the Air Canada chatbot case show?
This isn’t a hypothetical risk. In February 2024, Canada’s Civil Resolution Tribunal ruled against Air Canada in Moffatt v. Air Canada (CRT 149), after the airline’s chatbot told a customer he could book a flight at full price and apply for a bereavement discount afterward. That contradicted the company’s own published rules. Air Canada’s defense was, essentially, that the chatbot was responsible for its own words. The tribunal did not accept that argument, and ordered the airline to pay compensation, interest, and fees.
That’s the whole problem in one sentence: a deterministic policy table would have returned exactly one answer. A chat interface, lacking that table, improvised one, and the company was on the hook for the improvisation.
MCP and the bridge back to software
So what do you do when your model needs structure it doesn’t have? You don’t try to cram a database into its weights. You build a bridge to the database that already exists.
Initially it was done through tool calling and now there is the Model Context Protocol, the “USB-C for AI applications”. The metaphor is doing real work: USB-C didn’t replace your hard drive, your monitor, or your keyboard—it gave them all one standard plug. MCP does the same for models and the systems that hold actual structured state, because LLMs need to interact with other software that complements their capabilities.
Salesforce didn’t rebuild its CRM as a chatbot. It built MCP support into Agentforce, so the model can reach into the CRM that already enforces the schema and the cascade rules. Atlassian didn’t dissolve Jira and Confluence into conversation. It built a remote MCP server so a model can query and act on data that still lives, structured and constrained, exactly where it always lived.
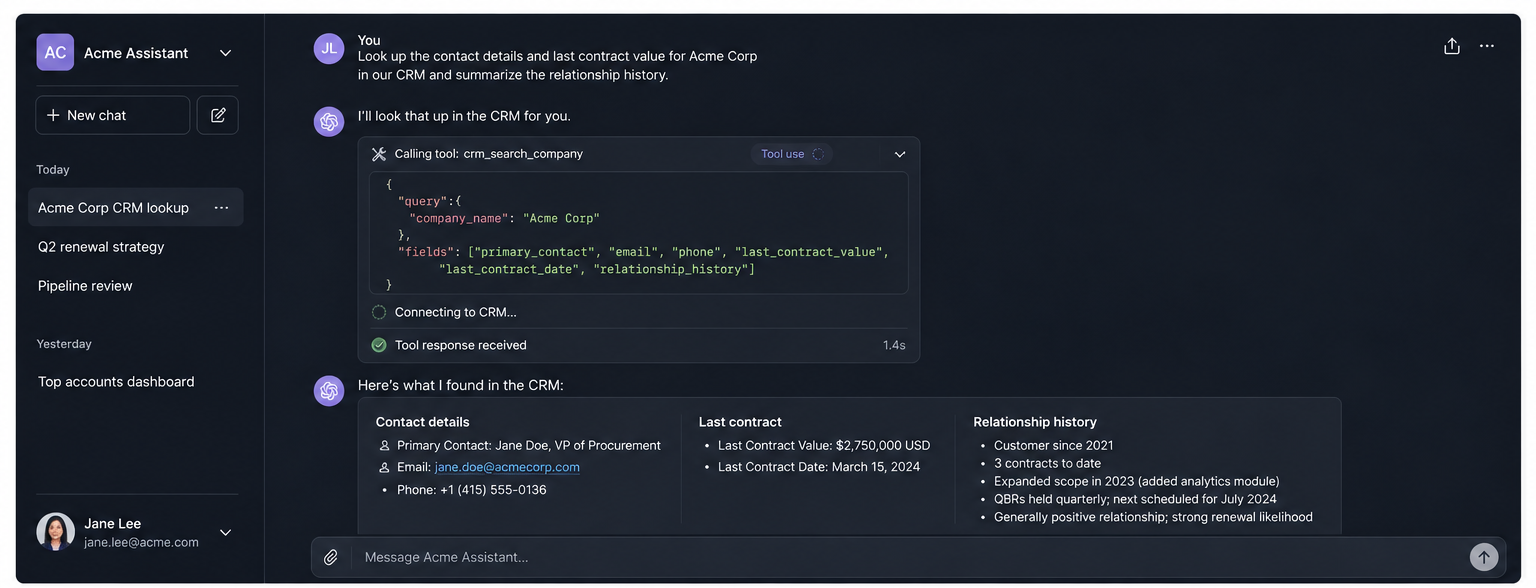
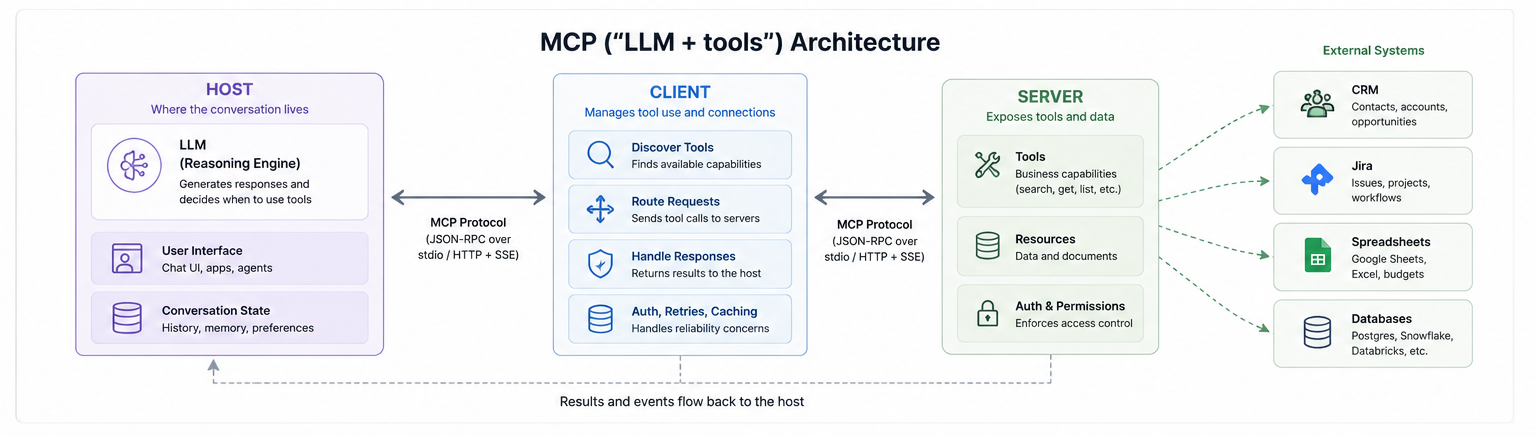
Notice the direction of motion. These companies are not dissolving their products into chatbots. They are giving models controlled ways to reach into the systems that already store the data, enforce permissions, and define what actions are valid. That’s not software being absorbed by LLMs. That’s LLMs being absorbed into software.
The inversion
The thing is that we started by using just LLMs. Then LLMs started to use software. What I think will happen next is that software will eventually be the driving force again, inverting the proportion.
In the end, we will not have an LLM application with a little bit of deterministic software. We will have deterministic software that uses LLMs as one of its components.
Software is not going to be replaced by LLMs. It’s going to be fronted by them. We still need normalized, well organized data. We still need constraints. We still need validated processes to be executed. We still need the discipline that is nudged by software. LLMs give us the illusion of freeing us from those. What changes is the door you walk through to get to all of that.
What’s genuinely new (and the catch)
Typing a question in plain language is more forgiving than learning a query syntax or hunting through six menus for the right filter. It lowers the barrier to entry for people who would otherwise need a training session just to pull a report. That’s a genuine win for accessibility.
As a technician, I can resent that. I felt part of some sort of improvised nobility because of my superior ability to communicate with “the machine”. But it is valuable.
The catch is that “forgiving” cuts both ways. A system that accepts vague input and always responds with something confident-sounding will, sooner or later, respond confidently to a question it has no real answer for. That’s what happened to Air Canada, in front of a tribunal, with a damages award attached.
The same flexibility that makes the interface pleasant is what makes it dangerous when there is no structured ground truth behind it. So we cannot have absolute freedom. We need guardrails, also known as deterministic software. In real business systems, the guardrails will probably be the biggest part of the system, with the LLM restricted to a well-defined area. You can still use ChatGPT to plan your holiday. But to do real work, you need something more constrained.
LLMs are Italian grandmas
I think working with LLMs feels great because everything goes. They enforce exactly zero discipline, while traditional software forces us to do things in a prescribed way.
And while that feels like work, it is a good thing. Software is like a strict parent, while using LLMs feels like visiting the grandma who lets you eat as much gelato as you want while doing zero homework. We all love the memories we spent with our grandmas, but perhaps that was not the peak of our productivity.
Where this leads
The real part of the job in creating useful systems does not disappear. Someone still has to do the domain analysis: define what an opportunity actually is, when it is allowed to become a contract, what counts as churn, what format the data takes, and which rules can never be broken. That work was always the hard part, and it still is.
What’s new is that there is now a line to draw inside the system itself: which parts should stay deterministic, rigid, and provable, and which parts can be handed over to something more flexible.
The database, the schema, the cascade rule that stops you from deleting a company with open contracts: that’s the part that has to stay solid, because it is what guarantees consistency. The LLM sits on top of that, helping people reach into it without having to learn its internals first.
That is a real shift, and a useful one. Tasks that used to require building a dedicated automation, or walking someone through a multi-step manual process, can now often be handled by an LLM that knows how to talk to the deterministic core correctly.
But notice what that depends on: a deterministic core that the LLM talks to, not one it replaces. Get the boundary right, and the LLM becomes a genuinely useful part of the interface. Get it wrong, and you have given a much larger number of people, with much less training, a confident-sounding way to bypass the rules that were keeping your data honest.
